
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Министерство образования и науки Российской Федерации
Новосибирский государственный университет экономики и управления «НИНХ»
Информационно-технический факультет
Кафедра прикладных информационных технологий
по дисциплине Нечеткая логика и нейронные сети
Распознавание образов
Направление: Бизнес-информатика (электронный бизнес)
Ф.И.О студента: Мазур Екатерина Витальевна
Проверил: Павлова Анна Илларионовна
Новосибирск 2016
- Введение
- 1. Понятие распознавания
- 1.1 История развития
- 1.2 Классификация методов распознавания образов
- 2. Методы распознавания образов
- 3. Общая характеристика задач распознавания образов и их типы
- 4. Проблемы и перспективы развития распознавания образов
- 4.1 Применение распознавания образов на практике
- Заключение
Введение
Достаточно продолжительное время задача распознавания образов рассматривалась только с биологической точки зрения. При этом наблюдениям подвергались лишь качественные характеристики, которые не позволяли описать механизм функционирования.
Введённое Н.Винером в начале XX века понятие кибернетика (наука об общих закономерностях процессов управления и передачи информации в машинах, живых организмах и обществе), позволила в вопросах распознавания ввести количественные методы. То есть, представить данный процесс (по сути - природное явление) математическими методами.
Теория распознавания образов является одним из основных разделов кибернетики как в теоретическом, так и в прикладном плане. Так, автоматизация некоторых процессов предполагает создание устройств, способных реагировать на изменяющиеся характеристики внешней среды некоторым количеством положительных реакций.
Базой для решения задач такого уровня являются результаты классической теории статистических решений. В ее рамках строились алгоритмы определения класса, к которому может быть отнесен распознаваемый объект.
Цель данной работы - познакомиться с понятиями теории распознавания образов: раскрыть основные определения, изучить историю возникновения, выделить основные методы и принципы теории.
Актуальность темы заключается в том, что на данный момент распознавание образов - одно из ведущих направлений кибернетики. Так, в последние годы оно находит все большее применение: оно упрощает взаимодействие человека с компьютером и создает предпосылки для применения различных систем искусственного интеллекта.
распознавание образ применение
1. Понятие распознавания
Долгое время проблема распознавания привлекала внимание только ученых области прикладной математики. В результате, работы Р. Фишера, созданные в 20-х годах , привели к формированию дискриминантного анализа - одного из разделов теории и практики распознавания образов. В 40-х годах А. Н. Колмогоровым и А. Я. Хинчиным была поставлена цель о разделении смеси двух распределений. А в 50-60-е годы ХХ века на основе большого количества работ появилась теория статистических решений. В рамках кибернетики начало складываться новое направление, связанное с разработкой теоретических основ и практической реализацией механизмов, а также систем, предназначенных для распознавания объектов и процессов. Новая дисциплина получила название "Распознавание образов".
Распознавание образов (объектов) - это задача идентификации объекта по его изображению (оптическое распознавание), аудиозаписи (акустическое распознавание) или другим характеристикам. Образ - это классификационная группировка, которая позволяет объединить группу объектов по некоторым признакам. Образы обладают характерной чертой, проявляющейся в том, что ознакомление с конечным числом явлений из одного множества дает возможность узнать большое количество его представителей. В классической постановке задачи распознавания множество разбивается на части.
Одним из базовых определений также является и понятие множества. В компьютере множество - это набор неповторяющихся однотипных элементов. "Неповторяющихся" - значит, что элемент в множестве либо есть, либо нет. Универсальное множество включает все возможные элементы, пустое не содержит ни одного.
Методика отнесения элемента к какому-то образу называется решающим правилом. Еще одно важное понятие - метрика - определяет расстояние между элементами множества. Чем меньше это расстояние, тем больше схожи объекты (символы, звуки и др.), которые мы распознаем. Стандартно элементы задаются в виде набора чисел, а метрика - в виде какой-то функции. От выбора представления образов и реализации метрики зависит эффективность работы программы: одинаковый алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на факторы внешних похожих сигналов путем их многократного воздействия на систему. Самообучение отличается от обучения тем, что здесь дополнительная информация о реакции системе не сообщается.
Примерами задач распознавания образов являются:
Распознавание букв;
Распознавание штрих-кодов;
Распознавание автомобильных номеров;
Распознавание лиц и других биометрических данных;
Распознавание речи и др..
1.1 История развития
К середине 50-х годов Р. Пенроуз ставит под сомнение нейросетевую модель мозга, указывая на существенную роль в его функционировании квантово-механических эффектов. Отталкиваясь от этого, Ф.Розенблатт разработал модель обучения распознавания зрительных образов, названную персептроном.
Рисунок 1 - Схема Персептрона
Далее были придуманы различные обобщения персептрона, и функция нейронов была усложнена: нейроны смогли не только умножать входные числа и сравнивать результат с пороговыми значениями, но и применять по отношению к ним более сложные функции. На рисунке 2 изображено одно из подобных усложнений:
Рис. 2 Схема нейронной сети.
Кроме того, топология нейронной сети могла быть еще более усложненной. Например, такой:
Рисунок 3 - Схема нейронной сети Розенблатта.
Нейронные сети, будучи сложным объектом для математического анализа, при грамотном их использовании, позволяли находить весьма простые законы данных. Но это достоинство одновременно является и источником потенциальных ошибок. Трудность для анализа, в общем случае, объясняется только сложной структурой, но, как следствие, практически неисчерпаемыми возможностями для обобщения самых различных закономерностей.
1.2 Классификация методов распознавания образов
Как мы уже отметили, распознаванием образов называются задачи установления отношений эквивалентности между определенными образами-моделями объектов реального или идеального мира.
Данные отношения определяют принадлежность распознаваемых объектов к каким-либо классам, которые рассматриваются как самостоятельные независимые единицы.
При построении алгоритмов распознавания эти классы могут задаваться исследователем, который пользуется собственными представлениями или использует дополнительную информацию о сходстве или различии объектов в контексте данной задачи. В данном случае говорят о "распознавании с учителем". В другом, т.е. когда автоматизированная система решает задачу классификации без привлечения дополнительной информации, говорят о "распознавании без учителя".
В работах В.А. Дюка дан академический обзор методов распознавания и используется два основных способа представления знаний:
Интенсиональное (в виде схемы связей между атрибутами);
Экстенсиональное с помощью конкретных фактов (объекты, примеры).
Интенсиональное представление фиксируют закономерности, которыми объясняется структура данных. Применительно к диагностическим задачам такая фиксация заключается в определении операций над признаками объектов, приводящих к нужному результату. Интенсиональные представления реализуются через операции над значениями и не предполагают проведения операций над конкретными объектами.
В свою очередь экстенсиональные представления знаний связаны с описанием и фиксацией конкретных объектов из предметной области и реализуются в операциях, элементами которых служат объекты как самостоятельные системы.
