
В мире часто происходят события, исход которых не предопределен заранее. Всем известен хрестоматийный пример с подбрасыванием монетки, завершающийся случайным событием: выпадением орла или решки. Таким случайным событиям можно приписать вероятность – число от нуля до единицы. Однако не у всякого события может быть вероятность. Ключевым условием является повторяемость. Поэтому бессмысленно спрашивать, какова вероятность того, что завтра пойдет дождь. У «завтра» нет повторяемости – это уникальное событие, которое нельзя повторить. Однако можно говорить о вероятности того, что 7 июля будет дождь. Событие «7 июля» повторяется каждый год, и дождю в этот день можно приписать некоторую вероятность.
Понятие вероятности можно применять только к тем событиям, которые еще не произошли, или исход которых нам пока не известен. Так, например, мы можем рассчитать вероятность выигрыша в лотерею, но, как только нам стал известен результат розыгрыша, т.е. событие уже произошло – рассчитанная вероятность теряет всякий смысл.
Еще одним важным понятием является пространство событий – это полный набор всех возможных исходов. Так в опыте с монеткой есть только два события: орел и решка. Рассмотрим другой опыт – измерение роста случайно выбранного человека. Если точность измерения один сантиметр, то пространство событий – это набор чисел от 30 см (новорожденный), до 251 см (рекорд книги Гиннеса) – всего 222 варианта. Однако если мы меряем рост с точность до 1 метра, то в пространстве оказываются только три события: меньше 1 м, от 1 м до 2 м, и больше 2 м.
1.2. Случайная величина
Случайная величина - это переменная, значение которой до опыта (реализации) неизвестно. Всякая случайная величина характеризуется:
- множеством своих возможных значений (пространство событий)
- неограниченным числом повторения реализаций
- вероятностью попадания в любую наперед заданную область во множестве значений
Множество значений может быть дискретным, непрерывным и дискретно-непрерывным. Соответственно именуются и случайные величины.
1.3. Распределение случайной величины
Пусть X – это случайная величина, множеством возможных значений которой являются действительные числа. Рассмотрим вероятность события, что реализация X не больше заданного числа x . Если рассматривать эту вероятность в зависимости от величины x , то получится функция F (x ), называемая (кумулятивной) функцией распределения случайной величины –
|
F (x ) = Pr{X ≤x }. |
Функция распределения это неубывающая функция, которая стремится к 0 при малых x , и стремится к 1 при больших значениях аргумента.
То, что случайная величина X имеет функцию распределения F обозначается так –
X ~ F.
Распределение называется симметричным (относительно точки a ) если F (a +x )=1–F (a –x ).
Для дискретных случайная величина функция распределения кусочно-постоянна со скачками в точках x =x i .
Производная функция распределения F (x ) называется плотностью вероятности f (x )


Рис. 1 плотность вероятности f (x ) и ф.р F (x ) случайной величины
1.4. Математическое ожидание
Пусть X f (x ).
Математическим ожиданием X называется величина
 .
.
1.5. Дисперсия и СKО
Пусть X – это случайная величина с плотностью вероятности f (x ).
Дисперсией X называется величина
Если из дисперсии извлечь квадратный корень, то получится величина, называемая среднеквадратичным отклонением (СКО) .
1.6. Моменты
Пусть X – это случайная величина с плотностью вероятности f (x ).
Моментом порядка n называется величина
 .
.
По определению μ 1 = E(X ).
Центральным моментом порядка n называется величина
|
|
 .
.
По определению m 2 = V(X ).
1.7. Квантили
Пусть F (x ) – (кумулятивная) функция распределения случайной величины
Рассмотрим функцию F –1 (P ), 0≤P ≤1, обратную к F (x ) т.е.
F –1 (F (x ))=x F (F –1 (P ))=P .
Функция F –1 (P ) называется P-квантилем распределения F .
Величина квантиля для P =0.5 называется медианой распределения.
Квантили для P =0.25, 0.75 называются квартилями , а для P =0.01, 0.02, …, 0.99 называются процентилями.
1.8. Многомерные распределения
Две (и более) случайные величины можно рассматривать совместно. Совместная (кумулятивная) функция распределения двух случайных величин X и Y определяется так
Так же, как и в одномерном случае, функция f (x , y ) называется плотностью вероятности.
