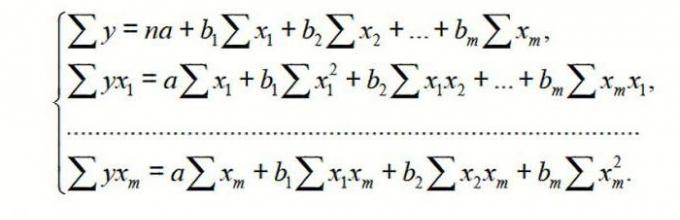
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Количество уволившихся | Зарплата |
||
30000 рублей |
|||
35000 рублей |
|||
40000 рублей |
|||
45000 рублей |
|||
50000 рублей |
|||
55000 рублей |
|||
60000 рублей |
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Множественная регрессия
Под таким термином понимается уравнение связи с несколькими независимыми переменными вида:
y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные).
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)

Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой

Отсюда получаем:

где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:

в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
Задача с использованием уравнения линейной регрессии
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
номер месяца | название месяца | цена товара N |
|
1750 рублей за тонну |
|||
1755 рублей за тонну |
|||
1767 рублей за тонну |
|||
1760 рублей за тонну |
|||
1770 рублей за тонну |
|||
1790 рублей за тонну |
|||
1810 рублей за тонну |
|||
1840 рублей за тонну |
|||
Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
Цена на товар N = 11,714* номер месяца + 1727,54.
или в алгебраических обозначениях
y = 11,714 x + 1727,54
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:

- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Оценка статистической значимости параметров и уравнения в целом – это обязательная процедура, которая позволяет сделать ввод о возможности использования построенного уравнения связи для принятия управленческих решений и прогнозирования.
Оценка статистической значимости уравнения регрессии осуществляется с использованием F-критерия Фишера, который представляет собой отношение факторной и остаточных дисперсий, рассчитанных на одну степень свободы.
Факторная дисперсия – объясненная часть вариации признака-результата, то есть обусловленная вариацией тех факторов, которые включены в анализ (в уравнение):
где k – число факторов в уравнении регрессии (число степеней свободы факторной дисперсии); - среднее значение зависимой переменной; - теоретическое (рассчитанное по уравнению регрессии) значение зависимой переменной у i – й единицы совокупности.
Остаточная дисперсия – необъясненная часть вариации признака-результата, то есть обусловленная вариацией прочих факторов, не включенных в анализ.
 =
=  , (71)
, (71)
где - фактическое значение зависимой переменной у i – й единицы совокупности; n-k-1 – число степеней свободы остаточной дисперсии; n – объем совокупности.
Сумма факторной и остаточной дисперсий, как отмечалось выше, есть общая дисперсия признака-результата.
F-критерия Фишера рассчитывается по следующей формуле:
F-критерий Фишера – величина, отражающая соотношение объясненной и необъясненной дисперсий, позволяет ответить на вопрос: объясняют ли включенные в анализ факторы статистическую значимую часть вариации признака-результата. F-критерий Фишера табулирован (входом в таблицу является число степеней свободы факторной и остаточной дисперсий). Если  , то уравнение регрессии признается статистически значимым и, соответственно, статистически значим коэффициент детерминации. В противном случае, уравнение – статистически не значимо, т.е. не объясняет существенной части вариации признака-результата.
, то уравнение регрессии признается статистически значимым и, соответственно, статистически значим коэффициент детерминации. В противном случае, уравнение – статистически не значимо, т.е. не объясняет существенной части вариации признака-результата.
Оценка статистической значимости параметров уравнения осуществляется на основе t-статистики, которая рассчитывается как отношение модуля параметров уравнения регрессии к их стандартным ошибкам ( ):
):
 , где
, где  ; (73)
; (73)
 , где
, где  . (74)
. (74)
В любой статистической программе расчет параметров всегда сопровождается расчетом значений их стандартных (среднеквадратических) ошибок и t-статистики. Параметр признаются статистически значимым, если фактическое значение t-статистики больше табличного.
Оценка параметров на основе t-статистики, по существу, является проверкой нулевой гипотезы о равенстве генеральных параметров нулю (H 0: =0; H 0: =0;), то есть о не значимости параметров уравнения регрессии. Уровень значимости принятия нулевых гипотез = 1-0,95=0,05 (0,95 – уровень вероятности, как правило, устанавливаемый в экономических расчетах). Если расчетный уровень значимости меньше 0,05 , то нулевая гипотеза отвергается и принимается альтернативная - о статистической значимости параметра.
Проводя оценку статистической значимости уравнения регрессии и его параметров, мы можем получить различное сочетание результатов.
· Уравнение по F-критерию статистически значимо и все параметры уравнения по t-статистике тоже статистически значимы. Данное уравнение может быть использовано как для принятия управленческих решений (на какие факторы следует воздействовать, чтобы получить желаемый результат), так и для прогнозирования поведения признака-результата при тех или иных значениях факторов.
· По F-критерию уравнение статистически значимо, но незначимы отдельные параметры уравнения. Уравнение может быть использовано для принятия управленческих решений (касающихся тех факторов, по которым получено подтверждение статистической значимости их влияния), но уравнение не может быть использовано для прогнозирования.
· Уравнение по F-критерию статистически незначимо. Уравнение не может быть использовано. Следует продолжить поиск значимых признаков-факторов или аналитической формы связи аргументов и отклика.
