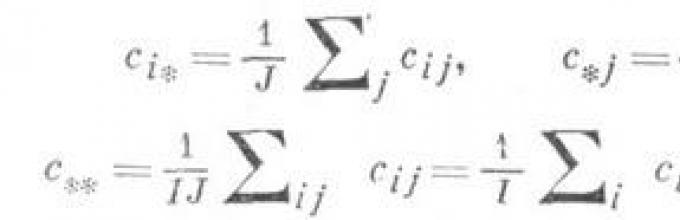
Дисперсионный анализ (от латинского Dispersio – рассеивание / на английском Analysis Of Variance - ANOVA) применяется для исследования влияния одной или нескольких качественных переменных (факторов) на одну зависимую количественную переменную (отклик).
| |
В основе дисперсионного анализа лежит предположение о том, что одни переменные могут рассматриваться как причины (факторы, независимые переменные): , а другие как следствия (зависимые переменные). Независимые переменные называют иногда регулируемыми факторами именно потому, что в эксперименте исследователь имеет возможность варьировать ими и анализировать получающийся результат.
Основной целью дисперсионного анализа (ANOVA) является исследование значимости различия между средними с помощью сравнения (анализа) дисперсий. Разделение общей дисперсии на несколько источников, позволяет сравнить дисперсию, вызванную различием между группами, с дисперсией, вызванной внутригрупповой изменчивостью. При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии. Если вы просто сравниваете средние в двух выборках , дисперсионный анализ даст тот же результат, что и обычный t-критерий для независимых выборок (если сравниваются две независимые группы объектов или наблюдений) или t-критерий для зависимых выборок (если сравниваются две переменные на одном и том же множестве объектов или наблюдений).
Сущность дисперсионного анализа заключается в расчленении общей дисперсии изучаемого признака на отдельные компоненты, обусловленные влиянием конкретных факторов, и проверке гипотез о значимости влияния этих факторов на исследуемый признак. Сравнивая компоненты дисперсии друг с другом посредством F-критерия Фишера , можно определить, какая доля общей вариативности результативного признака обусловлена действием регулируемых факторов.
Исходным материалом для дисперсионного анализа служат данные исследования трех и более выборок : , которые могут быть как равными, так и неравными по численности, как связными, так и несвязными. По количеству выявляемых регулируемых факторов дисперсионный анализ может быть однофакторным (при этом изучается влияние одного фактора на результаты эксперимента), двухфакторным (при изучении влияния двух факторов) и многофакторным (позволяет оценить не только влияние каждого из факторов в отдельности, но и их взаимодействие).
Дисперсионный анализ относится к группе параметрических методов и поэтому его следует применять только тогда, когда доказано, что распределение является нормальным .
Дисперсионный анализ используют, если зависимая переменная измеряется в шкале отношений, интервалов или порядка, а влияющие переменные имеют нечисловую природу (шкала наименований).
Примеры задач
В задачах, которые решаются дисперсионным анализом, присутствует отклик числовой природы, на который воздействует несколько переменных, имеющих номинальную природу. Например, несколько видов рационов откорма скота или два способа их содержания и т.п.
Пример 1: В течение недели в трех разных местах работало несколько аптечных киосков. В дальнейшем мы можем оставить только один. Необходимо определить, существует ли статистически значимое отличие между объемами реализации препаратов в киосках. Если да, мы выберем киоск с наибольшим среднесуточным объемом реализации. Если же разница объема реализации окажется статистически незначимой, то основанием для выбора киоска должны быть другие показатели.
Пример 2: Cравнение контрастов групповых средних. Семь политических пристрастий упорядочены от крайне либеральные до крайне консервативные, и линейный контраст используется для проверки того, есть ли отличная от нуля тенденция к возрастанию средних значений по группам - т. е. есть ли значимое линейное увеличение среднего возраста при рассмотрении групп, упорядоченных в направлении от либеральных до консервативных.
Пример 3: Двухфакторный дисперсионный анализ. На количество продаж товара, помимо размеров магазина, часто влияет расположение полок с товаром. Данный пример содержит показатели недельных продаж, характеризуемые четырьмя типами расположения полок и тремя размерами магазинов. Результаты анализа показывают, что оба фактора - расположение полок с товаром и размер магазина -влияют на количество продаж, однако их взаимодействие значимым не является.
Пример 4: Одномерный ANOVA: Рандомизированный полноблочный план с двумя обработками. Исследуется влияние на припек хлеба всех возможных комбинаций трех жиров и трех рыхлителей теста. Четыре образца муки, взятые из четырех разных источников, служили в качестве блоковых факторов.Необходимо выявить значимость взаимодействия жир-рыхлитель. После этого определить различные возможности выбора контрастов, позволяющих выяснить, какие именно комбинации уровней факторов различаются.
Пример 5: Модель иерархического (гнездового) плана с смешанными эффектами. Изучается влияние четырех случайно выбранных головок, вмонтированных в станок, на деформацию производимых стеклянных держателей катодов. (Головки вмонтированы в станок, так что одна и та же головка не может использоваться на разных станках). Эффект головки обрабатывается как случайный фактор. Статистики ANOVA показывают, что между станками нет значимых различий, но есть признаки того, что головки могут различаться. Различие между всеми станками не значимо, но для двух из них различие между типами головок значимо.
Пример 6: Одномерный анализ повторных измерений с использованием плана расщепленных делянок. Этот эксперимент проводился для определения влияния индивидуального рейтинга тревожности на сдачу экзамена в четырех последовательных попытках. Данные организованы так, чтобы их можно было рассматривать как группы подмножеств всего множества данных ("всей делянки"). Эффект тревожности оказался незначимым, а эффект попытки - значим.
Перечень методов
- Модели факторного эксперимента. Примеры: факторы, влияющие на успешность решения математических задач ; факторы, влияющие на объёмы продаж .
Данные состоят из нескольких рядов наблюдений (обработок), которые рассматриваются как реализации независимых между собой выборок. Исходная гипотеза говорит об отсутствии различия в обработках, т.е. предполагается, что все наблюдения можно считать одной выборкой из общей совокупности:
- Однофакторная параметрическая модель : метод Шеффе .
- Однофакторная непараметрическая модель [Лагутин М.Б., 237]: критерий Краскела-Уоллиса [Холлендер М., Вульф Д.А., 131], критерий Джонкхиера [Лагутин М.Б., 245].
- Общий случай модели с постоянными факторами, теорема Кокрена [Афифи А., Эйзен С., 234].
Данные представляют собой двухкратные повторные наблюдения:
- Двухфакторная непараметрическая модель : критерий Фридмана [Лапач, 203], критерий Пейджа [Лагутин М.Б., 263]. Примеры: сравнение эффективности методов производства, агротехнических приёмов.
- Двухфакторная непараметрическая модель для неполных данных
История
Откуда произошло название дисперсионный анализ ? Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними двух (или нескольких) групп, мы на самом деле сравниваем (анализируем) выборочные дисперсии. Фундаментальная концепция дисперсионного анализа предложена Фишером в 1920 году. Возможно, более естественным был бы термин анализ суммы квадратов или анализ вариации, но в силу традиции употребляется термин дисперсионный анализ. Первоначально дисперсионный анализ был разработан для обработки данных, полученных в ходе специально поставленных экспериментов, и считался единственным методом, корректно исследующим причинные связи. Метод применялся для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Литература
- Шеффе Г. Дисперсионный анализ. - М., 1980.
- Аренс Х. Лёйтер Ю. Многомерный дисперсионный анализ.
- Кобзарь А. И. Прикладная математическая статистика. - М.: Физматлит, 2006.
- Лапач С. Н. , Чубенко А. В., Бабич П. Н. Статистика в науке и бизнесе. - Киев: Морион, 2002.
- Лагутин М. Б. Наглядная математическая статистика. В двух томах. - М.: П-центр, 2003.
- Афифи А., Эйзен С. Статистический анализ: Подход с использованием ЭВМ.
- Холлендер М., Вульф Д.А. Непараметрические методы статистики.
Ссылки
- Дисперсионный анализ - Электронный учебник StatSoft.
ДИСПЕРСИОННЫЙ АНАЛИЗ
в математической статистике - статистический метод, предназначенный для выявления влияния отдельных факторов на результат эксперимента, а также для последующего планирования аналогичных экспериментов. Первоначально Д. а. был предложен Р. Фишером для обработки результатов агрономич. опытов по выявлению условий, при к-рых испытываемый сорт сельскохозяйственной культуры дает максимальный урожай. Современные приложения Д. а. охватывают широкий задач экономики, социологии, биологии и техники и трактуются обычно в терминах статистич. теории выявления систематич. различий между результатами непосредственных измерений, выполненных при тех пли иных меняющихся условиях.
Если значения неизвестных постоянных a 1 , ... , a I могут быть измерены с помощью различных методов или измерительных средств М 1 ,. .., M J , и в каждом случае систематич. ошибка b ij может, вообще говоря, зависеть как от выбранного метода Mj, так и от неизвестного измеряемого значения а i , то результаты таких измерений представляют собой суммы вида
где К- количество независимых измерений неизвестной величины а i методом M j , a у ijk - случайная ошибка k-го измерения величины а i методом M j (предполагается, что все y ijk - независимые одинаково распределенные случайные величины, имеющие нулевое математич. ожидание: Е у ijk =0). Такая линейная наз. двухфакторной схемой Д. а.; первый - истинное значение измеряемой величины, второй - метод измерения, причем в данном случае для каждой возможной комбинации значений первого и второго факторов осуществляется одинаковое количество Кнезависимых измерений (это допущение для целей Д. а. не является существенным и введено здесь лишь ради простоты изложения).
Примером подобной ситуации могут служить спортивные соревнования I спортсменов, мастерство к-рых оценивается J судьями, причем каждый участник соревнований выступает Краз (имеет К"попыток"). В этом случае а i - истинное значение показателя мастерства спортсмена с номером i, b ij - систематич. ошибка, вносимая в оценку мастерства i -го спортсмена судьей с номером j, x ijk - оценка, выставленная j -м судьей г-му спортсмену после выполнений последним k-й попытки, а y ijk - соответствующая случайная . Подобная типична для так наз. субъективной экспертизы качества нескольких объектов, осуществляемой группой независимых экспертов. Другой пример - статистич. исследование урожайности сельскохозяйственной культуры в зависимости от одного из J сортов почвы и J методов ее обработки, причем для каждого сорта г почвы и каждого метода обработки с номером J осуществляется kнезависимых экспериментов (в этом примере b ij - истинное значение урожайности для г-го сорта почвы при j-м способе обработки, x ijk - соответствующая экспериментально наблюдаемая урожайность в k-м опыте, а y ijk - ее случайная ошибка, возникающая из-за тех или иных случайных причин; что же касается величин а i , то в агрономич. опытах их разумно считать равными нулю).
Положим c ij =a i +b ij , и пусть с i *, с *j и с ** - результаты осреднений с ij по соответствующим индексам, т. е.

Пусть, кроме того, a=c ** , b i = с i* - с ** , g j = с *j -с ** и d ij = с ij - с i* - с *j +c ** . Идея Д. а. основана на очевидном тождестве
Если символом (c ij
)обозначить размерности IJ
, получаемый из матрицы ||с ij
|| порядка IXJ с помощью какого-либо заранее фиксированного способа упорядочивания ее элементов, то (1) можно записать в виде равенства где все векторы имеют IJ
, причем a ij
=a, b ij
=b i
, g ij
=g j
. Так как четыре вектора в правой части (2) ортогональны, то a ij
=a - наилучшее приближение функции c ij
от аргументов i и j
постоянной величиной [в смысле минимальности суммы квадратов отклонений ![]() ]. В том же смысле a ij
+b ij
=a+b i
- наилучшее c ij
функцией, зависящей лишь от i, a ij
+g ij
=a+g j
- наилучшее приближение c ij
функцией, зависящей лишь от j, a a ij
+b ij
+g ij
=a+b i
+g j
- наилучшее приближение c ij
суммой функций, из к-рых одна (напр., a+b i
) зависит лишь от г, а другая - лишь от j. Этот факт, установленный Р. Фишером (см. ) в 1918, позднее послужил основой теории квадратичных приближений функций.