Случайные величины X и Y называются независимыми , если их совместная плотность вероятности равна произведению частных плотностей.
|
f (x , y )= f (x ) f (y ) . |
2. Основные распределения2.1. Биномиальное распределениеДискретная случайная величина X имеет дискретное биномиальное распределение , если ее плотность вероятности имеет вид
где Биномиальное распределение – это распределение числа успехов k в серии из независимых n опытов, при условии, что вероятность успеха в каждом опыте есть p . Математическое ожидание и дисперсия, соответственно, равны
При больших n биномиальное распределение хорошо приближается с параметрами . Рис. 2 плотность вероятности и функция распределения биномиального распределения Для вычисления биномиального распределения в Excel используется стандартная функция BINOMDIST (БИНОМРАСП ). Синтаксис BINOMDIST (number_s =k , trials =n , probability_s =p ,cumulative =TRUE|FALSE) Если cumulative =TRUE, то возвращается кумулятивная функция распределения, а если cumulative =FALSE , то возвращается плотность вероятности Рис. 3 Пример вычисления биномиального распределения 2.2. Равномерное распределение2.3. Нормальное распределениеРис. 5 Функция распределения и плотность вероятности нормального распределения Для вычисления нормального распределения в Excel используется стандартные функции: NORMDIST (НОРМРАСП ) и NORMSDIST (НОРМСТРАСП ), а также NORMINV (НОРМОБР ) и NORMSINV (НОРМСТОБР ). Синтаксис NORMDIST (x , mean =m , standard_dev = σ, cumulative =TRUE|FALSE) Если cumulative =TRUE то возвращается кумулятивная функция распределения Φ(x |m , σ 2), а если cumulative =FALSE , то возвращается плотность вероятности . NORMS DIST (x) Возвращается кумулятивная функция стандартного нормального распределения в точке x . NORMINV (probability =P , mean =m , standard_dev = σ) Возвращается квантиль Φ –1 (P |m , σ 2) нормального распределения для вероятности P. NORMSINV (probability =P ) Возвращается квантиль Φ –1 (P |0, 1) стандартного нормального распределения для вероятности P. Рис.6 Пример вычисления нормального распределения 2.4. Распределение хи-квадратРассмотрим N независимых стандартных случайных величин X 1 ,…, X n ,…, X N с нулевым мат. ожиданием и единичной дисперсией, т.е. X n ~ N(0, 1). Величина
является случайной, распределение которой носит название хи-квадрат . Это распределение зависит от одного параметра – N , который называется числом степеней свободы. Плотность вероятности распределения хи-квадрат имеет вид
Распределение хи-квадрат широко используется в статистике, например, при проверке гипотез. Математическое ожидание и дисперсия распределения χ 2 (N ) равны, соответственно,
При больших N распределение хи-квадрат хорошо приближается с параметрами (). Квантили распределения χ 2 (N ) обозначаются χ –2 (P |N ). Рис.7 функция распределения и квантиль распределения хи-квадрат Для вычисления распределения хи-квадрат в Excel используется две стандартные функции: CHIDIST (ХИ2РАСП ) и CHIINV (ХИ2ОБР ). Синтаксис CHIDIST (x , degrees_freedom =N ) Возвращается значение 1 – χ 2 (x |N ), где χ 2 (x |N ) –кумулятивная функция распределения хи-квадрат. CHIINV (probability =1–P ,degrees_freedom =N ) Возвращается квантиль χ –2 (1 – P |N ) распределения хи-квадрат для вероятности 1 – P . Рис.8 Пример вычисления распределения хи-квадрат 2.5 . Распределение СтьюдентаРассмотрим две случайные величины: X – распределенную стандартно- X ~ N(0, 1), и Y – распределенную по с N степенями свободы Y ~ χ 2 (N ). Случайная величина