Если подтверждена статистическая значимость уравнения и его параметров, то может быть реализован, так называемый, точечный прогноз, т.е. рассчитывается вероятное значение признака-результата (y) при тех или иных значениях факторов (x). Совершенно очевидно, что прогнозное значение зависимой переменной не будет совпадать с фактическим ее значением. Это связано, прежде всего, с самой сутью корреляционной зависимости. Одновременно на результат воздействует множество факторов, из которых только часть может быть учтена в уравнении связи. Кроме того, может быть неверно выбрана форма связи результата и факторов (тип уравнения регрессии). Между фактическими значениями признака-результата и его теоретическими (прогнозными) значениями всегда существует различие ( ). Графически эта ситуация выражается в том, что не все точки поля корреляции лежат на линии регрессии. Лишь при функциональной связи линия регрессии пройдет через все точки поля корреляции. Разность между фактическими и теоретическими значениями результативного признака называют отклонениями или ошибками, или остатками. На основе этих величин и рассчитывается остаточная дисперсия, являющаяся оценкой среднеквадратической ошибки уравнения регрессии. Величина стандартной ошибки используется для расчета доверительных интервалов прогнозного значения признака-результата (Y).
). Графически эта ситуация выражается в том, что не все точки поля корреляции лежат на линии регрессии. Лишь при функциональной связи линия регрессии пройдет через все точки поля корреляции. Разность между фактическими и теоретическими значениями результативного признака называют отклонениями или ошибками, или остатками. На основе этих величин и рассчитывается остаточная дисперсия, являющаяся оценкой среднеквадратической ошибки уравнения регрессии. Величина стандартной ошибки используется для расчета доверительных интервалов прогнозного значения признака-результата (Y).
Проверку значимости уравнения регрессии произведем на основе
F-критерия Фишера:
Значение F-критерия Фишера можно найти в таблице Дисперсионный анализ протокола Еxcel. Табличное значение F-критерия при доверительной вероятности α = 0,95 и числе степеней свободы, равном v1 = k = 2 и v2 = n – k – 1= 50 – 2 – 1 = 47, составляет 0,051.
Поскольку Fрасч > Fтабл, уравнение регрессии следует признать значимым, то есть его можно использовать для анализа и прогнозирования.
Оценку значимости коэффициентов полученной модели, используя результаты отчета Excel, можно осуществить тремя способами.
Коэффициент уравнения регрессии признается значимым в том случае, если:
1) наблюдаемое значение t-статистики Стьюдента для этого коэффициента больше, чем критическое (табличное) значение статистики Стьюдента (для заданного уровня значимости, например α = 0,05, и числа степеней свободы df = n – k – 1, где n – число наблюдений, а k – число факторов в модели);
2) Р-значение t-статистики Стьюдента для этого коэффициента меньше, чем уровень значимости, например, α = 0,05;
3) доверительный интервал для этого коэффициента, вычисленный с некоторой доверительной вероятностью (например, 95%), не содержит ноль внутри себя, то есть нижняя 95% и верхняя 95% границы доверительного интервала имеют одинаковые знаки.
Значимость коэффициентов a 1 и a 2 проверим по второму и третьему способам:
P-значение (a 1 ) = 0,00 < 0,01 < 0,05.
Р-значение (a 2 ) = 0,00 < 0,01 < 0,05.
Следовательно, коэффициенты a 1 и a 2 значимы при 1%-ном уровне, а тем более при 5%-ном уровне значимости. Нижние и верхние 95% границы доверительного интервала имеют одинаковые знаки, следовательно, коэффициенты a 1 и a 2 значимы.
Определение объясняющей переменной, от которой
Может зависеть дисперсия случайных возмущений.
Проверка выполнения условия гомоскедастичности
Остатков по тесту Гольдфельда–Квандта
При проверке предпосылки МНК о гомоскедастичности остатков в модели множественной регрессии следует вначале определить, по отношению к какому из факторов дисперсия остатков более всего нарушена. Это можно сделать в результате визуального исследования графиков остатков, построенных по каждому из факторов, включенных в модель. Та из объясняющих переменных, от которой больше зависит дисперсия случайных возмущений, и будет упорядочена по возрастанию фактических значений при проверке теста Гольдфельда–Квандта. Графики легко получить в отчете, который формируется в результате использования инструмента Регрессия в пакете Анализ данных).