]. В том же смысле a ij
+b ij
=a+b i
- наилучшее c ij
функцией, зависящей лишь от i, a ij
+g ij
=a+g j
- наилучшее приближение c ij
функцией, зависящей лишь от j, a a ij
+b ij
+g ij
=a+b i
+g j
- наилучшее приближение c ij
суммой функций, из к-рых одна (напр., a+b i
) зависит лишь от г, а другая - лишь от j. Этот факт, установленный Р. Фишером (см. ) в 1918, позднее послужил основой теории квадратичных приближений функций.
В примере, связанном со спортивными соревнованиями, d ij выражает "взаимодействие" г-го спортсмена и j-го судьи (положительное значение б/у означает "подсуживание", т. с. систематич. завышение /-м судьей оценки мастерства i-го спортсмена, а отрицательное значение б/у означает "засуживание", т. е. систематич. снижение оценки). Равенство всех б/у нулю - необходимое требование, к-рое надлежит предъявлять к работе группы экспертов. В случае же агрономич. опытов такое равенство рассматривается как гипотеза, подлежащая проверке по результатам экспериментов, поскольку основная цель здесь - отыскание таких значений i и j, при к-рых функция (1) достигает максимального значения. Если эта гипотеза верна, то
и значит, выявление наилучших "почвы" и "обработки" может быть осуществлено раздельно, что приводит к существенному сокращению числа экспериментов (напр., можно при каком-либо одном способе обработки испытать все Iсортов "почвы" и определить наилучший сорт, а затем на этом сорте опробовать все J способов "обработки" и найти наилучший способ; общее количество экспериментов с повторениями будет равно (I+J) К). Если же гипотеза {все d ij =0} неверна, то для определения max c ij необходим описанный выше "полный план", требующий при Кповторениях IJК экспериментов.
В ситуации спортивных соревнований функция g ij =g j может трактоваться как систематич. ошибка, допускаемая j-м судьей по отношению ко всем спортсменам. В конечном счете g j - характеристика "строгости" или "либеральности" j-го судьи. В идеале хотелось бы, чтобы все g j были нулевыми, но в реальных условиях приходится мириться с наличием ненулевых значений g j и учитывать это обстоятельство при подведении итогов экспертизы (напр., за основу сравнения мастерства спортсменов можно принять не последовательности истинных значений a+b 1 +g j , ..., a+b I +g j , a лишь результаты упорядочиваний этих чисел по их величине, поскольку при всех j=1, . . . , J такие упорядочивания будут одинаковыми). Наконец, сумма двух оставшихся функций a ij +b ij =a+b i зависит лишь от iи поэтому может быть использована для характеризации мастерства г-го спортсмена. Однако здесь нужно помнить, что Поэтому упорядочивание всех спортсменов по значениям a+b i (или по a+ + b i +g j при каждом фиксированном j) может не совпадать с упорядочиванием по значениям a i . При практической обработке экспертных оценок этим обстоятельством приходится пренебрегать, так как Упомянутый полный план экспериментов не позволяет оценивать отдельно a i и b i* . Таким образом, a+b i =a i + b i* характеризует не только мастерство i -го спортсмена, но и в той или иной мере экспертов к этому мастерству. Поэтому, напр., результаты субъективных экспертных оценок, осуществленных в разное время (в частности, на нескольких Олимпийских играх), едва ли можно считать сопоставимыми. В случае же агрономич. опытов подобные трудности не возникают, поскольку все a i =0 и значит, a+b i =b i* .
Истинные значения функций a, b i , g i и d ij неизвестны и выражаются в терминах неизвестных функций c ij . Поэтому первый этап Д. а. заключается в отыскании статистич. оценок для c ij по результатам наблюдений x ijk .Несмещенная и имеющая минимальную дисперсию для c ij выражается формулой
![]()
Так как a, b i
, g j
и d ij
- линейные функции от элементов матрицы ||c ij
||, то несмещенные линейные оценки для этих функций, имеющие минимальную дисперсию, получаются в результате замены аргументов c ij
соответствующими оценками, c ij ,
т. е. причем случайные векторы ![]() и определенные так же, как введенные выше (a ij
),
(b ij
), (g ij
).
и (d ij
), обладают свойством ортогональности, и значит, они представляют собой некоррелированные случайные векторы (иными словами, любые две компоненты, принадлежащие разным векторам, имеют нулевой корреляции). Кроме того, любая вида
и определенные так же, как введенные выше (a ij
),
(b ij
), (g ij
).
и (d ij
), обладают свойством ортогональности, и значит, они представляют собой некоррелированные случайные векторы (иными словами, любые две компоненты, принадлежащие разным векторам, имеют нулевой корреляции). Кроме того, любая вида
некоррелирована с любой из компонент этих
четырех векторов. Рассмотрим пять совокупностей случайных величин {x ijk }, {x ijk
-x ij* },
![]() Так как
Так как

то дисперсии эмпирич. распределений, соответствующих указанным совокупностям, выражаются формулами

Эти эмпирич. дисперсии представляют собой суммы квадратов случайных величин, любые две из к-рых некоррелированы, если только они принадлежат разным суммам; при этом относительно всех y ijk справедливо тождество
объясняющее происхождение термина "Д. а."" Пусть и пусть

в таком случае
где s 2 - дисперсия случайных ошибок y ijk .
На основе этих формул и строится второй этап Д. а., посвященный выявлению влияния первого и второго факторов на результаты эксперимента (в агрономич. опытах первый фактор - сорт "почвы", второй - способ "обработки"). Напр., если требуется проверить гипотезу отсутствия "взаимодействия" факторов, к-рая выражается равенствомто разумно вычислить дисперсионное отношение s 2 3 /s 2 0 = F 3 . Если это отношение значимо отличается от единицы, то проверяемая гипотеза отвергается. Точно так же для проверки гипотезы полезно отношение s 2 2 /s 2 0 = F 2 , к-рое надлежит также сравнить с единицей; если при этом известно, чтото вместо F 2 целесообразно сравнить с единицей отношение

Аналогичным образом можно построить статистику, позволяющую дать заключение о справедливости или ложности гипотезы
Точный смысл понятия значимого отличия указанных отношений от единицы может быть определен лишь с учетом закона распределения случайных ошибок y ijk .
В Д. а. наиболее обстоятельно изучена ситуация, в к-рой все y ijk
распределены нормально. В этом случае - независимые случайные векторы, а ![]() - независимые случайные величины, причем
- независимые случайные величины, причем 
отношения подчиняются нецентральным распределениям хи-квадрат с f m степенями свободы и параметрами нецентральности l т, m =0, 1, 2, 3, где

Если параметр нецентральности равен нулю, то нецентральное хи-квадрат совпадает с обычным распределением хи-квадрат. Поэтому в случае справедливости гипотезы l 3 =0 отношение подчиняется F-распре делению (распределению дисперсионного отношения) с параметрами f 3 и f 0 . Пусть х- такое число, для к-рого события {F 3 >x} равна заданному значению е, называемому уровнем значимости (таблицы функции х= х (e; f 3 , f 0) имеются в большинстве пособий по математич. статистике). Критерием для проверки гипотезы l 3 =0 служит правило, согласно к-рому эта гипотеза отвергается, если наблюдаемое значение F 3 превышает х;в противном случае гипотеза считается не противоречащей результатам наблюдений. Аналогичным образом конструируются критерии, основанные на статистиках F 2 и F* 2 .
Дальнейшие этапы Д. а. существенно зависят не только от реального содержания конкретной задачи, но также и от результатов статистич. проверки гипотез на втором этапе. Напр., в условиях агрономич. опытов справедливость гипотезы l 3 =0, как указано выше, позволяет более экономно спланировать аналогичные дальнейшие эксперименты (если помимо гипотезы l 3 =0 справедлива также и гипотеза l 2 =0, то это означает, что урожайность зависит лишь от сорта "почвы", и поэтому в дальнейших опытах можно воспользоваться схемой однофакторного Д. а.); если же гипотеза l 3 =0 отвергается, то разумно проверить, нет ли в данной задаче неучтенного третьего фактора? Если сорта "почвы" и способы ее "обработки" варьировались не в одном и том же месте, а в различных географич. зонах, то таким фактором могут быть климатич. или географич. условия, и "обработка" наблюдений потребует применения трехфакторного Д. а.
В случае экспертных оценок статистически подтвержденная справедливость гипотезы l 3 = 0 дает основание для упорядочивания сравниваемых объектов (напр., спортсменов) по значениям величин i=l, . .. , I.
Если же гипотеза l 3 =0 отвергается (в задаче о спортивных соревнованиях это означает статистич. обнаружение "взаимодействия" нек-рых спортсменов и судей), то естественно попытаться перевычнслить все результаты заново, предварительно исключив из рассмотрения x ijk с такими парами индексов (i, j ), для к-рых абсолютные значения статистич. оценок d ij превышают нек-рый заранее установленный допустимый уровень. Это означает, что из матрицы ||x ij* || вычеркиваются нек-рые элементы, и значит, план Д. а. становится неполным.
Модели современного Д. а. охватывают широкий круг реальных экспериментальных схем (напр., схемы неполных планов, со случайно или неслучайно отобранными элементами x ij* ). Соответствующие этим схемам статистич. выводы во многих случаях находятся в стадии разработки. В частности, еще (к 1978) далеки от окончательного решения те задачи, в к-рых результаты наблюдений x ijk =c ij +y ijk не являются одинаково распределенными случайными величинами; еще более трудная задача возникает в случае зависимости величин x ijk . Неизвестно проблемы выбора факторов (даже в линейном случае). Суть этой проблемы заключается в следующем: пусть с=с ( и, v )- и пусть u=u (z, w )и u=u (z, w )- какие-либо линейные функции от переменных г и w. Фиксируя значения z 1 , . .., z I и w 1 , . . ., w J , можно при каждом заданном выборе линейных функций ии u. определить c ij формулой и построить Д. а. этих величин по результатам соответствующих наблюдений x ijk . Проблема заключается в отыскании таких линейных функций u и u, к-рым соответствует минимальное значение суммы квадратов
где (предполагается, что функция с( и, v )неизвестна). В терминах Д. а. эта проблема сводится к статистич. отысканию таких факторов z=z (u, v )и w-w (u, v ), к-рым соответствует "наименьшее взаимодействие".
Лит. : Fisher R. A., Statistical methods for research workers, Edinburgh, 1925; Шеффе Г., Дисперсионный анализ, пер. с англ., М., 1963; Xальд А., Математическая с техническими приложениями, пер. с англ., М., 1956; Снедекор Д ж. У., Статистические методы в применении к исследованиям в сельском хозяйстве и биологии, пер. с англ., М., 1961.
Л. Н. Большее.
Математическая энциклопедия. - М.: Советская энциклопедия . И. М. Виноградов . 1977-1985 .
Смотреть что такое "ДИСПЕРСИОННЫЙ АНАЛИЗ" в других словарях:
Метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of… … Википедия
- (analysis of variance) Статистический метод, основанный на разложении общей дисперсии (variance) какой либо характеристики населения на составные части, коррелирующие с другими характеристиками, и остаточную вариацию (residual variation). В… … Экономический словарь
Один из методов математической статистики, применяемый для анализа результатов наблюдений, зависящих от различных, одновременно действующих факторов, к рые не поддаются, как правило, количеств. описанию. Рассмотрим простейшую из задач Д. а. Пусть … Физическая энциклопедия
Дисперсионный анализ - раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента (физического, производственного, экономического эксперимента). Д.а. возник как средство обработки результатов… … Экономико-математический словарь
дисперсионный анализ - — дисперсионный анализ Раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента (физического, производственного,… … Справочник технического переводчика
Все люди от природы стремятся к знанию. (Аристотель. Метафизика)
Дисперсионный анализ
Вводный обзор
В этом разделе мы рассмотрим основные методы, предположения и терминологию дисперсионного анализа.