Таким образом, в основу классификации методов распознавания, предложенной В.А. Дюка, положены фундаментальные закономерности, которые лежат в основе человеческого способа познания в принципе. Это ставит данное деление на классы в особое положение по сравнению с другими менее известными классификациями, которые на этом фоне выглядят искусственными и неполными.
2. Методы распознавания образов
Метод перебора. В данном методе производится сравнение с некоторой базой данных, где для каждого из объектов представлены разные варианты модификации отображения. Например, для оптического распознавания образов можно применить метод перебора под разными углами или масштабами, смещениями, деформациями и т. д. Для букв можно перебирать шрифт или его свойства. В случае распознавания звуковых образов происходит сравнение с некоторыми известными шаблонами (слово, произнесенное многими людьми). Далее, производится более глубокий анализ характеристик образа. В случае оптического распознавания - это может быть определение геометрических характеристик. Звуковой образец в этом случае подвергается частотному и амплитудному анализу.
Следующий метод - использование искусственных нейронных сетей (ИНС). Он требует либо огромного количества примеров задачи распознавания, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Но, тем не менее, этот метод отличается высокой эффективностью и производительностью.
Методы, основанные на оценках плотностей распределения значений признаков . Заимствованы из классической теории статистических решений, в которой объекты исследования рассматриваются как реализации многомерной случайной величины, распределенной в пространстве признаков по какому-либо закону. Они базируются на байесовской схеме принятия решений, апеллирующей к начальным вероятностям принадлежности объектов к тому или иному классу и условным плотностям распределения признаков.
Группа методов, основанных на оценке плотностей распределения значений признаков, имеет непосредственное отношение к методам дискриминантного анализа. Байесовский подход к принятию решений относится к наиболее разработанным в современной статистике параметрическим методам, для которых считается известным аналитическое выражение закона распределения (нормальный закон) и требуется только оценить лишь небольшое количество параметров (векторы средних значений и ковариационные матрицы). Основными трудностями применения данного метода считается необходимость запоминания всей обучающей выборки для вычисления оценок плотностей и высокая чувствительность к обучающей выборки.
Методы, основанные на предположениях о классе решающих функций . В данной группе считается известным вид решающей функции и задан функционал ее качества. На основании этого функционала по обучающей последовательности находят оптимальное приближение к решающей функции. Функционал качества решающего правила обычно связывают с ошибкой. Основным достоинством метода является ясность математической постановки задачи распознавания.Возможность извлечения новых знаний о природе объекта, в частности знаний о механизмах взаимодействия атрибутов, здесь принципиально ограничена заданной структурой взаимодействия, зафиксированной в выбранной форме решающих функций.
Метод сравнения с прототипом . Это наиболее легкий на практике экстенсиональный метод распознавания. Он применяется, в том случае, когда распознаваемые классы показываются компактными геометрическими классами. Тогда в качестве точки - прототипа выбирается центр геометрической группировки (или ближайший к центру объект).
Для классификации неопределенного объекта находится ближайший к нему прототип, и объект относится к тому же классу, что и он. Очевидно, никаких обобщенных образов в данном методе не формируется. В качестве меры могут применяться различные типы расстояний.
Метод k ближайших соседей . Метод заключается в том, чтопри классификации неизвестного объекта находится заданное число (k) геометрически ближайших пространстве признаков других ближайших соседей с уже известной принадлежностью к какому-либо классу. Решение об отнесении неизвестного объекта принимается путем анализа информации о его ближайших соседей. Необходимость сокращения числа объектов в обучающей выборке (диагностических прецедентов) является недостатком данного метода, так как это уменьшает представительность обучающей выборки.
Исходя из того, что различные алгоритмы распознавания проявляют себя по-разному на одной и той же выборке, то встает вопрос о синтетическом решающем правиле, которое бы использовало сильные стороны всех алгоритмов. Для этого существует синтетический метод или коллективы решающих правил, которые объединяют в себе максимально положительные стороны каждого из методов.
В заключение обзора методов распознавания представим суть вышеизложенного в сводной таблице, добавив туда также некоторые другие используемые на практике методы.
Таблица 1. Таблица классификации методов распознавания, сравнения их областей применения и ограничений
|
Классификация методов распознавания |
Область применения |
Ограничения (недостатки) |
||
|
Интенсиальные методы распознавания |
Методы, основанные на оценках плотностей |
Задачи с известным распределением (нормальным), необходимость набора большой статистики |
Необходимость перебора всей обучающей выборки при распознавании, высокая чувствительность к не представительности обучающей выборки и артефактам |
|
|
Методы, основанные на предположениях |
Классы должны быть хорошо разделяемыми |
Должен быть заранее известен вид решающей функции. Невозможность учета новых знаний о корреляциях между признаками |
||
|
Логические методы |
Задачи небольшой размерности |
При отборе логических решающих правил необходим полный перебор. Высокая трудоемкость |
||
|
Лингвистические методы |
Задача определения грамматики по некоторому множеству высказываний (описаний объектов), является трудно формализуемой. Нерешенность теоретических проблем |
|||
|
Экстенсиальные методы распознавания |
Метод сравнения с прототипом |
Задачи небольшой размерности пространства признаков |
Высокая зависимость результатов классификации от метрики. Неизвестность оптимальной метрики |
|
|
Метод k ближайших соседей |
Высокая зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Вычислительная трудоемкость |
|||
|
Алгоритмы вычисления оценок (АВО) |
Задачи небольшой размерности по количеству классов и признаков |
Зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Высокая техническая сложность метода |
||
|
Коллективы решающих правил (КРП) - синтетический метод. |
Задачи небольшой размерности по количеству классов и признаков |
Очень высокая техническая сложность метода, нерешенность ряда теоретических проблем, как при определении областей компетенции частных методов, так и в самих частных методах |
3. Общая характеристика задач распознавания образов и их типы
Общая структура системы распознавания и ее этапы показаны на рисунке 4:
Рисунок 4 - Структура системы распознавания
Задачи распознавания имеют следующие характерные этапы:
Преобразование исходных данных к удобному виду для распознавания;
Распознавание (указание принадлежности объекта определенному классу).
В этих задачах можно вводить понятие подобия объектов и формулировать набор правил, на основании которых объект зачисляется в один или разные классы.
Так же можно оперировать набором примеров, классификация которых известна и которые в виде заданных описаний могут быть объявлены алгоритму распознавания для настройки на задачу в процессе обучения.
Трудности решения задач распознавания связаны с невозможностью применять без исправлений классические математические методы (часто в доступе нет информация для точной математической модели)
Выделяют следующие типы задач распознавания:
Задача распознавания - отнесение предъявленного объекта по его описанию к одному из заданных классов (обучение с учителем);
Задача автоматической классификации - разбиение множества систему непересекающихся классов (таксономия, кластерный анализ, самообучение);
Задача выбора информативного набора атрибутов при распознавании;
Задача приведения исходных данных к удобному виду;
Динамическое распознавание и классификация;
Задача прогнозирования - то есть, решение должно относиться к определенному моменту в будущем.