подчиняется распределению, которое носит имя Стьюдента . Это распределение зависит от одного параметра N , который также называется числом степеней свободы. Распределение Стьюдента применяется в проверке гипотез и для построения доверительных интервалов. Математическое ожидание T(N ) равно нулю, а дисперсия равна V(T(N ))=N /(N –2), N >2. Распределение Стьюдента симметрично, и при N >20 неотличимо от нормального. Формула для плотности вероятности Стьюдента приведена во многих пособиях. Квантили распределения T(N) обозначаются T –1 (P |N ). Рис.9 Функция распределения и квантиль распределения Стьюдента Для вычисления распределения Стьюдента в Excel используется две стандартные функции: TDIST (СТЬЮДРАСП ) и TINV (СТЬЮДРАСПОБР ). Синтаксис TDIST (x , degrees_freedom =N , tails =1|2) Если tails = 1, то функция TDIST возвращает значение Pr{T(N ) > x }, а при tails = 2 значение Pr{|T(N )| > x }. Значения при x <0 не возвращаются. Поэтому, для того, чтобы вычислить в Excel обычную кумулятивную функцию распределения Стьюдента T(x |N ), приходится использовать следующую формулу IF(x>0, 1-TDIST(x,N,1), -TDIST(-x,N,1)) . TINV (probability , degrees_freedom =N ) Возвращается значение x , для которого Pr{|T(N )| > x } = probability . И в этом случае для вычисления в Excel квантиля распределения Стьюдента T –1 (P |N ), нужно использовать следующую формулу IF(P<0.5, TINV(2*P,N), -TINV(2-2*P,N)). Рис.10 Пример вычисления распределения Стьюдента 2.6 . Распределение ФишераПусть имеются две независимые случайные величины X 1 и X 2 , каждая из которых подчиняется распределению с N 1 и N 2 степенями свободы, т.е. X 1 ~ χ 2 (N 1 ) и X 2 ~ χ 2 (N 2 ). Случайная величина
подчиняется распределению, которое носит имя Фишера . Это распределение зависит от двух параметров N 1 и N 2 , которые также называются числами степеней свободы. Математическое ожидание и дисперсия распределения F(N 1 ,N 2) равны, соответственно, E(F(N 1 ,N 2))= N 2 /(N 2 –2), N 2 >2 Формула для плотности вероятности распределения Фишера приведена во многих пособиях. Если X ~ F(N 1 ,N 2), то 1/X ~ F(N 2 ,N 1 ). Квантили распределения F(N 1 ,N 2) обозначаются F –1 (P |N 1 ,N 2 ) . Рис.11 Функция распределения и квантиль распределения Фишера Для вычисления распределения Фишера в Excel используются две стандартные функции: FDIST (FРАСП ) и FINV (FРАСПОБР ). Синтаксис FDIST (x ,degrees_freedom1 = N 1 ,degrees_freedom2 = N 2) Возвращается значение 1 – F(x |N 1 ,N 2), где F(x |N 1 ,N 2) – кумулятивная функция распределения Фишера. FINV (probability =1–P , degrees_freedom1 = N 1 ,degrees_freedom2 = N 2) Возвращается квантиль F –1 (1 – P |N 1 ,N 2) для вероятности 1 – P . Рис.12 Пример вычисления распределения Фишера 2.7 . Многомерное нормальное распределениеЭто распределение является естественным обобщением одномерного нормального распределения на случай многомерной случайной величины, т.е. случайного вектора x , размерностью n . Функция плотности вероятности имеет следующий вид где Σ – симметричная положительно определенная (n ×n ) матрица. 2.8 . Генерация случайных чиселИногда бывает полезно создать искусственную выборку случайных чисел, подчиняющихся заданному распределению. Это можно сделать, используя следующее простое утверждение. Пусть F (x ) и F –1 (P ) суть некоторая функция распределения и ее квантиль, соответственно. Если случайная величина X распределена на отрезке [ 0, 1] , т.е X ~ U(0,1), тогда случайная величина Y = F –1 (X ) имеет функция распределения F . Таким образом, если получить набор случайных величин, распределенных равномерно, то эти случайные величины можно превратить в новые, имеющие другое, заданное распределение. Для генерации случайных чисел в Excel имеется стандартная функция: RAND (СЛЧИС ) . Синтаксис RAND() Возвращает случайное число, равномерно распределенное на отрезке . Новое случайное число возвращается при каждом вычислении рабочего листа. Рис.13 Пример генерации случайных чисел 3. Оценка параметров3.1. ВыборкаПредположим, что имеется набор чисел x =(x 1 ,…, x I ), и каждое x i является одной реализацией случайной величины, подчиняющейся, вообще говоря, неизвестному распределению. Этот набор называется выборкой , а число I – объемом выборки. В случае одномерного распределения выборка – это вектор x , а в многомерном случае выборка – это матрица X размерностью I ×J , каждая строка которой представляет одну реализацию (наблюдение) многомерной случайной величины размерностью J . Обычно предполагается, что все элементы выборки статистически независимы. В практических приложениях слово «выборка» часто заменяется словом «данные». 