Отметим, что в англоязычной литературе дисперсионный анализ обычно называется анализом вариации. Поэтому, для краткости, ниже мы иногда будем использовать термин ANOVA (An alysis o f va riation ) для обычного дисперсионного анализа и термин MANOVA для многомерного дисперсионного анализа. В этом разделе мы последовательно рассмотрим основные идеи дисперсионного анализа (ANOVA ), ковариационного анализа (ANCOVA ), многомерного дисперсионного анализа (MANOVA ) и многомерного ковариационного анализа (MANCOVA ). После краткого обсуждения достоинств анализа контрастов и апостериорных критериев рассмотрим предположения, на которых основаны методы дисперсионного анализа. Ближе к концу этого раздела поясняются преимущества многомерного подхода для анализа повторных измерений по сравнению с традиционным одномерным подходом.
Основные идеи
Цель дисперсионного анализа. Основной целью дисперсионного анализа является исследование значимости различия между средними. Глава (глава 8) содержит краткое введение в исследование статистической значимости. Если вы просто сравниваете средние в двух выборках, дисперсионный анализ даст тот же результат, что и обычный t - критерий для независимых выборок (если сравниваются две независимые группы объектов или наблюдений) или t - критерий для зависимых выборок (если сравниваются две переменные на одном и том же множестве объектов или наблюдений). Если вы не достаточно знакомы с этими критериями, рекомендуем обратиться к вводному обзору главы (глава 9).
Откуда произошло название Дисперсионный анализ ? Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними, мы на самом деле анализируем дисперсии.
Разбиение суммы квадратов
Для выборки объема n выборочная дисперсия вычисляется как сумма квадратов отклонений от выборочного среднего, деленная на n-1 (объем выборки минус единица). Таким образом, при фиксированном объеме выборки n дисперсия есть функция суммы квадратов (отклонений), обозначаемая, для краткости, SS (от английского Sum of Squares – Сумма Квадратов). В основе дисперсионного анализа лежит разделение (или разбиение) дисперсии на части. Рассмотрим следующий набор данных:
Средние двух групп существенно различны (2 и 6 соответственно). Сумма квадратов отклонений внутри каждой группы равна 2. Складывая их, получаем 4. Если теперь повторить эти вычисления без учета групповой принадлежности, то есть, если вычислить SS исходя из общего среднего этих двух выборок, то получим 28. Иными словами, дисперсия (сумма квадратов), основанная на внутригрупповой изменчивости, приводит к гораздо меньшим значениям, чем при вычислении на основе общей изменчивости (относительно общего среднего). Причина этого, очевидно, заключается в существенной разнице между средними значениями, и это различие между средними и объясняет существующее различии между суммами квадратов. В самом деле, если использовать для анализа приведенных данных модуль Дисперсионный анализ , будут получены следующие результаты:
Как видно из таблицы, общая сумма квадратов SS =28 разбита на сумму квадратов, обусловленную внутригрупповой изменчивостью (2+2=4 ; см. вторую строку таблицы) и сумму квадратов, обусловленную различием средних значений. (28-(2+2)=24; см первую строку таблицы).
SS ошибок и SS эффекта. Внутригрупповая изменчивость (SS ) обычно называется дисперсией ошибки. Это означает, что обычно при проведении эксперимента она не может быть предсказана или объяснена. С другой стороны, SS эффекта (или межгрупповую изменчивость) можно объяснить различием между средними значениями в изучаемых группах. Иными словами, принадлежность к некоторой группе объясняет межгрупповую изменчивость, т.к. нам известно, что эти группы обладают разными средними значениями.
Проверка значимости. Основные идеи проверки статистической значимости обсуждаются в главе Элементарные понятия статистики (глава 8). В этой же главе объясняются причины, по которым многие критерии используют отношение объясненной и необъясненной дисперсии. Примером такого использования является сам дисперсионный анализ. Проверка значимости в дисперсионном анализе основана на сравнении дисперсии, обусловленной межгрупповым разбросом (называемой средним квадратом эффекта или MS эффект ) и дисперсии, обусловленной внутригрупповым разбросом (называемой средним квадратом ошибки или MS ошибка ). Если верна нулевая гипотеза (равенство средних в двух популяциях), то можно ожидать сравнительно небольшое различие в выборочных средних из-за случайной изменчивости. Поэтому при нулевой гипотезе внутригрупповая дисперсия будет практически совпадать с общей дисперсией, подсчитанной без учета группой принадлежности. Полученные внутригрупповые дисперсии можно сравнить с помощью F - критерия, проверяющего, действительно ли отношение дисперсий значимо больше 1. В рассмотренном выше примере F - критерий показывает, что различие между средними статистически значимо.
Основная логика дисперсионного анализа. Подводя итоги, можно сказать, что целью дисперсионного анализа является проверка статистической значимости разницы между средними (для групп или переменных). Эта проверка проводится с помощью анализа дисперсии, т.е. с помощью разбиения общей дисперсии (вариации) на части, одна из которых обусловлена случайной ошибкой (то есть внутригрупповой изменчивостью), а вторая связана с различием средних значений. Последняя компонента дисперсии затем используется для анализа статистической значимости различия между средними значениями. Если это различие значимо, нулевая гипотеза отвергается и принимается альтернативная гипотеза о существовании различия между средними.
Зависимые и независимые переменные. Переменные, значения которых определяется с помощью измерений в ходе эксперимента (например, балл, набранный при тестировании), называются зависимыми переменными. Переменные, которыми можно управлять при проведении эксперимента (например, методы обучения или другие критерии, позволяющие разделить наблюдения на группы) называются факторами или независимыми переменными. Более подробно эти понятия описаны в главе Элементарные понятия статистики (глава 8).
Многофакторный дисперсионный анализ
В рассмотренном выше простом примере вы могли бы сразу вычислить t-критерий для независимых выборок, используя соответствующую опцию модуля Основные статистики и таблицы. Полученные результаты, естественно, совпадут с результатами дисперсионного анализа. Однако дисперсионный анализ содержит гибкие и мощные технические средства, которые могут быть использованы для гораздо более сложных исследований.
Множество факторов. Мир по своей природе сложен и многомерен. Ситуации, когда некоторое явление полностью описывается одной переменной, чрезвычайно редки. Например, если мы пытаемся научиться выращивать большие помидоры, следует рассматривать факторы, связанные с генетической структурой растений, типом почвы, освещенностью, температурой и т.д. Таким образом, при проведении типичного эксперимента приходится иметь дело с большим количеством факторов. Основная причина, по которой использование дисперсионного анализа предпочтительнее повторного сравнения двух выборок при разных уровнях факторов с помощью t - критерия, заключается в том, что дисперсионный анализ более эффективен и, для малых выборок, более информативен.
Управление факторами. Предположим, что в рассмотренном выше примере анализа двух выборок мы добавим еще один фактор, например, Пол - Gender . Пусть каждая группа состоит из 3 мужчин и 3 женщин. План этого эксперимента можно представить в виде таблицы 2 на 2:
| Эксперимент. Группа 1 | Эксперимент. Группа 2 | |
|---|---|---|
| Мужчины | 2 | 6 |
| 3 | 7 | |
| 1 | 5 | |
| Среднее | 2 | 6 |
| Женщины | 4 | 8 |
| 5 | 9 | |
| 3 | 7 | |
| Среднее | 4 | 8 |
До проведения вычислений, можно заметить, что в этом примере общая дисперсия имеет, по крайней мере, три источника:
(1) случайная ошибка (внутригрупповая дисперсия),
(2) изменчивость, связанная с принадлежностью к экспериментальной группе, и
(3) изменчивость, обусловленная полом объектов наблюдения.
(Отметим, что существует еще один возможный источник изменчивости – взаимодействие факторов , который мы обсудим позднее). Что произойдет, если мы не будем включать пол –gender как фактор при проведении анализа и вычислим обычный t -критерий? Если мы будем вычислять суммы квадратов, игнорируя пол – gender (т.е., объединяя объекты разного пола в одну группу при вычислении внутригрупповой дисперсии, получив при этом сумму квадратов для каждой группы равную SS =10, и общую сумму квадратов SS = 10+10 = 20), то получим большее значение внутригрупповой дисперсии, чем при более точном анализе с дополнительным разбиением на подгруппы по полу - gender (при этом внутригрупповые средние будут равны 2, а общая внутригрупповая сумма квадратов равна SS = 2+2+2+2 = 8). Это различие связано с тем, что среднее значение для мужчин - males меньше, чем среднее значение для женщин – female , и это различие в средних значениях увеличивает суммарную внутригрупповую изменчивость, если фактор пола не учитывается. Управление дисперсией ошибки увеличивает чувствительность (мощность) критерия.
На этом примере видно еще одно преимущество дисперсионного анализа по сравнению с обычным t -критерием для двух выборок. Дисперсионный анализ позволяет изучать каждый фактор, управляя значениями остальных факторов. Это, в действительности, и является основной причиной его большей статистической мощности (для получения значимых результатов требуются меньшие объемы выборок). По этой причине дисперсионный анализ даже на небольших выборках дает статистически более значимые результаты, чем простой t - критерий.
Эффекты взаимодействия
Существует еще одно преимущество применения дисперсионного анализа по сравнению с обычным t - критерием: дисперсионный анализ позволяет обнаружить взаимодействие между факторами и, следовательно, позволяет изучать более сложные модели. Для иллюстрации рассмотрим еще один пример.
Главные эффекты, попарные (двухфакторные) взаимодействия. Предположим, что имеется две группы студентов, причем психологически студенты первой группы настроены на выполнение поставленных задач и более целеустремленны, чем студенты второй группы, состоящей из более ленивых студентов. Разобьем каждую группу случайным образом пополам и предложим одной половине в каждой группе сложное задание, а другой - легкое. После этого измерим, насколько напряженно студенты работают над этими заданиями. Средние значения для этого (вымышленного) исследования показаны в таблице:
Какой вывод можно сделать из этих результатов? Можно ли заключить, что: (1) над сложным заданием студенты трудятся более напряженно; (2) целеустремленные студенты работают упорнее, чем ленивые? Ни одно из этих утверждений не отражает сущность систематического характера средних, приведенных в таблице. Анализируя результаты, правильнее было бы сказать, что над сложными заданиями работают упорнее только целеустремленные студенты, в то время как над легкими заданиями только ленивые работают упорнее. Другими словами характер студентов и сложность задания взаимодействуя между собой влияют на затрачиваемое усилие. Это пример парного взаимодействия между характером студентов и сложностью задания. Отметим, что утверждения 1 и 2 описывают главные эффекты .
Взаимодействия высших порядков. В то время как объяснить попарные взаимодействия еще сравнительно легко, взаимодействия высших порядков объяснить значительно сложнее. Представим себе, что в рассматриваемый выше пример, введен еще один фактор пол -Gender и мы получили следующую таблицу средних значений:
Какие теперь выводы можно сделать из полученных результатов? Графики средних позволяют легко интерпретировать сложные эффекты. Модуль дисперсионного анализа позволяет строить эти графики практически одним щелчком мышки.
Изображение на графиках внизу представляет собой изучаемое трехфакторное взаимодействие.

Глядя на графики, можно сказать, что у женщин существует взаимодействие между характером и сложностью теста: целеустремленные женщины работают над трудным заданием более напряженно, чем над легким. У мужчин это же взаимодействие носит обратный характер. Видно, что описание взаимодействия между факторами становится более запутанным.
Общий способ описания взаимодействий. В общем случае взаимодействие между факторами описывается в виде изменения одного эффекта под воздействием другого. В рассмотренном выше примере двухфакторное взаимодействие можно описать как изменение главного эффекта фактора, характеризующего сложность задачи, под воздействием фактора, описывающего характер студента. Для взаимодействия трех факторов из предыдущего параграфа можно сказать, что взаимодействие двух факторов (сложности задачи и характера студента) изменяется под воздействием пола – Gender . Если изучается взаимодействие четырех факторов, можно сказать, что взаимодействие трех факторов, изменяется под воздействием четвертого фактора, т.е. существуют различные типы взаимодействий на разных уровнях четвертого фактора. Оказалось, что во многих областях взаимодействие пяти или даже большего количества факторов не является чем-то необычным.