В существующих системах распознавания есть две наиболее сложные проблемы:
Проблема «1001 класса» - добавление 1 класса к 1000 существующим вызывает трудности с переобучением системы и проверке данных, полученных до этого;
Проблема «соотношения словаря и источников» - наиболее сильно проявляется в распознавании речи. Текущие системы могут распознавать либо большое количество слов от небольшой группы лиц, либо мало слов от большой группы лиц. Так же трудно распознавать большое количество лиц с гримом или гримасами.
Нейронные сети не решают эти задачи напрямую, однако в силу своей природы они гораздо легче адаптируются к изменениям входных последовательностей.
4. Проблемы и перспективы развития распознавания образов
4.1 Применение распознавания образов на практике
В целом проблема распознавания образов состоит из двух частей: обучения и распознавания. Обучение осуществляется путем показа независимых объектов с отнесением их к тому или другому классу. По итогу обучения распознающая система должна приобрести способность реагировать одинаковыми реакциями на все объекты одного образа и различными - на все другие. Важно, что в процессе обучения указываются только сами объекты и их принадлежность образу. За обучением следует процесс распознавания, который характеризует действия уже обученной системы. Автоматизация этих процедур и составляет проблему.
Прежде чем начать анализ какого-либо объекта, нужно получить о нем определенную, каким-либо способом упорядоченную, точную информацию. Такая информация представляет собой совокупность свойств объектов, их отображение на множестве воспринимающих органов распознающей системы.
Но каждый объект наблюдения может воздействовать по-разному, в зависимости от условий восприятия. Кроме того, объекты одного и того же образа могут сильно отличаться друг от друга.
Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы. При удачном выборе исходного описания (пространства признаков) задача распознавания может оказаться достаточно легкой и, наоборот, неудачно выбранное может привести к очень сложной дальнейшей переработке информации, либо вообще к отсутствию решения.
Распознавание объектов, сигналов, ситуаций, явлений - самая часто встречающаяся задача, которую человеку необходимо решать ежесекундно. Для этого используются огромные ресурсы мозга, который оценивается таким показателем как число нейронов, равное 10 10 .
Также, распознавание постоянно встречается в технике. Вычисления в сетях формальных нейронов, во многом напоминают обработку информации мозгом. В последнее десятилетие нейрокомпьютинг приобрел чрезвычайную популярность и успел превратиться в инженерную дисциплину, связанную с производством коммерческих продуктов. В большом объеме ведутся работы по созданию элементной базы для нейровычислений.
Основной их характерной чертой является способность решать неформализованные проблемы, для которых в силу тех или иных причин не предполагается алгоритмов решения. Нейрокомпьютеры предлагают относительно простую технологию получения алгоритмов путем обучения. В этом их основное преимущество. Поэтому нейрокомпьютинг оказывается актуальным именно сейчас - в период расцвета мультимедиа, когда глобальное развитие требует разработки новых технологий, тесно связанных с распознаванием образов.
Одной из основных проблем развития и применения искусственного интеллекта остаётся проблема распознавания звуковых и визуальных образов. Все остальные технологии уже готовы к тому, чтобы найти своё применение в медицине, биологии, системах безопасности. В медицине распознавание образов помогает врачам ставить более точные диагнозы, на заводах оно используется для прогноза брака в партиях товаров. Системы биометрической идентификации личности в качестве своего алгоритмического ядра так же основаны на результатах распознавания. Дальнейшее развитие и проектирование компьютеров, способных к более непосредственному общению с человеком на естественных для людей языках и посредством речи, нерешаемы без распознавания. Здесь уже встает вопрос о развитии робототехники, искусственных систем управления, содержащих в качестве жизненно важных подсистем системы распознавания.
Заключение
В результате работы был сделан краткий обзор основных определений понятий такого раздела кибернетики как распознавание образов, выделены методы распознавания, сформулированы задачи.
Безусловно, существует множество направлений по развитию данной науки. К тому же, как было сформулировано в одной из глав, распознавание - одно из ключевых направлений развития на данный момент. Так, программное обеспечение в ближайшие десятилетия может стать ещё более привлекательным для пользователя и конкурентоспособным на современном рынке, если приобретет коммерческий формат и начнет распространяться в рамках большого количества потребителей.
Дальнейшие исследования могут быть направлены на следующие аспекты: глубокий анализ основных методов обработки и разработка новых комбинированных или модифицированных методов для распознавания. На основании проведенных исследований можно будет разработать функциональную систему распознавания, с помощью которой возможно проверить выбранные методы распознавания на эффективность.
Список литературы
1. Дэвид Формайс, Жан Понс Компьютерное зрение. Современный подход, 2004
2. Айзерман М.А., Браверман Э.М., Розоноэр Л.И. Метод потенциальных функций в теории обучения машин. - М.: Наука, 2004.
3. Журавлев Ю.И. Об алгебраическом подходе к решению задач распознавания или классификации // Проблемы кибернетики. М.: Наука, 2005. - Вып. 33.
4. Мазуров В.Д. Комитеты систем неравенств и задача распознавания // Кибернетика, 2004, № 2.
5. Потапов А.С. Распознавание образов и машинное восприятие. - С-Пб.: Политехника, 2007.
6. Минский М., Пейперт С. Персептроны. - М.: Мир, 2007.
7. Растригин Л. А., Эренштейн Р. Х. Метод коллективного распознавания. М. Энергоиздат, 2006.
8. Рудаков К.В. Об алгебраической теории универсальных и локальных ограничений для задач классификации // Распознавание, классификация, прогноз. Математические методы и их применение. Вып. 1. - М.: Наука, 2007.
9. Фу К. Структурные методы в распознавании образов. - М.: Мир, 2005.
Размещено на Allbest.ru
...Подобные документы
Основные понятия теории распознавания образов и ее значение. Сущность математической теории распознавания образов. Основные задачи, возникающие при разработке систем распознавания образов. Классификация систем распознавания образов реального времени.
курсовая работа , добавлен 15.01.2014
Понятие и особенности построения алгоритмов распознавания образов. Различные подходы к типологии методов распознавания. Изучение основных способов представления знаний. Характеристика интенсиональных и экстенсиональных методов, оценка их качества.
презентация , добавлен 06.01.2014
Теоретические основы распознавания образов. Функциональная схема системы распознавания. Применение байесовских методов при решении задачи распознавания образов. Байесовская сегментация изображений. Модель TAN при решении задачи классификации образов.
дипломная работа , добавлен 13.10.2017
Обзор задач, возникающих при разработке систем распознавания образов. Обучаемые классификаторы образов. Алгоритм персептрона и его модификации. Создание программы, предназначенной для классификации образов методом наименьшей среднеквадратической ошибки.