3.2. Выбросы и маргиналыСреди элементов выборки могут присутствовать такие, которые существенно отличаются от других элементов. Пусть, например, имеется выборка из стандартного распределения N (0,1), в которой присутствует элемент со значением x out =3.2. Для такого распределения вероятность единичного события x out ≥ 3.2 мала – она равна α=0.0007. Однако значение x out присутствует в независимой выборке размера I , поэтому нужно рассчитывать вероятность события «хотя бы один раз среди I попыток» Для I =10 P out =0.007, для I =100 P out =0.07, а для I =1000 P out =0.50. Естественно – чем больше выборка, тем выше вероятность того, что встретится такое экстремальное значение. Таким образом, интерпретация выпадающих из выборки значений существенно зависит от объема выборки – для малых I их нужно рассматривать как выбросы (промахи при измерениях) и, соответственно, удалять из выборки. Для больших I такие выпадающие значения являются приемлемыми маргиналами и они должны сохраняться в выборке. 3.3. Генеральная совокупностьОперацию создания выборки в статистике называют извлечением. Тем самым подчеркивают, что имеющаяся у нас выборка x 1 не единственная, и что можно получить (часто только теоретически) и другие похожие выборки x 2 , x 3 , …., x n . Слово похожие означает, что все эти выборки устроены аналогичным способом – подчиняются одному и тому же распределению, имеют одинаковый объем I , и т.п. Все бесконечное множество таких выборок образуют генеральную совокупность (называемую также популяцией). Для вычисления выборочных статистик в Excel используют следующие стандартные функции:AVERAGE (СРЗНАЧ ), VAR (ДИСП ), VARP (ДИСПР ), STDEV (СТАНДОТКЛОН ), STDEVP (СТАНДОТКЛОНП ). Синтаксис AVERAGE (x) Возвращает среднее значение выборки x , вычисленное по формуле (). VAR (x) Возвращает выборочную дисперсию выборки x , вычисленную по формуле (). VARP (x) Возвращает выборочную дисперсию выборки x , вычисленную по формуле (). STDEV (x) x , вычисленной по формуле (). STDEVP (x) Возвращает среднеквадратичное отклонение т.е. корень квадратный из выборочной дисперсии выборки x , вычисленной по формуле (). Синтаксис COVAR (x ,y )Возвращает выборочную ковариацию между выборками x и y. CORREL (x ,y )Возвращает выборочный коэффициент корреляции между выборками x и y. Размахом выборки называется величина x (I ) – x (1) . Интерквартильным размахом выборки x называется величина являющаяся разностью выборочных квартилей для P =0.75 и P =0.25. Для вычисления порядковых статистик в Excel используют следующие стандартные функции: MEDIAN (МЕДИАНА ), QUARTILE (КВАРТИЛЬ ), PERCENTILE (ПЕРСЕНТИЛЬ ). Синтаксис MEDIAN (x ) Возвращает выборочную медиану для выборки x .. QUARTILE (x , quart =0|1|2|3|4) Возвращает выборочный квартиль для выборки x . в зависимости от значения аргумента quart0 Минимальное значение 1 Первый квартиль (25-ый перцентиль) 2 Значение медианы (50-ый перцентиль) 3 Третий квартиль (75-ый перцентиль) 4 Максимальное значение PERCENTILE (x , k ) Возвращает k -ый выборочный перцентиль для выборкиx . Значения аргумента: 0≤k ≤1. Синтаксис FREQUENCY (data_array , bins_array ) Возвращает число попаданий значений data_array в интервалы, заданные аргументом bins_array . Эта функция возвращает вертикальный массив, и она должна вводится как формула массива – с помощью комбинации клавиш CTRL+SHIFT+ENTER . Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве bins_array . Дополнительный элемент содержит количество значений из data_array больших, чем максимальное значение в массиве bins_array . Рис.15 Пример использования функции FREQUENCY Y ~ χ 2 (N ). По выборке x =(x 1 ,…, x I ) нужно найти оценки двух неизвестных параметров a и N . 4. Свойства оценок4.1. СостоятельностьЛюбая оценка p (x ) параметра p есть статистика, т.е. случайная величина. И как всякая случайная величина она обладает собственной функцией распределения, математическим ожиданием, дисперсией и т.д. Все эти характеристики позволяют сравнивать разные оценки, судить об их свойствах и качествах. Ниже следует краткий обзор основных свойств оценок. Оценка p (x ) называется состоятельной , если она сходится по вероятности к значению оцениваемого параметра p при безграничном возрастании объема выборки I . Точнее, статистика p (x ) является состоятельной оценкой параметра p тогда и только тогда, когда для любого положительного числа ε справедливо