Сложные планы
Межгрупповые и внутригрупповые планы (планы с повторными измерениями)
При сравнении двух различных групп обычно используется t - критерий для независимых выборок (из модуля Основные статистики и таблицы ). Когда сравниваются две переменные на одном и том же множестве объектов (наблюдений), используется t -критерий для зависимых выборок. Для дисперсионного анализа также важно зависимы или нет выборки. Если имеются повторные измерения одних и тех же переменных (при разных условиях или в разное время) для одних и тех же объектов , то говорят о наличии фактора повторных измерений (называемого также внутригрупповым фактором, поскольку для оценки его значимости вычисляется внутригрупповая сумма квадратов). Если сравниваются разные группы объектов (например, мужчины и женщины, три штамма бактерий и т.п.), то разница между группами описывается межгрупповым фактором. Способы вычисления критериев значимости для двух описанных типов факторов различны, но общая их логика и интерпретации совпадает.
Меж- и внутригрупповые планы. Во многих случаях эксперимент требует включение в план и межгруппового фактора, и фактора повторных измерений. Например, измеряются математические навыки студентов женского и мужского пола (где пол – Gender -межгрупповой фактор) в начале и в конце семестра. Два измерения навыковкаждого студента образуют внутригрупповой фактор (фактор повторных измерений). Интерпретация главных эффектов и взаимодействий для межгрупповых факторов и факторов повторных измерений совпадает, и оба типа факторов могут, очевидно, взаимодействовать между собой (например, женщины приобретают навыки в течение семестра, а мужчины их теряют).
Неполные (гнездовые) планы
Во многих случаях можно пренебречь эффектом взаимодействия. Это происходит или когда известно, что в популяции эффект взаимодействия отсутствует, или когда осуществление полного факторного плана невозможно. Например, изучается влияние четырех добавок к топливу на расход горючего. Выбираются четыре автомобиля и четыре водителя. Полный факторный эксперимент требует, чтобы каждая комбинация: добавка, водитель, автомобиль - появились хотя бы один раз. Для этого нужно не менее 4 x 4 x 4 = 64 групп испытаний, что требует слишком больших временных затрат. Кроме того, вряд ли существует взаимодействие между водителем и добавкой к топливу. Принимая это во внимание, можно использовать план Латинские квадраты, в котором содержится лишь16 групп испытаний (четыре добавки обозначаются буквами A, B, C и D):
Латинские квадраты описаны в большинстве книг по планированию экспериментов (например, Hays, 1988; Lindman, 1974; Milliken and Johnson, 1984; Winer, 1962), и здесь они не будут детально обсуждаться. Отметим, что латинские квадраты это не n олные планы, в которых участвуют не все комбинации уровней факторов. Например, водитель 1 управляет автомобилем 1 только с добавкой А, водитель 3 управляет автомобилем 1 только с добавкой С. Уровни фактора добавок (A, B, C и D) вложены в ячейки таблицы автомобиль x водитель – как яйца в гнезда. Это мнемоническое правило полезно для понимания природы гнездовых или вложенных планов. Модуль Дисперсионный анализ предоставляет простые способы анализ планов такого типа.
Ковариационный анализ
Основная идея
В разделе Основные идеи кратко обсуждалась идея управления факторами и то, каким образом включение аддитивных факторов позволяет уменьшать сумму квадратов ошибок и увеличивать статистическую мощность плана. Все это может быть распространено и на переменные с непрерывным множеством значений. Когда такие непрерывные переменные включаются в план в качестве факторов, они называются ковариатами .
Фиксированные ковариаты
Предположим, что сравниваются математические навыки двух групп студентов, которые обучались по двум различным учебникам. Предположим также, что имеются данные о коэффициенте интеллекта (IQ) для каждого студента. Можно предположить, что коэффициент интеллекта связан с математическими навыками, и использовать эту информацию. Для каждой из двух групп студентов можно вычислить коэффициент корреляции между IQ и математическими навыками. Используя этот коэффициент корреляции, можно выделить долю дисперсии в группах, объясняемую влиянием IQ и необъясняемую долю дисперсии (см. также Элементарные понятия статистики (глава 8) и Основные статистики и таблицы (глава 9)). Оставшаяся доля дисперсии используется при проведении анализа как дисперсия ошибки. Если имеется корреляция между IQ и математическими навыками, то можно существенно уменьшить дисперсии ошибки SS /(n -1) .
Влияние ковариат на F- критерий. F- критерий оценивает статистическую значимость различия средних значений в группах, при этом вычисляется отношение межгрупповой дисперсии (MS effect ) к дисперсии ошибок (MS error ) . Если MS error уменьшается, например, при учете фактора IQ, значение F увеличивается.
Множество ковариат. Рассуждения, использованные выше для одной ковариаты (IQ), легко распространяются на несколько ковариат. Например, кроме IQ, можно включить измерение мотивации, пространственного мышления и т.д. Вместо обычного коэффициента корреляции при этом используется множественный коэффициент корреляции.
Когда значение F -критерия уменьшается. Иногда введение ковариат в план эксперимента уменьшает значение F -критерия. Обычно это указывает на то, что ковариаты коррелированы не только с зависимой переменной (например, математическими навыками), но и с факторами (например, с разными учебниками). Предположим, что IQ измеряется в конце семестра, после почти годового обучения двух групп студентов по двум разным учебникам. Хотя студенты разбивались на группы случайным образом, может оказаться, что различие учебников настолько велико, что и IQ и математические навыки в разных группах будут сильно различаться. В этом случае, ковариаты не только уменьшают дисперсию ошибок, но и межгрупповую дисперсию. Другими словами, после контроля за разностью IQ в разных группах, разность в математических навыках уже будет несущественной. Можно сказать иначе. После “исключения” влияния IQ, неумышленно исключается и влияние учебника на развитие математических навыков.
Скорректированные средние. Когда ковариата влияет на межгрупповой фактор, следует вычислять скорректированные средние , т.е. такие средние, которые получаются после удаления всех оценок ковариат.
Взаимодействие между ковариатами и факторами. Также как исследуется взаимодействие между факторами, можно исследовать взаимодействие между ковариатами и между группами факторов. Предположим, что один из учебников особенно подходит для умных студентов. Второй учебник для умных студентов скушен, а для менее умных студентов этот же учебник труден. В результате имеется положительная корреляция между IQ и результатом обучения в первой группе (более умные студенты, лучше результат) и нулевая или небольшая отрицательная корреляция во второй группе (чем умнее студент, тем менее вероятно приобретение математических навыков из второго учебника). В некоторых исследованиях эта ситуация обсуждается как пример нарушения предположений ковариационного анализа. Однако так как в модуле Дисперсионный анализ используются самые общие способы ковариационного анализа, можно, в частности, оценить статистическую значимость взаимодействия между факторами и ковариатами.
Переменные ковариаты
В то время как фиксированные ковариаты обсуждаются в учебниках достаточно часто, переменные ковариаты упоминаются намного реже. Обычно, при проведении экспериментов с повторными измерениями, нас интересуют различия в измерениях одних и тех же величин в разные моменты времени. А именно, нас интересует значимость этих различий. Если одновременно с измерениями зависимых переменных проводится измерение ковариат, можно вычислить корреляцию между ковариатой и зависимой переменной.
Например, можно изучать интерес к математике и математические навыки в начале и в конце семестра. Интересно было бы проверить, коррелированы ли между собой изменения в интересе к математике с изменением математических навыков.
Модуль Дисперсионный анализ в STATISTICA автоматически оценивает статистическую значимость изменения ковариат в тех планах, где это возможно.
Многомерные планы: многомерный дисперсионный и ковариационный анализ
Межгрупповые планы
Все рассматриваемые ранее примеры включали только одну зависимую переменную. Когда одновременно имеется несколько зависимых переменных, возрастает лишь сложность вычислений, а содержание и основные принципы не меняются.
Например, проводится исследование двух различных учебников. При этом изучаются успехи студентов в изучении физики и математики. В этом случае имеются две зависимые переменные и нужно выяснить, как влияют на них одновременно два разных учебника. Для этого можно воспользоваться многомерным дисперсионным анализом (MANOVA). Вместо одномерного F критерия, используется многомерный F критерий (l-критерий Уилкса), основанный на сравнении ковариационной матрицы ошибок и межгрупповой ковариационной матрицы.
Если зависимые переменные коррелированы между собой, то эта корреляция должна учитываться при вычислении критерия значимости. Очевидно, если одно и то же измерение повторяется дважды, то ничего нового получить при этом нельзя. Если к имеющемуся измерению добавляется коррелированное с ним измерение, то получается некоторая новая информация, но при этом новая переменная содержит избыточную информацию, которая отражается в ковариации между переменными.
Интерпретация результатов. Если общий многомерный критерий значим, можно заключить, что соответствующий эффект (например, тип учебника) значим. Однако встают следующие вопросы. Влияет ли тип учебника на улучшение только математических навыков, только физических навыков, или одновременно на улучшение тех и других навыков. В действительности, после получения значимого многомерного критерия, для отдельного главного эффекта или взаимодействия исследуется одномерный F критерий. Другими словами, отдельно исследуются зависимые переменные, которые вносят вклад в значимость многомерного критерия.
Планы с повторными измерениями
Если измеряются математические и физические навыки студентов в начале семестра и в конце, то это и есть повторные измерения. Изучение критерия значимости в таких планах это логическое развитие одномерного случая. Заметим, что методы многомерного дисперсионного анализа обычно также используются для исследования значимости одномерных факторов повторных измерений, имеющих более чем два уровня. Соответствующие применения будут рассмотрены позднее в этой части.
Суммирование значений переменных и многомерный дисперсионный анализ
Даже опытные пользователи одномерного и многомерного дисперсионного анализа часто приходят в затруднение, получая разные результаты при применении многомерного дисперсионного анализа, например, для трех переменных, и при применении одномерного дисперсионного анализа к сумме этих трех переменных, как к одной переменной.
Идея суммирования переменных состоит в том, что каждая переменная содержит в себе некоторую истинную переменную, которая и исследуется, а также случайную ошибку измерения. Поэтому при усреднении значений переменных, ошибка измерения будет ближе к 0 для всех измерений и усредненное значений будет более надежным. На самом деле, в этом случае применение дисперсионного анализа к сумме переменных разумно и является мощным методом. Однако если зависимые переменные по своей природе многомерны, суммирование значений переменных неуместно.
Например, пусть зависимые переменные состоят из четырех показателей успеха в обществе . Каждый показатель характеризует совершенно независимую сторону человеческой деятельности (например, профессиональный успех, преуспеваемость в бизнесе, семейное благополучие и т.д.). Сложение этих переменных подобно сложению яблока и апельсина. Сумма этих переменных не будет подходящим одномерным показателем. Поэтому с такими данными нужно обходится как с многомерными показателями в многомерном дисперсионном анализе .
Анализ контрастов и апостериорные критерии
Почему сравниваются отдельные множества средних?
Обычно гипотезы относительно экспериментальных данных формулируются не просто в терминах главных эффектов или взаимодействий. Примером может служить такая гипотеза: некоторый учебник повышает математические навыки только у студентов мужского пола, в то время как другой учебник примерно одинаково эффективен для обоих полов, но все же менее эффективен для мужчин. Можно предсказать, что эффективность учебника взаимодействует с полом студента. Однако этот прогноз касается также природы взаимодействия. Ожидается значительное различие между полами для обучающихся по одной книге и практически не зависимые от пола результаты для обучающихся по другой книге. Такой тип гипотез обычно исследуется с помощью анализа контрастов.
Анализ контрастов
Если говорить коротко, то анализ контрастов позволяет оценивать статистическую значимость некоторых линейных комбинаций эффектов сложного плана. Анализ контрастов главный и обязательный элемент любого сложного плана дисперсионного анализа. Модуль Дисперсионный анализ имеет достаточно разнообразные возможности анализа контрастов, которые позволяют выделять и анализировать любые типы сравнений средних.