курсовая работа , добавлен 05.04.2015
Методы распознавания образов (классификаторы): байесовский, линейный, метод потенциальных функций. Разработка программы распознавания человека по его фотографиям. Примеры работы классификаторов, экспериментальные результаты о точности работы методов.
курсовая работа , добавлен 15.08.2011
Создание программного средства, осуществляющего распознавание зрительных образов на базе искусственных нейронных сетей. Методы, использующиеся для распознавания образов. Пандемониум Селфриджа. Персептрон Розенблатта. Правило формирования цепного кода.
дипломная работа , добавлен 06.04.2014
Распознавание образов - задача идентификации объекта или определения его свойств по его изображению или аудиозаписи. История теоретических и технических изменений в данной области. Методы и принципы, применяемые в вычислительной технике для распознавания.
реферат , добавлен 10.04.2010
Понятие системы распознавания образов. Классификация систем распознавания. Разработка системы распознавания формы микрообъектов. Алгоритм для создания системы распознавания микрообъектов на кристаллограмме, особенности его реализации в программной среде.
курсовая работа , добавлен 21.06.2014
Выбор типа и структуры нейронной сети. Подбор метода распознавания, структурная схема сети Хопфилда. Обучение системы распознавания образов. Особенности работы с программой, ее достоинства и недостатки. Описание интерфейса пользователя и экранных форм.
курсовая работа , добавлен 14.11.2013
Появление технических систем автоматического распознавания. Человек как элемент или звено сложных автоматических систем. Возможности автоматических распознающих устройств. Этапы создания системы распознавания образов. Процессы измерения и кодирования.
Мотивация
Рассмотрим такую задачу. У нас есть яблоки двух классов - вкусные и не вкусные, 1 и 0. Яблоки обладают признаками - цветом и размером. Цвет изменятся непрерывно от 0 до 1, т.е. 0 -полностью зеленое яблоко, 1 - полностью красное. Размер может меняться аналогично, 0 - яблоко маленькое, 1 - большое. Мы хотели бы разработать алгоритм, который бы получал на вход цвет и размер, а на выходе отдавал класс яблока - вкусное оно или нет. Весьма желательно, чтобы число ошибок при этом было чем меньше тем лучше. При этом мы обладаем конечным списком, в котором указаны исторические данные о цвете, размере и классе яблок. Как бы мы могли решать такую задачу?Логический подход
Решая нашу задачу, первый метод, который возможно придет на ум, может быть такой: давайте вручную составим правила типа if-else и в зависимости от значений цвета и размера будем присваивать яблоку определенный класс. Т.е. у нас есть предпосылки - это цвет и размер, и есть следствие - вкус яблока. Вполне разумно, когда признаков немного и можно на глаз оценить пороги для сравнения. Но может случится так, что придумать четкие условия не получится, и из данных не очевидно какие пороги брать, да и число признаков может увеличиваться в перспективе. А что делать, если в нашем списке с историческими данными, мы обнаружили два яблока с одинаковыми цветом и размером, но одно помечено как вкусное, а другое нет? Таким образом наш первый метод не настолько гибкий и масштабируемый, как нам бы хотелось.Обозначения
Введем следующую нотацию. Будем обозначать -ое яблоко как . В свою очередь каждый состоит из двух чисел - цвета и размера. Этот факт мы будем обозначать парой чисел: . Класс каждого -го яблока мы обозначим как . Список с историческими данными обозначим буквой , длина этого списка равна . -ый элемент этого списка есть значение признаков яблока и его класс. Т.е. . Так же будем называть выборкой. Большими буквами и мы обозначим переменные, которые могут принимать значения конкретного признака и класса. Веедем новое понятие - решающее правило есть функция, которая принимает на вход значение цвета и размера , а на выходе возвращает метку класса:Вероятностный подход
Развивая идею логического метода с предпосылками и следствиями, зададим себе вопрос - а какова вероятность того, что -ое яблоко, которое не принадлежит нашей выборке будет вкусное, при условии измеренных значений цвета и размера? В нотации теории вероятностей этот вопрос можно записать так:В этом выражении можно интерпретировать как посылку, как следствие, но переход от посылки к следствию будет подчинятся вероятностным законам, а не логическим. Т.е. вместо таблицы истинности с булевскими значениями 0 и 1 для класса, будут значения вероятности, которые принимают значения от 0 до 1. Применим формулу Байеса и получим следующее выражение:
Рассмотрим правую часть этого выражения более подробно. Множитель называется априорной вероятностью и означает вероятность встретить вкусное яблоко среди всех возможных яблок. Априорная вероятность встретить невкусное яблоко есть . Эта вероятность может отражать наше личное знание о том, как распределены вкусные и невкусные яблоки в природе. Например, по нашему прошлому опыту мы знаем, что 80% всех яблок - вкусные. Или мы можем оценить это значение просто посчитав долю вкусных яблок в нашем списке с историческими данными S. Следующий множитель - показывает, насколько вероятно получить конкретное значение цвета и размера для яблока класса 1. Это выражение так же называется функцией правдоподобия и может иметь вид какого-нибудь конкретного распределения, например, нормального. Знаменатель мы используем в качестве нормировочной константы, что бы искомая вероятность изменялась в пределах от 0 до 1. Нашей конечной целью является не поиск вероятностей, а поиск решающего правила, которое бы сразу давало нам класс. Конечный вид решающего правила зависит от того, какие значения и параметры нам известны. Например, мы можем знать только значения априорной вероятности, а остальные значения оценить невозможно. Тогда решающее правило будет такое - ставить всем яблокам значение того класса, для которого априорная вероятность наибольшая. Т.е. если мы знаем, что 80% яблок в природе вкусные, то каждому яблоку ставим класс 1. Тогда наша ошибка составит 20%. Если же мы к тому же можем оценить значения функции правдоподобия $p(X=x_m | Y=1)$, то можем и найти значение искомой вероятности по формуле Байеса, как написано сверху. Решающее правило здесь будет таким: поставить метку того класса, для которого вероятность максимальна:
Это правило назовем Байесовским классификатором. Поскольку мы имеем дело с вероятностями, то даже большое значение вероятности не дает гарантий, что яблоко не принадлежит к классу 0. Оценим вероятность ошибки на яблоке следующим образом: если решающее правило вернуло значение класса равное 1, то вероятность ошибиться будет и наоборот:
Нас интересует вероятность ошибки классификатора не только на данном конкретном примере, но и вообще для всех возможных яблок:
Это выражение является математическим ожидаем ошибки . Итак, решая исходную проблему мы пришли к байесовскому классификатору, но какие у него есть недостатки? Главная проблема - оценить из данных условную вероятность . В нашем случае мы представляем объект парой чисел - цвет и размер, но в более сложных задачах размерность признаков может быть в разы выше и для оценки вероятности многомерной случайной величины может не хватить числа наблюдений из нашего списка с историческими данными. Далее мы попробуем обобщить наше понятие ошибки классификатора, а так же посмотрим, можно ли подобрать какой-либо другой классификатор для решения проблемы.