Большинство оценок, используемых в практических приложениях, являются состоятельными. 4.2. СмещенностьОценка p (x ) называется несмещенной , если E[p (x )]=p. Смещенные оценки часто встречаются в приложениях. Например, дисперсии нормального распределения () является смещенной Для несмещенных оценок мерилом их точности является дисперсия V[p (x )] – чем она меньше, тем лучше. Для смещенных оценок нужно использовать математическое ожидание квадрата смещения d (x )= E[p (x ) – p ) 2 ] . Имеет место формула
4.3. ЭффективностьНесмещенная оценка называется эффективной , если она имеет наименьшую возможную дисперсию. Оценки () нормального распределения являются эффективными, но вот выборочная оценка медианы (см. раздел ) таковой не является – она менее эффективно оценивает m , чем выборочное среднее. Смещенные оценки могут оказаться более точными, чем несмещенные. Это означает, что часто можно построить такие смещенные оценки, для которых квадрат ошибки меньше, чем наименьшая эффективная дисперсия. На этом принципе основаны такие методы оценивания как PCR , PLS и др. 4.4 . Робастностьв которой median рассчитывается по формуле (). Рис.16 Обычные и робастные оценки 4.5 . Нормальная выборкаЕсли выборка x =(x 1 ,…, x I ) извлечена из распределения x i ~ N(m , σ 2) , и оценки определены формулами () – (), то выполняются следующие утверждения. Т.е.имеет распределение с I степенями свободы;
5 . Доверительное оценивание5 .1. Доверительная областьВо многих случаях, помимо точечных оценок неизвестных параметров распределения, желательно указать область, в которой истинные значения этих параметров содержатся с заданной вероятностью. Такая область называется доверительной . Дадим точное определение. Пусть x =(x 1 ,…, x I ) подчиняется функция распределения F (x | p ), т.е. x i ~ F (x | p ), которая известна с точностью до значений параметровp =(p 1 ,…, p M ). Статистика P (x ) ∈ R M называется доверительной областью, соответствующей доверительной вероятности γ, если Pr{p ∈ P (x )}≥γ . 5 .2 .Доверительный интервалЧасто для каждого параметра p m строится своя одномерная область – доверительный интервал . Границы доверительного интервала – это две статистики p – (x ) и p + (x ), такие, что Pr{ p – (x ) ≤ p ≤ p + (x )}≥γ. Для односторонних доверительных интервалов соответствующая граница заменяется на –∞, 0, или +∞. В большинстве практических случаев доверительные интервалы строятся для (асимптотически) нормальных выборок с помощью соотношений, приведенных в разделе . 5 .3 . Пример построения доверительного интервалаПриведем пример построения доверительного интервала. Пусть имеется выборка x =(x 1 ,…, x I ) из распределения N(m , σ 2) с известной дисперсией σ 2 . Построим доверительный интервал для параметра m – математического ожидания. Изуравнения () следует, что где Φ –1 – квантиль стандартного нормального распределения, поэтому Для построения симметричного доверительного интервала с доверительной вероятностью γ, положим α 1 = α 2 = 0.5(1+γ). Для построения односторонних доверительных интервалов, положим α 1 = 1, α 2 =γ, или α 1 = γ, α 2 =1. 5 .4 . Вычисление доверительного интервала для нормального распределенияИспользуя соотношения, приведенные в разделе , можно построить доверительный интервал для параметров распределения N(m , σ 2). Пусть оценки определены формулами () – (), тогда выполняются следующие утверждения. |
 .
.В процессе вычисления средней арифметической и использования ее в анализе социально-экономических процессов может оказаться полезным знание ряда ее математических свойств, которые мы приведем без развернутых доказательств.
Свойство 1. Средняя арифметическая постоянной величины равна этой постоянной: при
Свойство 2. Алгебраическая сумма отклонений индивидуальных значений признака от средней арифметической равна нулю: ![]() для несгруппированных данных и
для несгруппированных данных и ![]() для рядов распределения.