Апостериорные сравнения
Иногда в результате обработки эксперимента обнаруживается неожиданный эффект. Хотя в большинстве случаев творческий исследователь сможет объяснить любой результат, это не дает возможностей для дальнейшего анализа и получения оценок для прогноза. Эта проблема является одной из тех, для которых используются апостериорные критерии , то есть критерии, не использующие априорные гипотезы. Для иллюстрации рассмотрим следующий эксперимент. Предположим, что на 100 карточках записаны числа от 1 до 10. Опустив все эти карточки в шапку, мы случайным образом выбираем 20 раз по 5 карточек, и вычисляем для каждой выборки среднее значение (среднее чисел, записанных на карточки). Можно ли ожидать, что найдутся две выборки, у которых средние значения значимо отличаются? Это очень правдоподобно! Выбирая две выборки с максимальным и минимальным средним, можно получить разность средних, сильно отличающуюся от разности средних, например, первых двух выборок. Эту разность можно исследовать, например, с помощью анализа контрастов. Если не вдаваться в детали, то существует несколько, так называемых апостериорных критериев, которые основаны в точности на первом сценарии (взятие экстремальных средних из 20 выборок), т. е. эти критерии основаны на выборе наиболее отличающихся средних для сравнения всехсредних значений в плане. Эти критерии применяются для того, чтобы чисто случайно не получить искусственный эффект, например, обнаружить значимое различие между средними, когда его нет. Модуль Дисперсионный анализ предлагает широкий выбор таких критериев. Когда в эксперименте, связанном с несколькими группами, встречаются неожиданные результаты, то используются апостериорные процедуры для исследования статистической значимости полученных результатов.
Сумма квадратов типа I, II, III и IV
Многомерная регрессия и дисперсионный анализ
Существует тесная взаимосвязь между методом многомерной регрессии и дисперсионным анализом (анализом вариаций). И в том и в другом методе исследуется линейная модель. Если говорить коротко, то практически все планы эксперимента можно исследовать с помощью многомерной регрессии. Рассмотрим следующий простой межгрупповой 2 x 2 план.
| DV | A | B | AxB |
|---|---|---|---|
| 3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 |
| 4 | 1 | -1 | -1 |
| 5 | 1 | -1 | -1 |
| 6 | -1 | 1 | -1 |
| 6 | -1 | 1 | -1 |
| 3 | -1 | -1 | 1 |
| 2 | -1 | -1 | 1 |
Столбцы А и В содержат коды, характеризующие уровни факторов А и В, столбец АxВ содержит произведение двух столбцов А и В. Мы можем анализировать эти данные с помощью многомерной регрессии. Переменная DV определяется как зависимая переменная, переменные от A до AxB как независимые переменные. Исследование значимости для коэффициентов регрессии будет совпадать с вычислениями в дисперсионном анализе значимости главных эффектов факторов A и B и эффекта взаимодействия AxB .
Несбалансированные и сбалансированные планы
При вычислении корреляционной матрицы для всех переменных, например, для данных, изображенных выше, можно заметить, что главные эффекты факторов A и B и эффект взаимодействия AxB некоррелированы. Это свойство эффектов называют также ортогональностью. Говорят, что эффекты A и B - ортогональны или независимы друг от друга. Если все эффекты в плане ортогональны друг другу, как в приведенном выше примере, то говорят, что план сбалансирован .
Сбалансированные планы обладают “хорошим свойством”. Вычисления при анализе таких планов очень просты. Все вычисления сводятся к вычислению корреляции между эффектами и зависимыми переменными. Так как эффекты ортогональны, частные корреляции (как в полной многомерной регрессии) не вычисляются. Однако в реальной жизни планы не всегда сбалансированы.
Рассмотрим реальные данные с неравным числом наблюдений в ячейках.
| Фактор A | Фактор B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | 2 |
Если закодировать эти данные как выше и вычислить корреляционную матрицу для всех переменных, то окажется, что факторы плана коррелированы друг с другом. Факторы в плане теперь не ортогональны и такие планы называются несбалансированными. Заметим, что в рассматриваемом примере, корреляция между факторами полностью связана с различием частот 1 и -1 в столбцах матрицы данных. Другими словами, планы экспериментов с неравными объемами ячеек (точнее, непропорциональными объемами) будут несбалансированными, это означает, что главные эффекты и взаимодействия будут смешиваться. В этом случае для вычисления статистической значимости эффектов нужно полностью вычислять многомерную регрессию. Здесь имеется несколько стратегий.
Сумма квадратов типа I, II, III и IV
Сумма квадратов типа I и III . Для изучения значимости каждого фактора в многомерной модели можно вычислять частную корреляцию каждого фактора, при условии, что все другие факторы уже учтены в модели. Можно также вводить факторы в модель пошаговым способом, фиксируя все факторы, уже введенные в модель и игнорируя все остальные факторы. Вообще, в этом и состоит различие между типом III и типом I суммы квадратов (эта терминология была введена в SAS, см. например, SAS, 1982; подробное обсуждение можно также найти в Searle, 1987, стр. 461; Woodward, Bonett, and Brecht, 1990, стр. 216; или Milliken and Johnson, 1984, стр. 138).
Сумма квадратов типа II. Следующая “промежуточная” стратегия формирования модели состоит: в контроле всех главных эффектов при исследовании значимости отдельного главного эффекта; в контроле всех главных эффектов и всех попарных взаимодействий, когда исследуется значимость отдельного попарного взаимодействия; в контроле всех главных эффектов всех попарных взаимодействий и всех взаимодействий трех факторов; при исследовании отдельного взаимодействия трех факторов и т.д. Суммы квадратов для эффектов, вычисляемые таким способом, называются типом II суммы квадратов. Итак, тип II суммы квадратов контролирует все эффекты того же порядка и ниже, игнорируя все эффекты более высокого порядка.
Сумма квадратов типа IV . Наконец, для некоторых специальных планов с пропущенными ячейками (неполными планами) можно вычислять, так называемые, типа IV суммы квадратов. Этот метод будет обсуждаться позднее в связи с неполными планами (планами с пропущенными ячейками).
Интерпретация гипотезы о сумме квадратов типа I, II, и III
Сумму квадратов типа III легче всего интерпретировать. Напомним, что суммы квадратов типа III исследуют эффекты после контроля всех других эффектов. Например, после нахождения статистически значимого типа III эффекта для фактора A в модуле Дисперсионный анализ , можно сказать, что существует единственный значимый эффект фактора A , после введения всех других эффектов (факторов) и соответственно интерпретировать этот эффект. Вероятно в 99% всех приложений дисперсионного анализа именно этот тип критерия интересует исследователя. Этот тип суммы квадратов обычно вычисляется в модуле Дисперсионный анализ по умолчанию, независимо от того выбрана опция Регрессионный подход или нет (стандартные подходы принятые в модуле Дисперсионный анализ обсуждаются ниже).
Значимые эффекты, полученные с помощью сумм квадратов типа или типа II суммы квадратов интерпретировать не так легко. Лучше всего их интерпретировать в контексте пошаговой многомерной регрессии. Если при использовании суммы квадратов типа I главный эффект фактора В оказался значим (после включения в модель фактора А, но перед добавлением взаимодействия между А и В), можно заключить, что существует значимый главный эффект фактора В, при условии, что нет взаимодействия между факторами А и В. (Если при использовании критерия типа III , фактор В также оказался значимым, то можно заключить, что существует значимый главный эффект фактора B, после введения в модель всех других факторов и их взаимодействий).
В терминах маргинальных средних гипотезы типа I и типа II обычно не имеют простой интерпретации. В этих случаях говорят, что нельзя интерпретировать значимость эффектов, рассматривая только маргинальные средние. Скорее представленные p значений средних имеют отношение к сложной гипотезе, которая комбинирует средние и объем выборки. Например, тип II гипотезы для фактора А в простом примере плана 2 x 2, рассматриваемом ранее будут (см. Woodward, Bonett, and Brecht, 1990, стр. 219):
nij - число наблюдений в ячейке
uij - среднее значение в ячейке
n . j - маргинальное среднее
Если не вдаваться в детали (более подробно см. Milliken and Johnson, 1984, глава 10), то ясно, что это не простые гипотезы и в большинстве случаев ни одна из них не представляет особенного интереса у исследователя. Однако существуют случаи, когда гипотезы типа I могут быть интересны.
Принимаемый по умолчанию вычислительный подход в модуле Дисперсионный анализ
По умолчанию, если не отмечена опция Регрессионный подход , модуль Дисперсионный анализ использует модель средних по ячейкам . Для этой модели характерно, что суммы квадратов для разных эффектов вычисляются для линейных комбинаций средних значений по ячейкам. В полном факторном эксперименте это приводит к суммам квадратов, которые совпадают с суммами квадратов, обсуждаемыми ранее как тип III . Однако в опции Спланированные сравнения (в окне Результаты дисперсионного анализа ), пользователь может проверять гипотезу относительно любой линейной комбинации взвешенных или невзвешенных средних по ячейкам. Таким образом, пользователь может проверять не только гипотезы типа III , но гипотезы любого типа (включая тип IV ). Этот общий подход особенно полезен, когда исследуются планы с пропущенными ячейками (так называемые неполные планы).
Для полных факторных планов этот подход полезно также использовать в тех случаях, когда хотят анализировать взвешенные маргинальные средние. Например, предположим, что в рассматриваемом ранее простом 2 x 2 плане, нужно сравнить взвешенные (по уровням фактора B ) маргинальные средние для фактора А. Это бывает полезным, когда распределение наблюдений по ячейкам не готовилось экспериментатором, а строилось случайно, и эта случайность отражается в распределении числа наблюдений по уровням фактора B в совокупности.
Например, имеется фактор - возраст вдов. Возможная выборка респондентов разбита на две группы: моложе 40 лет и старше 40 (фактор В). Второй фактор (фактор А) в плане - получали или нет социальную поддержку вдовы в некотором агентстве (при этом одни вдовы были выбраны случайно, другие служили в качестве контроля). В этом случае распределение вдов по возрастам в выборке отражает действительное распределение вдов по возрастам в совокупности. Оценке эффективности группы социальной поддержки вдов по всем возрастам будет соответствовать взвешенное среднее для двух возрастных групп (с весами соответствующими числу наблюдений в группе).
Спланированные сравнения
Заметим, что сумма введенных коэффициентов контрастов не обязательно равна 0 (нулю). Вместо этого программа будет автоматически вносить поправки, чтобы соответствующие гипотезы не смешивались с общим средним.
Для иллюстрации этого вернемся опять к простому 2 x 2 плану, рассмотренному ранее. Напомним, что числа наблюдений в ячейках этого несбалансированного плана -1, 2, 3, и 1. Предположим, что мы хотим сравнить взвешенные маргинальные средние для фактора А (взвешенные с частотой уровней фактора В). Можно ввести коэффициенты контраста:
Заметим, что эти коэффициенты не дают в сумме 0. Программа будет устанавливать коэффициенты так, что в сумме они будут давать 0, и при этом будут сохраняться их относительные значения, т. е.:
1/3 2/3 -3/4 -1/4
Эти контрасты будут сравнивать взвешенные средние для фактора А.
Гипотезы о главном среднем. Гипотеза, о том, что не взвешенное главное среднее равно 0 может исследоваться с помощью коэффициентов:
Гипотеза о том, что взвешенное главное среднее равно 0 проверяется с помощью:
Ни в одном случае программа не производит корректировки коэффициентов контрастов.
Анализ планов с пропущенными ячейками (неполные планы)
Факторные планы, содержащие пустые ячейки (обработка комбинаций ячеек, в которых нет наблюдений) называются неполными. В таких планах некоторые факторы обычно не ортогональны и некоторые взаимодействия не могут быть вычислены. Вообще не существует лучшего метода анализа таких планов.
Регрессионный подход
В некоторых старых программах, которые основаны на анализе планов дисперсионного анализа с помощью многомерной регрессии, факторы в неполных планах по умолчанию задаются обычным образом (как будто план полный). Затем производится многомерный регрессионный анализ для этих фиктивно закодированных факторов. К несчастью, этот метод приводит к результатам, которые очень трудно, или даже невозможно, интерпретировать, так как неясно, как каждый эффект участвует в линейной комбинации средних значений. Рассмотрим следующий простой пример.
| Фактор A | Фактор B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | Пропущено |
Если будет выполняться многомерная регрессия вида Зависимая переменная = Константа + Фактор A + Фактор B , то гипотеза о значимости факторов A и B в терминах линейных комбинаций средних выглядит так:
Фактор A: Ячейка A1,B1 = Ячейка A2,B1
Фактор B: Ячейка A1,B1 = Ячейка A1,B2
Этот случай прост. В более сложных планах невозможно фактически определить, что точно будет исследоваться.