Потери от ошибок классификатора
Предположим, что у нас уже есть какое-либо решающее правило . Тогда оно может совершить два типа ошибок - первый, это причислить объект к классу 0, у которого реальный класс 1 и наоборот, причислить объект к классу 1, у которого реальный класс 0. В некоторых задачах бывает важно различать эти случаи. Например, мы страдаем больше от того, что яблоко, помеченное как вкусное, оказалось невкусным и наоборот. Степень нашего дискомфорта от обманутых ожиданий мы формализуем в понятии Более обще - у нас есть функция потерь, которая возвращает число для каждой ошибки классификатора. Пусть - реальная метка класса. Тогда функция потерь возвращает величину потерь для реальной метки класса и значения нашего решающего правила . Пример применения этой функции - берем из яблоко с известным классом , передаем яблоко на вход нашему решающему правилу , получаем оценку класса от решающего правила, если значения и совпали, то считаем что классификатор не ошибся и потерь нет, если значения не совпадают, то величину потерь скажет наша функцияУсловный и байесовский риск
Теперь, когда у нас есть функция потерь и мы знаем, сколько мы теряем от неправильной классификации объекта , было бы неплохо понять, сколько мы теряем в среднем, на многих объектах. Если мы знаем величину - вероятность того, что -ое яблоко будет вкусное, при условии измеренных значений цвета и размера, а так же реальное значение класса(например возьмем яблоко из выборки S, см. в начале статьи), то можем ввести понятие условного риска. Условный риск есть средняя величина потерь на объекте для решающего правила :В нашем случае бинарной классификации когда получается:
Выше мы описывали решающее правило, которое относит объект к тому классу, который имеет наибольшее значение вероятности Такое правило доставляет минимум нашим средним потерям(байесовскому риску), поэтому Байесовский классификатор является оптимальным с точки зрения введенного нами функционала риска. Это значит, что Байесовский классификатор имеет наименьшую возможную ошибку классификации.
Некоторые типовые функции потерь
Одной из наиболее частовстречающихся функций потерь является симметричная функция, когда потери от первого и второго типов ошибок равнозначны. Например, функция потерь 1-0 (zero-one loss) определяется так:Тогда условный риск для a(x) = 1 будет просто значением вероятности получить класс 0 на объектке :
Аналогично для a(x) = 0:
Функция потерь 1-0 принимает значение 1, если классификатор делает ошибку на объекте и 0 если не делает. Теперь сделаем так, чтобы значение на ошибке равнялось не 1, а другой функции Q, зависящей от решающего правила и реальной метки класса:
Тогда условный риск можно записать так:
Замечания по нотации
Предыдущий текст был написан согласно нотации, принятой в книге Дуды и Харта. В оригинальной книге В.Н. Вапника рассматривался такой процесс: природа выбирает объект согласно распределению $p(x)$, а затем ставит ему метку класса согласно условному распределению $p(y|x)$. Тогда риск(матожидание потерь) определяется какГде - функция, которой мы пытаемся аппроксимировать неизвестную зависимость, - функция потерь для реального значения и значения нашей функции . Эта нотации более наглядна для того чтобы ввести следущее понятие - эмпирический риск.
Эмпирический риск
На данном этапе мы уже выяснили, что логический метод нам не подходит, потому что он недостаточно гибкий, а байесовский классификатор мы не можем использовать, когда признаков много, а данных для обучения ограниченное число и мы не сможем восстановить вероятность . Так же нам известно, что байесовский классификатор обладает наименьшей возможной ошибкой классификации. Раз уж мы не можем использовать байесовский классификатор, давайте возьмем что-нибудь по проще. Давайте зафиксируем некоторое параметрическое семейство функций H и будем подбирать классификатор из этого семейства.Пример: пусть множество всех функций вида
Все функции этого множества будут отличаться друг от друга только коэффициентами Когда мы выбрали такое семейство, мы предположили, что в координатах цвет-размер между точками класса 1 и точками класса 0 можно провести прямую линию с коэффициентами таким образом, что точки с разными классами находятся по разные стороны от прямой. Известно, что у прямой такого вида вектор коэффициентов является нормалью к прямой. Теперь делаем так - берем наше яблоко, меряем у него цвет и размер и наносим точку с полученными координатами на график в осях цвет-размер. Далее меряем угол между этой точкой и вектором $w$. Замечаем, что наша точка может лежать либо по одну, либо по другую сторону от прямой. Тогда угол между и точкой будет либо острый, либо тупой, а скалярное произведение либо положительное, либо отрицательное. Отсюда вытекает решающее правило:
После того как мы зафиксировали класс функций $Н$, возникает вопрос - как выбрать из него функцию с нужными коэффициентами? Ответ - давайте выберем ту функцию, которая доставляет минимум нашему байесовскому риску $R()$. Опять проблема - чтобы посчитать значения байесовского риска, нужно знать распределение $p(x,y)$, а оно нам не дано, и восстановиь его не всегда возможно. Другая идея - минимизировать риск не на всех возможных объектах, а только на выборке. Т.е. минимизировать функцию:
Эта функция и называется эмпирическим риском. Следующий вопрос - почему мы решили, что минимизируя эмпирический риск, мы при этом так же минимизируем байесовский риск? Напомню, что наша задача практическая - допустить как можно меньше ошибок классификации. Чем меньше ошибок, тем меньше байесовский риск. Обоснование о сходимости эмпирического риска к байесовскому с ростом объема данных было получено в 70-е годы двумя учеными - В. Н. Вапником и А. Я. Червоненкисом.
Гарантии сходимости. Простейший случай
Итак, мы пришли к тому, что байесовский классификатор дает наименьшую возможною ошибку, но обучить его в большинстве случаев мы не можем и ошибку(риск) посчитать мы тоже не в силах. Однако, мы можем посчитать приближение к байесовскокому риску, которое называется эмпирический риск, а зная эмпирический риск подобрать такую аппроксимирующую функцию, которая бы минимизировала эмпирический риск. Давайте рассмотрим простейшую ситуацию, когда минимизация эмпирического риска дает классификатор, так же минимизирующий байесовский риск. Для простейшего случая нам придется сделать предположение, которое редко выполняется на практике, но которое в дальнейшем можно будет ослабить. Зафиксируем конечный класс функций из которого мы будем выбирать наш классификатор и предположим, что настоящая функция, которую использует природа для разметки наших яблок на вкусы находится в этом конечном множестве гипотез: . Так же у нас есть выборка , полученная из распределения над объектами . Все объекты выборки считаем одинаково независимо распределенными(iid). Тогда будет верна следующаяТеорема
Выбирая функцию из класса с помощью минимизации эмпирического риска мы гарантированно найдем такую , что она имеет небольшое значение байесовского риска если выборка, на которой мы производим минимизацию имеет достаточный размер.Что значит «небольшое значение» и «достаточный размер» см. в литературе ниже.