для рядов распределения.
Это свойство означает, что сумма положительных отклонений равна сумме отрицательных отклонений, т.е. все отклонения, обусловленные случайными причинами взаимно погашаются.
Свойство 3. Сумма квадратов отклонений индивидуальных значений признака от средней арифметической есть число минимальное: ![]() для несгруппировочных данных и
для несгруппировочных данных и ![]() для рядов распределения. Это свойство означает, что сумма квадратов отклонений индивидуальных значений признака от средней арифметической всегда меньше суммы отклонений вариантов признака от любого другого значения, даже мало отличающегося от средней.
для рядов распределения. Это свойство означает, что сумма квадратов отклонений индивидуальных значений признака от средней арифметической всегда меньше суммы отклонений вариантов признака от любого другого значения, даже мало отличающегося от средней.
Второе и третье свойство средней арифметической применяются для проверки правильности расчета средней величины; при изучении закономерностей изменения уровней ряда динамики; для нахождения параметров уравнения регрессии при изучении корреляционной связи между признаками.
Все три первых свойства выражают сущностные черты средней как статистической категории.
Следующие свойства средней рассматриваются как вычислительные, поскольку они имеют некоторое прикладное значение.
Свойство 4. Если все веса (частоты) разделить на какое-либо постоянное число d, то средняя арифметическая не изменится, поскольку это сокращение в равной степени коснется и числителя и знаменателя формулы расчета средней.
Из этого свойства вытекают два важных следствия.
Следствие 1. Если все веса равны между собой, то вычисление средней арифметической взвешенной можно заменить вычислением средней арифметической простой.
Следствие 2. Абсолютные значения частот (весов) можно заменять их удельными весами.
Свойство 5. Если все варианты разделить или умножить на какое-либо постоянное число d, то средняя арифметическая уменьшиться или увеличиться в d раз.
Свойство 6. Если все варианты уменьшить или увеличить на постоянной число A, то и со средней произойдут аналогичные изменения.
Прикладные свойства средней арифметической можно проиллюстрировать, применив способ расчета средней от условного начала (способ моментов).
Средняя арифметическая способом моментов вычисляется по формуле:
где А – середина какого-либо интервала (предпочтение отдается центральному);
d – величина равновеликого интервала, или наибольший кратный делитель интервалов;
m 1 – момент первого порядка.
Момент первого порядка определяется следующим образом:
 .
.
Технику применения этого способа расчета проиллюстрируем по данным предшествующего примера.
Таблица 5.6
| Стаж работы, лет | Число рабочих | Середина интервала x | |||
| до 5 | 2,5 | -10 | -2 | -28 | |
| 5-10 | 7,5 | -5 | -1 | -22 | |
| 10-15 | 12,5 | ||||
| 15-20 | 17,5 | +5 | +1 | +25 | |
| 20 и выше | 22,5 | +10 | +2 | +22 | |
| Итого | Х | Х | Х | -3 |
Как видно из расчетов, приведенных в табл. 5.6 из всех вариантов вычитается одно из их значений 12,5, которое приравнивается нулю и служит условным началом отсчета. В результате деления разностей на величину интервала – 5 получают новые варианты.
Согласно итогу табл. 5.6 имеем: ![]() .
.
Результат вычислений по способу моментов аналогичен результату, который был получен применением основного способа расчета по средней арифметической взвешенной.
Признаки единиц статистических совокупностей различны по своему значению, например, заработная плата рабочих одной профессии какого-либо предприятия не одинакова за один и тот же период времени, различны цены на рынке на одинаковую продукцию, урожайность сельскохозяйственных культур в хозяйствах района и т.д. Поэтому, чтобы определить значение признака, характерное для всей изучаемой совокупности единиц, рассчитывают средние величины.
Средняя величина
–
это обобщающая характеристика множества индивидуальных значений некоторого количественного признака.
Совокупность, изучаемая по количественному признаку, состоит из индивидуальных значений; на них оказывают влияние, как общие причины, так и индивидуальные условия. В среднем значении отклонения, характерные для индивидуальных значений, погашаются. Средняя, являясь функцией множества индивидуальных значений, представляет одним значением всю совокупность и отражает то общее, что присуще всем ее единицам.