Средние ячеек, подход дисперсионного анализа, гипотезы типа IV
Подход, который рекомендуется в литературе и который кажется предпочтительнее - исследование осмысленных (с точки зрения исследовательских задач) априорных гипотез о средних, наблюдаемых в ячейках плана. Подробное обсуждение этого подхода можно найти в Dodge (1985), Heiberger (1989), Milliken and Johnson (1984), Searle (1987), или Woodward, Bonett, and Brecht (1990). Суммы квадратов, ассоциированные с гипотезами о линейной комбинации средних в неполных планах, исследующие оценки части эффектов, называются также суммами квадратов IV .
Автоматическая генерация гипотез типа IV . Когда многофакторные планы имеют сложный характер пропущенных ячеек, желательно определить ортогональные (независимые) гипотезы, исследование которых эквивалентно исследованию главных эффектов или взаимодействий. Были развиты алгоритмические (вычислительные) стратегии (основанные на псевдообратной матрице плана) для генерирования подходящих весов для таких сравнений. К сожалению, окончательные гипотезы определяются не единственным образом. Конечно, они зависят от порядка, в котором эффекты были определены и редко допускают простую интерпретацию. Поэтому рекомендуется внимательно изучить характер пропущенных ячеек, затем формулировать гипотезы типа IV , которые наиболее содержательно соответствуют целям исследования. Затем исследовать эти гипотезы, используя опцию Спланированные сравнения в окне Результаты . Самый легкий путь задать сравнения в этом случае - требовать введения вектора контрастов для всех факторов вместе в окне Спланированные сравнения. После вызова диалогового окна Спланированные сравнения будут показаны все группы текущего плана и помечены те, которые пропущены.
Пропущенные ячейки и проверка специфического эффекта
Существует несколько типов планов, в которых расположение пропущенных ячеек не случайно, но тщательно спланировано, что позволяет проводить простой анализ главных эффектов не затрагивая другие эффекты. Например, когда необходимое число ячеек в плане недоступно, часто используются планы Латинские квадраты для оценивания главных эффектов нескольких факторов с большим числом уровней. Например, 4 x 4 x 4 x 4 факторный план требует 256 ячеек. В то же время можно использовать Греко-латинский квадрат для оценки главных эффектов, имея только 16 ячеек в плане (глава Планирование эксперимента , том IV, содержит детальное описание таких планов). Неполные планы, в которых главные эффекты (и некоторые взаимодействия) могут быть оценены с помощью простых линейных комбинаций средних, называются сбалансированными неполными планами .
В сбалансированных планах стандартный (по умолчанию) метод генерирования контрастов (весов) для главных эффектов и взаимодействий будет затем производить анализ таблицы дисперсий, в которой суммы квадратов для соответствующих эффектов не смешиваются друг с другом. Опция Специфический эффекты окна Результаты будет генерировать пропущенные контрасты, записывая ноль в пропущенные ячейки плана. Сразу после того, как будет запрошена опция Специфический эффекты для пользователя, изучающего некоторую гипотезу, появляется таблица результатов с фактическими весами. Заметим, что в сбалансированном плане, суммы квадратов соответствующих эффектов вычисляются только, если эти эффекты ортогональны (независимы) всем другим главным эффектам и взаимодействиям. В противном случае нужно воспользоваться опцией Спланированные сравнения для изучения содержательных сравнений между средними.
Пропущенные ячейки и объединенные эффекты/члены ошибки
Если опция Регрессионное подход в стартовой панели модуля Дисперсионный анализ не выбрана, то при вычислении суммы квадратов для эффектов будет использоваться модель средних по ячейкам (установка по умолчанию). Если план не сбалансирован, то при объединении неортогональных эффектов (см. выше обсуждение опции Пропущенные ячейки и специфический эффект ) можно получить сумму квадратов, состоящую из неортогональных (или перекрывающихся) компонент. Полученные при этом результаты, обычно не интерпретируемы. Поэтому нужно быть очень осторожным при выборе и реализации сложных неполных экспериментальных планов.
Существует много книг с детальным обсуждением планов разного типа. (Dodge, 1985; Heiberger, 1989; Lindman, 1974; Milliken and Johnson, 1984; Searle, 1987; Woodward and Bonett, 1990), но такого рода информация лежит вне границ этого учебника. Тем не менее, позднее в этом разделе будет продемонстрирован анализ различного типа планов.
Предположения и эффекты нарушения предположений
Отклонение от предположения о нормальности распределений
Предположим, что зависимая переменная измерена в числовой шкале. Предположим также, что зависимая переменная имеет нормальное распределение внутри каждой группы. Дисперсионный анализ содержит широкий набор графиков и статистик для обоснования этого предположения.
Эффекты нарушения. Вообще F критерий очень устойчив к отклонению от нормальности (подробные результаты см. в работе Lindman, 1974). Если эксцесс больше 0, то значение статистики F может стать очень маленьким. Нулевая гипотеза при этом принимается, хотя она может быть и не верна. Ситуация меняется на противоположную, когда эксцесс меньше 0. Асимметрия распределения обычно незначительно влияет на F статистику. Если число наблюдений в ячейке достаточно большое, то отклонение от нормальности не имеет особого значения в силу центральной предельной теоремы , в соответствии с которой, распределение среднего значения близко к нормальному, независимо от начального распределения. Подробное обсуждение устойчивости F статистики можно найти в Box and Anderson (1955), или Lindman (1974).
Однородность дисперсии
Предположения. Предполагается, что дисперсии разных групп плана одинаковы. Это предположение называется предположением об однородности дисперсии. Вспомним, что в начале этого раздела, описывая вычисление суммы квадратов ошибок, мы производили суммирование внутри каждой группы. Если дисперсии в двух группах отличаются друг от друга, то сложение их не очень естественно и не дает оценки общей внутригрупповой дисперсии (так как в этом случае общей дисперсии вообще не существует). Модуль Дисперсионный анализ - ANOVA /MANOVA содержит большой набор статистических критериев обнаружения отклонения от предположений однородности дисперсии.
Эффекты нарушения. Линдман (Lindman 1974, стр. 33) показывает, что F критерий вполне устойчив относительно нарушения предположений однородности дисперсии (неоднородность дисперсии, см. также Box, 1954a, 1954b; Hsu, 1938).
Специальный случай: коррелированность средних и дисперсий. Бывают случаи, когда F статистика может вводить в заблуждение. Это бывает, когда в ячейках плана средние значения коррелированы с дисперсией. Модуль Дисперсионный анализ позволяет строить диаграммы рассеяния дисперсии или стандартного отклонения относительно средних для обнаружения такой корреляции. Причина, по которой такая корреляция опасна, состоит в следующем. Представим себе, что имеется 8 ячеек в плане, 7 из которых имеют почти одинаковое среднее, а в одной ячейке среднее намного больше остальных. Тогда F критерий может обнаружить статистически значимый эффект. Но предположим, что в ячейке с большим средним значением и дисперсия значительно больше остальных, т.е. среднее значение и дисперсия в ячейках зависимы (чем больше среднее, тем больше дисперсия). В этом случае большое среднее значение ненадежно, так как оно может быть вызвано большой дисперсией данных. Однако F статистика, основанная на объединенной дисперсии внутри ячеек, будет фиксировать большое среднее, хотя критерии, основанные на дисперсии в каждой ячейке, не все различия в средних будут считать значимыми.
Такой характер данных (большое среднее и большая дисперсия) - часто встречается, когда имеются резко выделяющиеся наблюдения. Одно или два резко выделяющихся наблюдений сильно смещают среднее значение и очень увеличивают дисперсию.
Однородность дисперсии и ковариаций
Предположения. В многомерных планах, с многомерными зависимыми измерениями, также применяются предположение об однородности дисперсии, описанные ранее. Однако так как существуют многомерные зависимые переменные, то требуется так же чтобы их взаимные корреляции (ковариации) были однородны по всем ячейкам плана. Модуль Дисперсионный анализ предлагает разные способы проверки этих предположений.
Эффекты нарушения . Многомерный аналог F - критерия - λ-критерий Уилкса. Не так много известно об устойчивости (робастности) λ-критерия Уилкса относительно нарушения указанных выше предположений. Тем не менее, так как интерпретация результатов модуля Дисперсионный анализ основывается обычно на значимости одномерных эффектов (после установления значимости общего критерия), обсуждение робастности касается, в основном, одномерного дисперсионного анализа. Поэтому должна быть внимательно исследована значимость одномерных эффектов.
Специальный случай: ковариационный анализ. Особенно серьезные нарушения однородности дисперсии/ковариаций могут происходить, когда в план включаются ковариаты. В частности, если корреляция между ковариатами и зависимыми измерениями различна в разных ячейках плана, может последовать неверное истолкование результатов. Следует помнить, что в ковариационном анализе, в сущности, проводится регрессионный анализ внутри каждой ячейки для того, чтобы выделить ту часть дисперсии, которая соответствует ковариате. Предположение об однородности дисперсии/ковариации предполагает, что этот регрессионный анализ проводится при следующем ограничении: все регрессионные уравнения (наклоны) для всех ячеек одинаковы. Если это не предполагается, то могут появиться большие ошибки. Модуль Дисперсионный анализ имеет несколько специальных критериев для проверки этого предположения. Можно посоветовать использовать эти критерии, для того, чтобы убедиться, что регрессионные уравнения для различных ячеек примерно одинаковы.
Сферичность и сложная симметрия: причины использования многомерного подхода к повторным измерениям в дисперсионном анализе
В планах, содержащих факторы повторных измерений с более чем двумя уровнями, применение одномерного дисперсионного анализа требует дополнительных предположений: предположения о сложной симметрии и предположения о сферичности. Эти предположения редко выполняются (см. ниже). Поэтому в последние годы многомерный дисперсионный анализ завоевал популярность в таких планах (оба подхода совмещены в модуле Дисперсионный анализ ).
Предположение о сложной симметрии Предположение о сложной симметрии состоит в том, что дисперсии (общие внутригрупповые) и ковариации (по группам) для различных повторных измерений однородны (одинаковы). Это достаточное условие для того, чтобы одномерный F критерий для повторных измерений был обоснованным (т.е. выданные F-значения в среднем соответствовали F-распределению). Однако в данном случае это условие не является необходимым.
Предположение о сферичности. Предположение о сферичности является необходимым и достаточным условием того, чтобы F-критерий был обоснованным. Оно состоит в том, что внутри групп все наблюдения независимы и одинаково распределены. Природа этих предположений, а также влияние их нарушений обычно не очень хорошо описаны в книгах по дисперсионному анализу - эта будет описано в следующих параграфах. Там же будет показано, что результаты одномерного подхода могут отличаться от результатов многомерного подхода, и будет объяснено, что это означает.
Необходимость независимости гипотез. Общий способ анализа данных в дисперсионном анализе – это подгонка модели . Если относительно модели, соответствующей данным, имеются некоторые априорные гипотезы, то дисперсия разбивается для проверки этих гипотез (критерии главных эффектов, взаимодействий). С точки зрения вычислений, этот подход генерирует некоторое множество контрастов (множество сравнений средних в плане). Однако если контрасты не независимы друг от друга, разбиение дисперсий становится бессодержательным. Например, если два контраста A и B тождественны и выделяется соответствующая им часть из дисперсии, то одна и та же часть выделяется дважды. Например, глупо и бессмысленно выделять две гипотезы: “среднее в ячейке 1 выше среднего в ячейке 2” и “среднее в ячейке 1 выше среднего в ячейке 2”. Итак, гипотезы должны быть независимы или ортогональны.