Идея доказательства
По условию теоремы мы получаем выборку из распределения , т.е. процесс выбора объектов из природы случаен. Каждый раз, когда мы собираем выборку она будет из того же распределения, но сами объекты в ней могут быть различны. Главная идея доказательства состоит в том, что мы можем получить такую неудачную выборку , что алгоритм, который мы выберем с помощью минимизации эмпирического риска на данной выборке будет плохо минимизировать байесовский риск но при этом хорошо минимизировать эмпирический риск, но вероятность получить такую выборку мала и ростом размера выборки эта вероятность падает. Подобные теоремы существуют и для более реалистичных предположений, но здесь мы не будем их рассматривать.Практические результаты
Имея доказательства того, что функция, найденная при минимизации эмпирического риска не будет иметь большую ошибку на ранее не наблюдаемых данных при достаточном размере обучающей выборки мы можем использовать этот принцип на практике, например, следующим образом - берем выражение:И подставляем разные функции потерь, в зависимости от решаемой задачи. Для линейной регрессии:
Для логистической регресии:
Несмотря на то, что за методом опорных векторов лежит в основном геометрическая мотивация, его так же можно представить как проблему минимизации эмпирического риска.
Заключение
Многие методы обучения с учителем можно рассматривать в том числе как частные случаи теории, разработанной В. Н. Вапником и А. Я. Червоненкисом. Эта теория дает гарантии относительно ошибки на тестовой выборке при условии достаточного размера обучающей выборки и некоторых требований к пространству гипотез, в котором мы ищем наш алгоритм.Используемая литература
- The Nature of Statistical Learning Theory, Vladimir N. Vapnik
- Pattern Classification, 2nd Edition, Richard O. Duda, Peter E. Hart, David G. Stork
- Understanding Machine Learning: From Theory to Algorithms, Shai Shalev-Shwartz, Shai Ben-David
Теги: Добавить метки
В целом, можно выделить три метода распознавания образов: Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
Второй подход - производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
Следующий метод - использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность.
4. История распознавания образов
Рассмотрим кратко математический формализм распознавания образов. Объект в распознавании образов описывается совокупностью основных характеристик (признаков, свойств). Основные характеристики могут иметь различную природу: они могут браться из упорядоченного множества типа вещественной прямой, либо из дискретного множества (которое, впрочем, так же может быть наделено структурой). Такое понимание объекта согласуется как потребностью практических приложений распознавания образов, так и с нашим пониманием механизма восприятия объекта человеком. Действительно, мы полагаем, что при наблюдении (измерении) объекта человеком, сведения о нем поступают по конечному числу сенсоров (анализируемых каналов) в мозг, и каждому сенсору можно сопоставить соответствующую характеристику объекта. Помимо признаков, соответствующих нашим измерениям объекта, существует так же выделенный признак, либо группа признаков, которые мы называем классифицирующими признаками, и в выяснении их значений при заданном векторе Х и состоит задача, которую выполняют естественные и искусственные распознающие системы.
Понятно, что для того, чтобы установить значения этих признаков, необходимо иметь информацию о том, как связаны известные признаки с классифицирующими. Информация об этой связи задается в форме прецедентов, то есть множества описаний объектов с известными значениями классифицирующих признаков. И по этой прецедентной информации и требуется построить решающее правило, которое будет ставить произвольному описанию объекта значения его классифицирующих признаков.
Такое понимание задачи распознавания образов утвердилось в науке начиная с 50-х годов прошлого века. И тогда же было замечено что такая постановка вовсе не является новой. С подобной формулировкой сталкивались и уже существовали вполне не плохо зарекомендовавшие себя методы статистического анализа данных, которые активно использовались для многих практических задач, таких как например, техническая диагностика. Поэтому первые шаги распознавания образов прошли под знаком статистического подхода, который и диктовал основную проблематику.
Статистический подход основывается на идее, что исходное пространство объектов представляет собой вероятностное пространство, а признаки (характеристики) объектов являют собой случайные величины заданные на нем. Тогда задача исследователя данных состояла в том, чтобы из некоторых соображений выдвинуть статистическую гипотезу о распределении признаков, а точнее о зависимости классифицирующих признаков от остальных. Статистическая гипотеза, как правило, представляла собой параметрически заданное множество функций распределения признаков. Типичной и классической статистической гипотезой является гипотеза о нормальности этого распределения (разновидностей таких гипотез статистики придумали великое множество). После формулировки гипотезы оставалось проверить эту гипотезу на прецедентных данных. Это проверка состояла в выборе некоторого распределения из первоначально заданного множества распределений (параметра гипотезы о распределении) и оценки надежности(доверительного интервала) этого выбора. Собственно эта функция распределения и была ответом к задаче, только объект классифицировался уже не однозначно, но с некоторыми вероятностями принадлежности к классам. Статистиками были разработано так же и ассимптотическое обоснование таких методов. Такие обоснования делались по следующей схеме: устанавливался некоторый функционал качества выбора распределения (доверительный интервал) и показывалось, что при увеличении числа прецедентов, наш выбор с вероятностью стремящейся к 1 становился верным в смысле этого функционала (доверительный интервал стремился к 0). Забегая вперед скажем, что статистический взгляд на проблему распознавания оказался весьма плодотворным не только в смысле разработанных алгоритмов (в число которых входят методы кластерного, дискриминантного анализов, непараметрическая регрессия и т.д.), но и привел впоследствии Вапника к созданию глубокой статистической теории распознавания.
Тем не менее существует серьезная аргументация в пользу того, что задачи распознавания образов не сводятся к статистике. Любую такую задачу, в принципе, можно рассматривать со статистической точки зрения и результаты ее решения могут интерпретироваться статистически. Для этого необходимо лишь предположить, что пространство объектов задачи является вероятностным. Но с точки зрения инструментализма, критерием удачности статистической интерпретации некоторого метода распознавания может служить лишь наличие обоснавания этого метода на языке статистики как раздела математики. Под обоснаванием здесь понимается выработка основных требований к задаче которые обеспечивают успех в применении этого метода. Однако на данный момент для большей части методов распознавания, в том числе и для тех, которые напрямую возникли в рамках статистического подхода, подобных удовлетворительных обоснований не найдено. Кроме этого, наиболее часто применяемые на данный момент статистические алгоритмы, типа линейного дискриминанта Фишера, парзеновского окна, EM-алгоритма, метода ближайших соседей, не говоря уже о байесовских сетях доверия, имеют сильно выраженный эвристический характер и могут иметь интерпретации отличные от статистических. И наконец, ко всему вышесказанному следует добавить, что помимо асимптотического поведения методов распознавания, которое и является основным вопросом статистики, практика распознавания ставит вопросы вычислительной и структурной сложности методов, которые выводят далеко за рамки одной лишь теории вероятностей.