Графики остатков по каждому из факторов двухфакторной модели
Из представленных графиков видно, что дисперсия остатков более всего нарушена по отношению к фактору Краткосрочная дебиторская задолженность.
Проверим наличие гомоскедастичности в остатках двухфакторной модели на основе теста Гольдфельда–Квандта.
Уберем из середины упорядоченной совокупности С = 1/4 · n = 1/4 · 50 = 12,5 (12) значения. В результате получим две совокупности соответственно с малыми и большими значениями Х4.
Для каждой совокупности выполним расчеты:
Упорядочим переменные Y и X2 по возрастанию фактора Х4 (в Excel для этого можно использовать команду Данные – Сортировка по возрастанию Х4):
|
Данные, отсортированные по возрастанию X4: |
||
|
Сумма |
111234876536,511 |
||||
|
966570797682,068 |
|||||
|
455748832843,413 |
|||||
|
232578961097,877 |
|||||
|
834043911651,192 |
|||||
|
193722998259,505 |
|||||
|
1246409153509,290 |
|||||
|
31419681912489,100 |
|||||
|
2172804245053,280 |
|||||
|
768665257272,099 |
|||||
|
2732445494273,330 |
|||||
|
163253156450,331 |
|||||
|
18379855056009,900 |
|||||
|
10336693841766,000 |
|||||
|
Сумма |
69977593738424,600 |
Уравнения для совокупностей
Y = -27275,746 + 0,126X2 + 1,817 X4
Y = 61439,511 + 0,228X2 + 0,140X4
Результаты данной таблицы получены с помощью инструмента Регрессия поочередно к каждой из полученных совокупностей.
4. Найдем отношение полученных остаточных сумм квадратов
(в числителе должна быть большая сумма):
5. Вывод о наличии гомоскедастичности остатков делаем с помощью F-критерия Фишера с уровнем значимости α = 0,05 и двумя одинаковыми степенями свободы k1 = k2 = == 17
где р – число параметров уравнения регрессии:
Fтабл (0,05; 17; 17) = 9,28.
Так как Fтабл > R ,то подтверждается гомоскедастичность в остатках двухфакторной регрессии.
После того, как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Проверить значимость уравнения регрессии - значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включённых в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Проверка значимости производится на основе дисперсионного анализа.
Согласно идее дисперсионного анализа, общая сумма квадратов отклонений (СКО) y от среднего значения раскладывается на две части - объясненную и необъясненную:
или, соответственно:
Здесь возможны два крайних случая: когда общая СКО в точности равна остаточной и когда общая СКО равна факторной.
В первом случае фактор х не оказывает влияния на результат, вся дисперсия y обусловлена воздействием прочих факторов, линия регрессии параллельна оси Ох и уравнение должно иметь вид.
Во втором случае прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю.
Однако на практике в правой части присутствуют оба слагаемых. Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации y приходится на объясненную вариацию. Если объясненная СКО будет больше остаточной СКО, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат y. Это равносильно тому, что коэффициент детерминации будет приближаться к единице.
Число степеней свободы (df-degrees of freedom) - это число независимо варьируемых значений признака.
Для общей СКО требуется (n-1) независимых отклонений,
Факторная СКО имеет одну степень свободы, и
Таким образом, можем записать:
Из этого баланса определяем, что = n-2.

Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: - общая дисперсия, - факторная, - остаточная.
Анализ статистической значимости коэффициентов линейной регрессии
Хотя теоретические значения коэффициентов уравнения линейной зависимости предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик.
Дисперсии коэффициентов рассчитываются по формулам:
Дисперсия коэффициента регрессии:

где - остаточная дисперсия на одну степень свободы.
Дисперсия параметра:

Отсюда стандартная ошибка коэффициента регрессии определяется по формуле:

Стандартная ошибка параметра определяется по формуле:

Они служат для проверки нулевых гипотез о том, что истинное значение коэффициента регрессии b или свободного члена a равно нулю: .
Альтернативная гипотеза имеет вид: .
t - статистики имеют t - распределение Стьюдента с степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости б и степенях свободы находят критическое значение.
Если, то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми.
Если, то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид, и это означает, что связь между признаками отсутствует. В случае, если коэффициент а статистически незначим, рекомендуется оценить новое уравнение в виде).
Интервальные оценки коэффициентов линейного уравнения регрессии:
Доверительный интервал для а: .
Доверительный интервал для b:
Это означает, что с заданной надёжностью (где - уровень значимости) истинные значения а, b находятся в указанных интервалах.
Коэффициент регрессии имеет четкую экономическую интерпретацию, поэтому доверительные границы интервала не должны содержать противоречивых результатов, например, Они не должны включать нуль.
Анализ статистической значимости уравнения в целом.
Распределение Фишера в регрессионном анализе
Оценка значимости уравнения регрессии в целом дается с помощью F- критерия Фишера. При этом выдвигается нулевая гипотеза о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y (или).
Величина F - критерия связана с коэффициентом детерминации. В случае множественной регрессии:
где m - число независимых переменных.
В случае парной регрессии формула F - статистики принимает вид:
При нахождении табличного значения F- критерия задается уровень значимости (обычно 0,05 или 0,01) и две степени свободы: - в случае множественной регрессии, - для парной регрессии.
Если, то отклоняется и делается вывод о существенности статистической связи между y и x.
Если, то вероятность уравнение регрессии считается статистически незначимым, не отклоняется.
Замечание. В парной линейной регрессии. Кроме того, поэтому. Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Распределение Фишера может быть использовано не только для проверки гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, но и гипотезы о равенстве нулю части этих коэффициентов. Это важно при развитии линейной регрессионной модели, так как позволяет оценить обоснованность исключения отдельных переменных или их групп из числа объясняющих переменных, или же, наоборот, включения их в это число.
Пусть, например, вначале была оценена множественная линейная регрессия по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен, затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение, для которого коэффициент детерминации равен (, т.к. каждая дополнительная переменная объясняет часть, пусть небольшую, вариации зависимой переменной).
Для того, чтобы проверить гипотезу об одновременном равенстве нулю всех коэффициентов при исключённых переменных, рассчитывается величина
имеющая распределение Фишера с степенями свободы.
По таблицам распределения Фишера, при заданном уровне значимости, находят. И если, то нулевая гипотеза отвергается. В таком случае исключать все k переменных из уравнения некорректно.
Аналогичные рассуждения могут быть проведены и по поводу обоснованности включения в уравнение регрессии одной или нескольких k новых объясняющих переменных.
В этом случае рассчитывается F - статистика
имеющая распределение. И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано).
Замечания. 1. Включать новые переменные целесообразно по одной.
2. Для расчёта F - статистики при рассмотрении вопроса о включении объясняющих переменных в уравнение желательно рассматривать коэффициент детерминации с поправкой на число степеней свободы.
F - статистика Фишера используется также для проверки гипотезы о совпадении уравнений регрессии для отдельных групп наблюдений.
Пусть имеются 2 выборки, содержащие, соответственно, наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида. Пусть СКО от линии регрессии (т.е.) равны для них, соответственно, .
Проверяется нулевая гипотеза: о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же.
Пусть оценено уравнение регрессии того же вида сразу для всех наблюдений, и СКО.
Тогда рассчитывается F - статистика по формуле:
Она имеет распределение Фишера с степенями свободы. F - статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае. Т.е. если, то нулевая гипотеза принимается.
Если же, то нулевая гипотеза отвергается, и единое уравнение регрессии построить нельзя.
100 р бонус за первый заказ
Выберите тип работы Дипломная работа Курсовая работа Реферат Магистерская диссертация Отчёт по практике Статья Доклад Рецензия Контрольная работа Монография Решение задач Бизнес-план Ответы на вопросы Творческая работа Эссе Чертёж Сочинения Перевод Презентации Набор текста Другое Повышение уникальности текста Кандидатская диссертация Лабораторная работа Помощь on-line
Узнать цену
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров . Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации : Средняя ошибка аппроксимации не должна превышать 8–10%.
Оценка значимости уравнения регрессии в целом производится на основе F
-критерия Фишера
, которому предшествует дисперсионный анализ. Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной y
от среднего значения y
раскладывается на две части – «объясненную» и «необъясненную»: где – общая сумма квадратов отклонений; – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений); ![]() – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов. Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F
-критерия Фишера:
– остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов. Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F
-критерия Фишера:  Фактическое значение F
-критерия Фишера сравнивается с
Фактическое значение F
-критерия Фишера сравнивается с
табличным значением F табл(a; k 1; k 2) при уровне значимости a и степенях свободы k 1 = m и k 2= n -m -1.При этом, если фактическое значение F - критерия больше табличного, то признается статистическая значимость уравнения в целом.
Для парной линейной регрессии m
=1, поэтому 
Величина F
-критерия связана с коэффициентом детерминации R2 ее можно рассчитать по следующей формуле: 
В парной линейной регрессии оценивается значимость не только уравнения в целом, но и отдельных его параметров
. С этой целью по каждому из параметров определяется его стандартная ошибка: m b
и m a
. Стандартная ошибка коэффициента регрессии определяется по формуле: , где
, где 
Величина стандартной ошибки совместно с t –распределением Стьюдента при n -2 степенях свободы применяется для проверки существенности коэффициента регрессии и для расчета его доверительного интервала. Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение t -критерия Стьюдента: которое затем сравнивается с табличным значением при определенном уровне значимости a и числе степеней свободы (n-2). Доверительный интервал для коэффициента регрессии определяется как b ± t табл ×mb . Поскольку знак коэффициента регрессии указывает на рост результативного признака y при увеличении признака-фактора x (b >0), уменьшение результативного признака при увеличении признака-фактора (b <0) или его независимость от независимой переменной (b =0), то границы доверительного интервала для коэффициента регрессии не должны содержать противоречивых результатов, например, -1,5 £ b £ 0,8. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
Стандартная ошибка параметра a
определяется по формуле:  Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии. Вычисляется t
-критерий: , его величина сравнивается с табличным значением при n
- 2 степенях свободы.
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии. Вычисляется t
-критерий: , его величина сравнивается с табличным значением при n
- 2 степенях свободы.