Независимые гипотезы при повторных измерениях. Общий алгоритм, реализованный в модуле Дисперсионный анализ , будет пытаться для каждого эффекта генерировать независимые (ортогональные) контрасты. Для фактора повторных измерений эти контрасты задают множество гипотез относительно разностей между уровнями рассматриваемого фактора. Однако если эти разности коррелированы внутри групп, то результирующие контрасты не являются больше независимыми. Например, в обучении, где обучающиеся измеряются три раза за один семестр, может случиться, что изменения между 1 и 2 измерением отрицательно коррелируют с изменением между 2 и 3 измерениями субъектов. Те, кто большую часть материала освоил между 1 и 2 измерениями, осваивают меньшую часть в течение того времени, которое прошло между 2 и 3 измерением. В действительности, для большинства случаев, где дисперсионный анализ используются при повторных измерениях, можно предположить, что изменения по уровням коррелированы по субъектам. Однако когда это случается, предположение о сложной симметрии и предположения о сферичности не выполняются и независимые контрасты не могут быть вычислены.
Влияние нарушений и способы их исправления. Когда предположения о сложной симметрии или о сферичности не выполняются, дисперсионный анализ может выдать ошибочные результаты. До того, как были достаточно разработаны многомерные процедуры, было предложено несколько предположений для компенсации нарушений этих предположений. (см., например, работы Greenhouse & Geisser, 1959 и Huynh & Feldt, 1970). Эти методы до сих пор широко используются (поэтому они представлены в модуле Дисперсионный анализ ).
Подход многомерного дисперсионного анализа к повторным измерениям. В целом проблемы сложной симметрии и сферичности относятся к тому факту, что множества контрастов, включенных в исследование эффектов факторов повторных измерений (с числом уровней большим, чем 2) не независимы друг от друга. Однако им не обязательно быть независимыми, если используется многомерный критерий для одновременной проверки статистического значимости двух или более контрастов фактора повторных измерений. Это является причиной того, что методы многомерного дисперсионного анализа стали чаще использоваться для проверки значимости факторов одномерных повторных измерений с более чем 2 уровнями. Этот подход широко распространен, так как он, в общем случае, не требует предположения о сложной симметрии и предположения о сферичности.
Случаи, в которых подходмногомерного дисперсионного анализа не может быть использован. Существуют примеры (планы), когда подход многомерного дисперсионного анализа не может быть применен. Обычно это случаи, когда имеется небольшое количество субъектов в плане и много уровней в факторе повторных измерений. Тогда для проведения многомерного анализа может быть слишком мало наблюдений. Например, если имеется 12 субъектов, p = 4 фактора повторных измерений, и каждый фактор имеет k = 3 уровней. Тогда взаимодействие 4-х факторов будет “расходовать”(k -1)P = 2 4 = 16 степеней свободы. Однако имеется лишь 12 субъектов, следовательно, в этом примере многомерный тест не может быть проведен. Модуль Дисперсионный анализ самостоятельно обнаружит эти наблюдения и вычислит только одномерные критерии.
Различия в одномерных и многомерных результатах. Если исследование включает большое количество повторных измерений, могут возникнуть случаи, когда одномерный подход дисперсионного анализа к повторным измерениям дает результаты, сильно отличающиеся от тех, которые были получены при многомерном подходе. Это означает, что разности между уровнями соответствующих повторных измерений коррелированы по субъектам. Иногда этот факт представляет некоторый самостоятельный интерес.
Многомерный дисперсионный анализ и структурное моделирование уравнений
В последние годы моделирование структурных уравнений стало популярным, как альтернатива многомерному анализу дисперсии (см. например, Bagozzi and Yi, 1989; Bagozzi, Yi, and Singh, 1991; Cole, Maxwell, Arvey, and Salas, 1993). Этот подход позволяет проверять гипотезы не только о средних в разных группах, но так же и о корреляционных матрицах зависимых переменных. Например, можно ослабить предположения об однородности дисперсии и ковариаций и явно включить в модель для каждой группы дисперсии и ковариации ошибки. Модуль STATISTICA Моделирование структурными уравнениями (SEPATH ) (см. том III) позволяет проводить такой анализ.
Рассмотренные выше приемы проверки статистических гипотез о существенности различий между двумя средними на практике имеют ограниченное применение. Это связано с тем, что для выявления действия всех возможных условий и факторов на результативный признак полевые и лабораторные опыты, как правило, проводят с использованием не двух, а большего числа выборок (1220 и более).
Часто исследователи сравнивают средние нескольких выборок, объединенных в единый комплекс. Например, изучая влияние различных видов и доз удобрений на урожайность сельскохозяйственных культур опыты повторяют в разных вариантах. В этих случаях попарные сравнения становятся громоздкими, а статистический анализ всего комплекса требует применения особого метода. Такой метод, разработанный в математической статистике, получил название дисперсионного анализа. Впервые его применил английский статистик Р. Фишер при обработке результатов агрономических опытов (1938 г.).
Дисперсионный анализ - это метод статистической оценки надежности проявления зависимости результативного признака от одного или нескольких факторов. С помощью метода дисперсионного анализа проводится проверка статистических гипотез относительно средних в нескольких генеральных совокупностях, имеющих нормальное распределение.
Дисперсионный анализ является одним из основных методов статистической оценки результатов эксперимента. Все более широкое применение получает он и в анализе экономической информации. Дисперсионный анализ дает возможность установить, насколько выборочные показатели связи результативного и факторных признаков достаточны для распространения полученных по выборке данных на генеральную совокупность. Достоинством этого метода является то, что он дает достаточно надежные выводы по выборкам небольшого численности.
Исследуя вариацию результативного признака под влиянием одного или нескольких факторов с помощью дисперсионного анализа можно получить помимо общих оценок существенности зависимостей, также и оценку различий в величине средних, которые формируются при различных уровнях факторов, и существенности взаимодействия факторов. Дисперсионный анализ применяется для изучения зависимостей как количественных, так и качественных признаков, а также при их сочетании.
Суть этого метода заключается в статистическом изучении вероятности влияния одного или нескольких факторов, а также их взаимодействия на результативный признак. Согласно этого с помощью дисперсионного анализа решаются три основных задачи: 1) общая оценка существенности различий между групповыми средними; 2) оценка вероятности взаимодействия факторов; 3) оценка существенности различий между парами средних. Чаще всего такие задачи приходится решать исследователям при проведении полевых и зоотехнических опытов, когда изучается влияние нескольких факторов на результативный признак.
Принципиальная схема дисперсионного анализа включает установление основных источников варьирование результативного признака и определение объемов вариации (сумм квадратов отклонений) по источникам ее образования; определение числа степеней свободы, соответствующих компонентам общей вариации; вычисления дисперсий как отношение соответствующих объемов вариации к их числу степеней свободы; анализ соотношения между дисперсиями; оценка достоверности разницы между средними и формулирование выводов.
Указанная схема сохраняется как при простых моделях дисперсионного анализа, когда данные группируются по одному признаку, так и при сложных моделях, когда данные группируются по двумя и большим числом признаков. Однако с увеличением числа групповых признаков усложняется процесс разложение общей вариации по источникам ее образования.
Согласно принципиальной схемы дисперсионный анализ можно представить в виде пяти последовательно выполняемых этапов:
1) определение и разложения вариации;
2) определение числа степеней свободы вариации;
3) вычисление дисперсий и их соотношений;
4) анализ дисперсий и их соотношений;
5) оценка достоверности разницы между средними и формулировка выводов по проверке нулевой гипотезы.
Наиболее трудоемкой частью дисперсионного анализа является первый этап - определение и разложения вариации по источникам ее образования. Порядок разложения общего объема вариации подробно рассматривался в главе 5.
В основе решения задач дисперсионного анализа лежит закон разложения (добавление) вариации, согласно которого общая вариация (колебания) результативного признака делится на две: вариацию, обусловленную действием исследуемого фактора (факторов), и вариацию, вызванную действием случайных причин, то есть
Предположим, что исследуемая совокупность поделена по факторным признаком на несколько групп, каждая из которых характеризуется своей средней величине результативного признака. При этом вариацию этих величин можно объяснить двумя видами причин: такими, которые действуют на результативный признак систематически и поддаются регулировке в ходе проводимого эксперимента и регулировке не поддаются. Очевидно, что межгрупповая (факторная или систематическая) вариация зависит преимущественно от действия исследуемого фактора, а внутригрупповая (остаточная или случайная) - от действия случайных факторов.
Чтобы оценить достоверность различий между групповыми средними, необходимо определить межгрупповую и внутригрупповое вариации. Если межгрупповая (факторная) вариация значительно превышает внутригрупповое (остаточную) вариацию, то фактор влиял на результативный признак, существенно изменяя значения групповых средних величин. Но возникает вопрос, каково соотношение между міжгруповою и внутрішньогруповою вариациями можно рассматривать как достаточное для вывода о достоверности (существенности) различий между групповыми средними.
Для оценки существенности различий между средними и формулировка выводов по проверке нулевой гипотезы (Н0:х1 = х2 =... = хп) в дисперсионном анализе используется своеобразный норматив - Г-критерий, закон распределения которого установил Р.фишер. Этот критерий представляет собой отношение двух дисперсий: факторного, порождаемой действием изучаемого фактора, и остаточной, обусловленной действием случайных причин:
![]()
Дисперсионное отношение Г= £>и : £*2 американским статистиком Снедекором предложено обозначать буквой Г в честь изобретателя дисперсионного анализа Р.Фішера.
Дисперсии °2 іо2 являются оценками дисперсии генеральной совокупности. Если выборки с дисперсиями °2 °2 сделаны из одной и той же генеральной совокупности, где вариация величин имела случайный характер, то расхождение в величинах °2 °2 также случайна.
Если в эксперименте проверяют влияние нескольких факторов (А, В, С и т.д.) на результативный признак одновременно, то дисперсия, обусловленная действием каждого из них, должна быть сравнима с °е.гР , то есть
Если значение факторной дисперсии значительно больше остаточной, то фактор существенно влиял на результативный признак и наоборот.
В многофакторных экспериментах кроме вариации, обусловленной действием каждого фактора, практически всегда есть вариация, обусловленная взаимодействием факторов ($ав: ^лс ^вс $лііс). Суть взаимодействия заключается в том, что эффект одного фактора существенно меняется на разных уровнях второго (например, эффективность качества Почвы при разных дозах удобрений).
Взаимодействие факторов также должна быть оценена путем сравнения соответствующих дисперсий 3 ^в.гр:

При исчислении фактического значения Б-критерия в числителе берется большая из дисперсий, поэтому Б > 1. Очевидно, что чем больше критерий Бы, тем значительнее различия между дисперсиями. Если Б = 1, то вопрос об оценке существенности различий дисперсий снимается.
Для определения пределов случайных колебаний отношение дисперсий Г. Фишер разработал специальные таблицы Б-распределения (прил. 4 и 5). Критерий Бы функционально связанный с вероятностью и зависит от числа степеней свободы вариации к1 и к2 двух сравниваемых дисперсий. Обычно используются две таблицы, позволяющие делать выводы о предельно высокое значение критерия для уровней значимости 0,05 и 0,01. Уровень значимости 0,05 (или 5%) означает, что только в 5 случаях из 100 критерий Б может принимать значение, равное указанному в таблице или выше его. Снижение уровня значимости с 0,05 до 0,01 приводит к увеличению значения критерия Бы между двумя дисперсиями в силу действия только случайных причин.
Значение критерия также зависит непосредственно от числа степеней свободы двух сравниваемых дисперсий. Если число степеней свободы стремится к бесконечности (к-ме), то отношение Бы для двух дисперсий стремится к единице.
Табличное значение критерия Б показывает возможную случайную величину отношения двух дисперсий при заданном уровне значимости и соответствующем числе степеней свободы для каждой из сравниваемых дисперсий. В указанных таблицах приводится величина Б для выборок, сделанных из одной и той же генеральной совокупности, где причины изменения величин только случайные.
Значение Г находят по таблицам (прил. 4 и 5) на пересечении соответствующего столбца (число степеней свободы для большей дисперсии - к1) и строки (число степеней свободы для меньшей дисперсии - к2). Так, если большей дисперсии (числитель Г) к1 = 4, а меньшей (знаменатель Г) к2 = 9, то Га при уровне значимости а = 0,05 составит 3,63 (прил. 4). Итак, в результате действия случайных причин, поскольку малочисленные выборки, дисперсия одной выборки может при 5%-ном уровне значимости превышать дисперсию для второй выборки в 3,63 раза. При снижении уровня значимости с 0,05 до 0,01 табличное значение критерия Г, как отмечалось выше, будет увеличиваться. Так, при тех же степенях свободы к1 = 4 и к2 = 9 и а = 0,01 табличное значение критерия Г составит 6,99 (прил. 5).