Итого, вопреки стремлениям статистиков рассматривать распознавание образов как раздел статистики, в практику и идеологию распознавания входили совершенно другие идеи. Одна из них была вызвана исследованиями в области распознавания зрительных образов и основана на следующей аналогии.
Как уже отмечалось, в повседневной жизни люди постоянно решают (зачастую бессознательно) проблемы распознавания различных ситуаций, слуховых и зрительных образов. Подобная способность для ЭВМ представляет собой в лучшем случае дело будущего. Отсюда некоторыми пионерами распознавания образов был сделан вывод, что решение этих проблем на ЭВМ должно в общих чертах моделировать процессы человеческого мышления. Наиболее известной попыткой подойти к проблеме с этой стороны было знаменитое исследование Ф. Розенблатта по перцептронам .
К середине 50-х годов казалось, что нейрофизиологами были поняты физические принципы работы мозга (в книге "Новый Разум Короля" знаменитый британский физик-теоретик Р. Пенроуз интересно ставит под сомнение нейросетевую модель мозга, обосновывая существенную роль в его функционировании квантово-механических эффектов; хотя, впрочем, эта модель подвергалась сомнению с самого начала. Отталкиваясь от этих открытий Ф.Розенблатт разработал модель обучения распознаванию зрительных образов, названную им персептроном. Персептрон Розенблатта представляет собой следующую функцию (рис. 1):
Рис 1. Схема Персептрона
На входе персептрон получает вектор объекта, который в работах Розенблатта представлял собой бинарный вектор, показывавший какой из пикселов экрана зачернен изображением а какой нет. Далее каждый из признаков подается на вход нейрона, действие которого представляет собой простое умножение на некоторый вес нейрона. Результаты подаются на последний нейрон, который их складывает и общую сумму сравнивает с некоторым порогом. В зависимости от результатов сравнения входной объект Х признается нужным образом либо нет. Тогда задача обучения распознаванию образов состояла в таком подборе весов нейронов и значения порога, чтобы персептрон давал на прецедентных зрительных образах правильные ответы. Розенблатт полагал, что получившаяся функция будет неплохо распознавать нужный зрительный образ даже если входного объекта и не было среди прецедентов. Из бионических соображений им так же был придуман и метод подбора весов и порога, на котором останавливаться мы не будем. Скажем лишь, что его подход оказался успешным в ряде задач распознавания и породил собой целое направление исследований алгоритмов обучения основанных на нейронных сетях, частным случаем которых и является персептрон.
Далее были придуманы различные обобщения персептрона, функция нейронов была усложнена: нейроны теперь могли не только умножать входные числа или складывать их и сравнивать результат с порогами, но применять по отношению к ним более сложные функции. На рисунке 2 изображено одно из подобных усложнений нейрона:

Рис. 2 Схема нейронной сети.
Кроме того топология нейронной сети могла быть значительно сложнее той, что рассматривал Розенблатт, например такой:
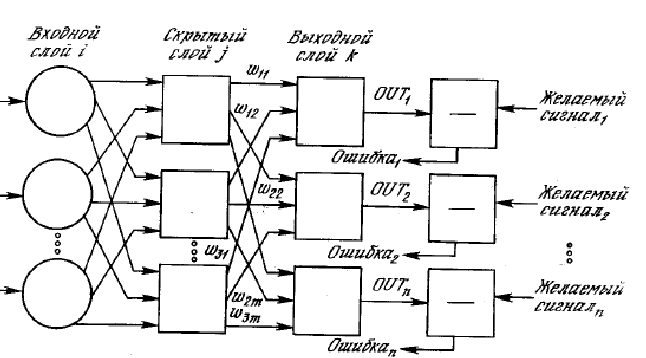
Рис. 3. Схема нейронной сети Розенблатта.
Усложнения приводили к увеличению числа настраиваемых параметров при обучении, но при этом увеличивали возможность настраиваться на очень сложные закономерности. Исследования в этой области сейчас идут по двум тесно связанным направлениям - изучаются и различные топологии сетей и различные методы настроек.
Нейронные сети на данный момент являются не только инструментом решения задач распознавания образов, но получили применение в исследованиях по ассоциативной памяти, сжатию изображений. Хотя это направление исследований и пересекается сильно с проблематикой распознавания образов, но представляет собой отдельный раздел кибернетики. Для распознавателя на данный момент, нейронные сети не более чем очень специфически определенное, параметрически заданное множество отображений, которое в этом смысле не имеет каких-либо существенных преимуществ над многими другим подобными моделями обучения которые далее будут кратко перечислены.
В связи с данной оценкой роли нейронных сетей для собственно распознавания (то есть не для бионики, для которой они имеют первостепенное значение уже сейчас) хотелось бы отметить следующее: нейронные сети, будучи чрезвычайно сложным объектом для математического анализа, при грамотном их использовании, позволяют находить весьма нетривиальные законы в данных. Их трудность для анализа, в общем случае, объясняется их сложной структурой и как следствие, практически неисчерпаемыми возможностями для обобщения самых различных закономерностей. Но эти достоинства, как это часто и бывает, являются источником потенциальных ошибок, возможности переобучения. Как будет рассказано далее, подобный двоякий взгляд на перспективы всякой модели обучения является одним из принципов машинного обучения.
Еще одним популярным направлением в распознавании являются логические правила и деревья решений. В сравнении с вышеупомянутыми методами распознавания эти методы наиболее активно используют идею выражения наших знаний о предметной области в виде, вероятно самых естественных (на сознательном уровне) структур - логических правил. Под элементарным логическим правилом подразумевается высказывание типа «если неклассифицируемые признаки находятся в соотношении X то классифицируемые находятся в соотношении Y». Примером такого правила в медицинской диагностике служит следующее: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Для поиска логических правил в данных необходимы 2 вещи: определить меру «информативности» правила и пространство правил. И задача поиска правил после этого превращается в задачу полного либо частичного перебора в пространстве правил с целью нахождения наиболее информативных из них. Определение информативности может быть введено самыми различными способами и мы не будем останавливаться на этом, считая что это тоже некоторый параметр модели. Пространство же поиска определяется стандартно.
После нахождения достаточно информативных правил наступает фаза «сборки» правил в конечный классификатор. Не обсуждая глубоко проблемы которые здесь возникают (а их возникает немалое количество) перечислим 2 основных способа «сборки». Первый тип - линейный список. Второй тип – взвешенное голосование, когда каждому правилу ставится в соответствие некоторый вес, и объект относится классификатором к тому классу за который проголосовало наибольшее количество правил.
В действительности, этап построения правил и этап «сборки» выполняются сообща и, при построении взвешенного голосования либо списка, поиск правил на частях прецедентных данных вызывается снова и снова, чтобы обеспечить лучшее согласование данных и модели.
- Tutorial
Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ - много времени, которого часто нет, становится всё ещё печальнее.
Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке.
Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста - это принципиально разные объекты. Наверное, можно сделать общий алгоритм( хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV - это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV - это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование - это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:

Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды . А можно выбрать наибольший пик гистограммы.

Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.


Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее - БПФ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, - компрессия изображений . Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование .
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.


Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:


Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование ". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара , вейвлет Морле , вейвлет мексиканская шляпа , и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей ( , ), относятся к таким функциям для двумерного пространства.



Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:

Классические вейвлеты обычно используются для , или для их классификации (будет описано ниже).
Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение - корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига - тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют - было движение.


Фильтрации функций
Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:
(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности . Есть модифицированное преобразование, которое позволяет искать любые . Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Фильтрации контуров
Отдельный класс фильтров - фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров:Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).


Прочие фильтры
Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например ), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:
Но эти преобразования весьма специфичны и заточены под редкие задачи.
Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.Морфология
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии ( , ). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.
Контурный анализ
В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука .Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом ( , ).

Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях - то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица - это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это и . Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр по этой тематике, там очень хорошая подборка. Вот оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений - это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д… Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка . Для обезьяны точка для лошади . Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5




Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот немножко красивых картинок на тему.
Простой случай, одномерное разделение
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя - получается левая гауссиана. Когда не похож - правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график - это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
) АдаБуста - один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM ( , , , ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок
Что почитать?1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами.
2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок.
3) «Обработка и анализ изображений в задачах машинного зрения» - написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание - wiki.technicalvision.ru Добавить метки
Метод перебора. В данном методе производится сравнение с некоторой базой данных, где для каждого из объектов представлены разные варианты модификации отображения. Например, для оптического распознавания образов можно применить метод перебора под разными углами или масштабами, смещениями, деформациями и т. д. Для букв можно перебирать шрифт или его свойства. В случае распознавания звуковых образов происходит сравнение с некоторыми известными шаблонами (слово, произнесенное многими людьми). Далее, производится более глубокий анализ характеристик образа. В случае оптического распознавания - это может быть определение геометрических характеристик. Звуковой образец в этом случае подвергается частотному и амплитудному анализу.
Следующий метод - использование искусственных нейронных сетей (ИНС). Он требует либо огромного количества примеров задачи распознавания, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Но, тем не менее, этот метод отличается высокой эффективностью и производительностью.
Методы, основанные на оценках плотностей распределения значений признаков . Заимствованы из классической теории статистических решений, в которой объекты исследования рассматриваются как реализации многомерной случайной величины, распределенной в пространстве признаков по какому-либо закону. Они базируются на байесовской схеме принятия решений, апеллирующей к начальным вероятностям принадлежности объектов к тому или иному классу и условным плотностям распределения признаков.
Группа методов, основанных на оценке плотностей распределения значений признаков, имеет непосредственное отношение к методам дискриминантного анализа. Байесовский подход к принятию решений относится к наиболее разработанным в современной статистике параметрическим методам, для которых считается известным аналитическое выражение закона распределения (нормальный закон) и требуется только оценить лишь небольшое количество параметров (векторы средних значений и ковариационные матрицы). Основными трудностями применения данного метода считается необходимость запоминания всей обучающей выборки для вычисления оценок плотностей и высокая чувствительность к обучающей выборки.
Методы, основанные на предположениях о классе решающих функций. В данной группе считается известным вид решающей функции и задан функционал ее качества. На основании этого функционала по обучающей последовательности находят оптимальное приближение к решающей функции. Функционал качества решающего правила обычно связывают с ошибкой. Основным достоинством метода является ясность математической постановки задачи распознавания. Возможность извлечения новых знаний о природе объекта, в частности знаний о механизмах взаимодействия атрибутов, здесь принципиально ограничена заданной структурой взаимодействия, зафиксированной в выбранной форме решающих функций.
Метод сравнения с прототипом. Это наиболее легкий на практике экстенсиональный метод распознавания. Он применяется, в том случае, когда распознаваемые классы показываются компактными геометрическими классами. Тогда в качестве точки - прототипа выбирается центр геометрической группировки (или ближайший к центру объект).
Для классификации неопределенного объекта находится ближайший к нему прототип, и объект относится к тому же классу, что и он. Очевидно, никаких обобщенных образов в данном методе не формируется. В качестве меры могут применяться различные типы расстояний.
Метод k ближайших соседей. Метод заключается в том, что при классификации неизвестного объекта находится заданное число (k) геометрически ближайших пространстве признаков других ближайших соседей с уже известной принадлежностью к какому-либо классу. Решение об отнесении неизвестного объекта принимается путем анализа информации о его ближайших соседей. Необходимость сокращения числа объектов в обучающей выборке (диагностических прецедентов) является недостатком данного метода, так как это уменьшает представительность обучающей выборки.
Исходя из того, что различные алгоритмы распознавания проявляют себя по-разному на одной и той же выборке, то встает вопрос о синтетическом решающем правиле, которое бы использовало сильные стороны всех алгоритмов. Для этого существует синтетический метод или коллективы решающих правил, которые объединяют в себе максимально положительные стороны каждого из методов.
В заключение обзора методов распознавания представим суть вышеизложенного в сводной таблице, добавив туда также некоторые другие используемые на практике методы.
Таблица 1. Таблица классификации методов распознавания, сравнения их областей применения и ограничений
|
Классификация методов распознавания |
Область применения |
Ограничения (недостатки) |
|
|
Интенсиальные методы распознавания |
Методы, основанные на оценках плотностей |
Задачи с известным распределением (нормальным), необходимость набора большой статистики |
Необходимость перебора всей обучающей выборки при распознавании, высокая чувствительность к не представительности обучающей выборки и артефактам |
|
Методы, основанные на предположениях |
Классы должны быть хорошо разделяемыми |
Должен быть заранее известен вид решающей функции. Невозможность учета новых знаний о корреляциях между признаками |
|
|
Логические методы |
Задачи небольшой размерности |
При отборе логических решающих правил необходим полный перебор. Высокая трудоемкость |
|
|
Лингвистические методы |
Задача определения грамматики по некоторому множеству высказываний (описаний объектов), является трудно формализуемой. Нерешенность теоретических проблем |
||
|
Экстенсиальные методы распознавания |
Метод сравнения с прототипом |
Задачи небольшой размерности пространства признаков |
Высокая зависимость результатов классификации от метрики. Неизвестность оптимальной метрики |
|
Метод k ближайших соседей |
Высокая зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Вычислительная трудоемкость |
||
|
Алгоритмы вычисления оценок (АВО) |
Задачи небольшой размерности по количеству классов и признаков |
Зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Высокая техническая сложность метода |
|
|
Коллективы решающих правил (КРП) - синтетический метод. |
Задачи небольшой размерности по количеству классов и признаков |
Очень высокая техническая сложность метода, нерешенность ряда теоретических проблем, как при определении областей компетенции частных методов, так и в самих частных методах |