Рассмотрим порядок определения числа степеней свободы в дисперсионном анализе. Число степеней свободы, что соответствует общей сумме квадратов отклонений, раскладывается на соответствующие компоненты аналогично разложению сумм квадратов отклонений (^общ = №^гр + ]¥вхр) , то есть общее число степеней свободы (к") раскладывается на число степеней свободы для межгрупповой (к1) и внутригрупповой (к2) вариаций.
Так, если выборочная совокупность, состоящая из N наблюдений, деленная на т групп (число вариантов опыта) и п подгрупп (количество повторностей), то число степеней свободы к соответственно составит:
а) для общей суммы квадратов отклонений (й7заг)
б) для межгрупповой суммы квадратов отклонений ^м.гР)
в) для внутригрупповой суммы квадратов отклонений в в.гР)
Согласно правилу сложения вариации:
Например, если в опыте было сформировано четыре варианта опыта (т = 4) в пяти повторностях каждый (п = 5), и общее количество наблюдений N = = т o п = 4 * 5 = 20, то число степеней свободы соответственно равно:

Зная суммы квадратов отклонений число степеней свободы, можно определить несмещенные (скорректированные) оценки для трех дисперсий:

Нулевую гипотезу Н0 по критерию Б проверяют так же, как и по и-критерию Стьюдента. Чтобы принять решение по проверки Н0, необходимо рассчитать фактическое значение критерия и сравнить его с табличным значением Ба для принятого уровня значимости а и числа степеней свободы к1 и к2 для двух дисперсий.
Если Бфакг > Ба, то в соответствии с принятым уровнем значимости можно сделать вывод, что различия выборочных дисперсий определяются не только случайными факторами; они существенные. Нулевую гипотезу в этом случае отклоняют и есть основание утверждать, что фактор существенно влияет на результативный признак. Если же < Ба, то нулевую гипотезу принимают и есть основание утверждать, что различия между сравниваемыми дисперсиями находятся в границах возможных случайных колебаний: действие фактора на результативный признак не является существенным.
Применение той или иной модели дисперсионного анализа зависит как от количества изучаемых факторов, так и от способа формирования выборок.
в Зависимости от количества факторов, определяющих вариацию результативного признака, выборки могут быть сформированы по одним, двумя и большим числом факторов. Согласно этому дисперсионный анализ делится на однофакторный и многофакторный. Иначе его еще называют однофакторним и многофакторным дисперсионным комплексом.
Схема разложение общей вариации зависит от формирования групп. Оно может быть случайным (наблюдение одной группы не связаны с наблюдениями второй группы) и неслучайным (наблюдение двух выборок связаны между собой общностью условий эксперимента). Соответственно получают независимые и зависимые выборки. Независимые выборки могут быть сформированы как с ровной, так и неровной численностью. Формирование зависимых выборок предполагает их равную численность.
Если группы сформированы в невипадковому порядке, то общий объем вариации результативного признака включает в себя наряду с факторным (міжгруповою) и остаточной вариацией вариацию повторностей, то есть
На практике в большинстве случаев приходится рассматривать зависимые выборки, когда условия для групп и подгрупп выравниваются. Так, в полевом опыте весь участок разбивают на блоки, с максимально вирівняннями условиями. При этом каждый вариант опыта получает равные возможности быть представленным во всех блоках, чем достигается выравнивание условий для всех проверяемых вариантов, опыта. Такой метод построения опыта получил название метода рендомізованих блоков. Аналогично проводятся и опыты с животными.
При обработке методом дисперсионного анализа социально-экономических данных необходимо иметь в виду, что в силу багаточисельності факторов и их взаимосвязи трудно даже при самом тщательном выравнивании условий установить степень объективного влияния каждого отдельного фактора на результативный признак. Поэтому уровень остаточной вариации определяется не только случайными причинами, но и существенными факторами, которые не были учтены при построении модели дисперсионного анализа. В результате этого остаточная, дисперсия как база сравнения иногда становится неадекватным своему назначению, она явно завышается по величине и не может выступать как критерий существенности влияния факторов. В связи с этим при построении моделей дисперсионного анализа становится актуальной проблема отбора важнейших факторов и выравнивания условий для проявления действия каждого из них. Кроме того. применение дисперсионного анализа предполагает нормальный или близкий к нормальному распределение исследуемых статистических совокупностей. Если это условие не выдерживается, то оценки, полученные в дисперсионном анализе, окажутся преувеличенными.
Средние квадраты и s R 2 представляют собой несмещенные оценки зависимой переменной, обусловленных соответственно регрессией или объясняющей переменной х и воздействием неучтенных случайных факторов и ошибок; m – число оцениваемых параметров регрессии, n – число наблюдений. При отсутствии линейной зависимости между зависимой и объясняющей (факторной) переменной случайные величины и s R 2 имеют 2 – распределение соответственно с m-1 и n-m степенями свободы, а их отношение F – распределение с теми же степенями свободы. Поэтому, уравнение регрессии значимо на уровне , если фактически наблюдаемое значение статистики превышает табличное:
![]() (5.11),
(5.11),
где - табличное значение F – критерия Фишера – Снедекора, определенное на уровне значимости при k1 = m-1 и k2 = n-m степенях свободы.
Учитывая смысл величин и s R 2 , можно сказать, что значение F показывает, в какой мере регрессия лучше оценивает значение зависимой переменной по сравнению с ее средней.
В случае парной линейной регрессии m = 2, и уравнение регрессии значимо на уровне , если
![]() (5.12)
(5.12)
Мерой значимости линии регрессии может служить следующее соотношение:

где ŷ i -i-e выравненное значение; -средняя арифметическая значений y i ; σ y.x -средняя квадратическая ошибка (ошибка аппроксимации) регрессионного уравнения, вычисляемая по известной формуле; n-число сравниваемых пар значений признаков; m-число факторных признаков.
Действительно, связь тем больше, чем значительнее мера рассеяния признака, обусловленная регрессией, превосходит меру рассеяния отклонений фактических значений от выравненных.
Данное соотношение позволяет решить вопрос о значимости уравнения регрессии в целом, то есть о наличии реально существующей статистической зависимости между переменными. Уравнение регрессия значимо, т. е. между признаками существует статистическая связь, если для данного уровня значимости расчетное значение критерия Фишера F превышает критическое значение F кр , стоящее на пересечении m-го столбца и -й строки специальной статистической таблицы, которая так и называется «Таблица значений F-критерия Фишера».
Пример. Воспользуемся критерием Фишера для оценки значимости уравнения регрессии, построенного на прошлой лекции, то есть уравнения, выражающего зависимость между сбором урожая и размером посева на душу населения.
Подставив в формулу для расчета критерия Фишера, данные предыдущего примера, получим
![]()
Обращаясь к таблице F-распределения для Р=0,95 (α=1-Р=0,5) и учитывая, что n-2=21, m-1 =1, в таблице значений F-критерия на пересечения 1-го столбца и 21-й строки находим критическое значение F кр, равное 4,32 при степени надежности Р=0,95. Поскольку расчетное значение F-критерия существенно превосходит по величине F кр, то обнаруженная линейная связь существенна, т. е. априорная гипотеза о наличии линейной связи подтвердилась. Вывод сделан при степени надежности P=0,95. Можно проверить, что вывод в данном случае останется прежним, если надежность повысить до Р=0,99 (соответствующее значение F кр =8,02 для уровня значимости α=0,01).
Коэффициент детерминации. С помощью F-критерия мы установили, что существует линейная зависимость между величиной сбора хлеба и величиной посева на душу. Следовательно, можно утверждать, что величина сбора хлеба, приходящегося на душу, линейно зависит от величины посева на душу. Теперь уместно поставить уточняющий вопрос - в какой степени величина посева на душу определяет величину сбора хлеба на душу? На этот вопрос можно ответить, рассчитав, какая часть вариации результативного признака может быть объяснена влиянием факторного признака. Этой цели служит индекс (или коэффициент) детерминации R 2 , который позволяет оценить долю разброса, учитываемого регрессией, в общем разбросе результативного признака. Коэффициент детерминации , равный отношению факторной вариации к полной вариации признака, позволяет судить о том, насколько «удачно» выбран вид функции, описывающей реальную статистическую зависимость.
Если известен коэффициент детерминации R 2 , то критерий значимости уравнения регрессии или самого коэффициента детерминации (критерий Фишера) может быть записан в виде:
![]()
Критерий Фишера позволяет также оценивать полезность включения дополнительных факторов в модель для уравнения множественной линейной регрессии.
В эконометрике, помимо общего критерия Фишера, используется также понятие частного критерия . Частный F-критерий показывает степень влияния дополнительной независимой переменной на результативный признак и может использоваться при решении вопроса о добавлении в уравнение или исключении из него этой независимой переменной.
Разброс признака, объясняемый уравнением двухфакторной регрессии, построенным ранее, можно разложить на два вида: 1) разброс признака, обусловленный независимой переменной х 1 , и 2) разброс признака, обусловленный независимой переменной x 2 , когда х 1 уже включена в уравнение. Первой составляющей соответствует разброс признака, объясняемый уравнением, включающим только переменную х 1 . Разность между разбросом признака, обусловленным уравнением парной линейной регрессии, и разбросом признака, обусловленным уравнением двухфакторной линейной регрессии, определит ту часть разброса, которая объясняется дополнительной независимой переменной x 2 .
Отношение указанной разности к разбросу признака, регрессией не объясняемому, представляет собой значениечастного критерия. Частный F-критерий называется также последовательным, если статистические характеристики строятся при последовательном добавлении переменных в регрессионное уравнение.
Пример. Оценить полезность включения в уравнение регрессии дополнительной переменной «урожайность» (по данным и результатам ранее рассмотренных примеров).
Разброс признака, объясняемый уравнением множественной регрессии и рассчитываемый как сумма квадратов разностей выравненных значений и их средней, равен 1623,8815. Разброс признака, объясняемый уравнением простой регрессии, составляет 1545,1331.
Разброс признака, регрессией не объясняемый, определяется квадратом средней квадратической ошибки уравнения и равен 10,9948.
Воспользовавшись этими характеристиками, рассчитаем частный F-критерий
С уровнем надежности 0,95 (α=0,05) табличное значение F (1,20), т. е. значение, стоящее на пересечении 1-го столбца и 20-й строки табл. 4А приложения, равно 4,35. Рассчитанное значение F-критерия значительно превосходит табличное, и, следовательно, включение в уравнение переменной «урожайность» имеет смысл.
Таким образом, выводы, сделанные ранее относительно коэффициентов регрессии, вполне правомерны.
4й учебный вопрос. Оценка значимости отдельных параметров уравнения регрессии с помощью критерия Стьюдента.
Очень часто в эконометрике требуется оценить значимость коэффициента корреляции r , то есть определить, насколько существенно отличие коэффициента корреляции от нуля (например, при анализе мультиколлинеарности и оценке парных коэффициентов корреляции между факторами в уравнении множественной регрессии).
При этом исходят из того, что при отсутствии корреляционной связи статистика t ,
имеет t -распределение Стьюдента с (n-2) степенями свободы.
Коэффициент корреляции r xy значим на уровне , (иначе – гипотеза Н 0 о равенстве генерального коэффициента корреляции нулю отвергается), если
![]() (5.13),
(5.13),
Где -табличное значение t -критерия Стьюдента, определенное на уровне значимости a при числе степеней свободы (n-2).
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка. Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии; вычисляется значение t-критерия, его величина сравнивается с табличным значением при (n-2) степенях свободы. Проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Заключение. Итак, мы рассмотрели на данной лекции общие правила проверки статистических гипотез и их практическое применение при оценке значимости уравнений регрессии и их отдельных параметров с помощью критериев Фишера и Стьюдента.