Средняя, рассчитываемая для совокупностей, состоящих из качественно однородных единиц, называется типической средней . Например, можно рассчитать среднемесячную заработную плату работника той или иной профессиональной группы (шахтера, врача библиотекаря). Разумеется, уровни месячной заработной платы шахтеров в силу различия их квалификации, стажа работы, отработанного за месяц времени и многих других факторов отличаются друг от друга, так и от уровня средней заработной платы. Однако в среднем уровне отражены основные факторы, которые влияют на уровень заработной платы, и взаимно погашаются различия, которые возникают вследствие индивидуальных особенностей работника. Средняя заработная плата отражает типичный уровень оплаты труда для данного вида работников. Получению типической средней должен предшествовать анализ того, насколько данная совокупность качественно однородна. Если совокупность состоит их отдельных частей, следует разбить ее на типические группы (средняя температура по больнице).
Средние величины, используемые в качестве характеристик для неоднородных совокупностей, называются системными средними . Например, средняя величина валового внутреннего продукта (ВВП) на душу населения, средняя величина потребления различных групп товаров на человека и другие подобные величины, представляющие обобщающие характеристики государства как единой экономической системы.
Средняя должна вычисляться для совокупностей, состоящих из достаточно большого числа единиц. Соблюдение этого условия необходимо для того, чтобы вошел в силу закон больших чисел, в результате действия которого случайные отклонения индивидуальных величин от общей тенденции взаимно погашаются.
Виды средних и способы их вычисления
Выбор вида средней определяется экономическим содержанием определенного показателя и исходных данных. Однако любая средняя величина должна вычисляться так, чтобы при замене ею каждой варианты осредняемого признака не изменился итоговый, обобщающий, или, как его принято называть, определяющий показатель
, который связан с осредняемым показателем. Например, при замене фактических скоростей на отдельных отрезках пути их средней скоростью не должно измениться общее расстояние, пройденное транспортным средством за одно и тоже время; при замене фактических заработных плат отдельных работников предприятия средней заработной платой не должен измениться фонд заработной платы. Следовательно, в каждом конкретном случае в зависимости от характера имеющихся данных, существует только одно истинное среднее значение показателя, адекватное свойствам и сущности изучаемого социально-экономического явления.
Наиболее часто применяются средняя арифметическая, средняя гармоническая, средняя геометрическая, средняя квадратическая и средняя кубическая.
Перечисленные средние относятся к классу степенных
средних и объединяются общей формулой:
,
где – среднее значение исследуемого признака;
m – показатель степени средней;
– текущее значение (варианта) осредняемого признака;
n – число признаков.
В зависимости от значения показателя степени m различают следующие виды степенных средних:
при m = -1 – средняя гармоническая ;
при m = 0 – средняя геометрическая ;
при m = 1 – средняя арифметическая ;
при m = 2 – средняя квадратическая ;
при m = 3 – средняя кубическая .
При использовании одних и тех же исходных данных, чем больше показатель степени m в вышеприведенной формуле, тем больше значение средней величины:
.
Это свойство степенных средних возрастать с повышением показателя степени определяющей функции называется правилом мажорантности средних
.
Каждая из отмеченных средних может приобретать две формы: простую
и взвешенную
.
Простая форма средней
применяется, когда средняя вычисляется по первичным (несгруппированными) данным. Взвешенная форма
– при расчете средней по вторичным (сгруппированным) данным.
Средняя арифметическая
Средняя арифметическая применяется, когда объем совокупности представляет собой сумму всех индивидуальных значений варьирующего признака. Следует отметить, что если вид средней величины не указывается, подразумевается средняя арифметическая. Ее логическая формула имеет вид:![]()
Средняя арифметическая простая
рассчитывается по несгруппированным данным
по формуле:![]() или ,
или ,
где – отдельные значения признака;
j – порядковый номер единицы наблюдения, которая характеризуется значением ;
N – число единиц наблюдения (объем совокупности).
Пример.
В лекции «Сводка и группировка статистических данных» рассматривались результаты наблюдения стажа работы бригады из 10 человек. Рассчитаем средний стаж работы рабочих бригады. 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
По формуле средней арифметической простой вычисляются также средние в хронологическом ряду
, если интервалы времени, за которое представлены значения признака, равны.
Пример.
Объем реализованной продукции за первый квартал составил 47 ден. ед., за второй 54, за третий 65 и за четвертый 58 ден. ед. Среднеквартальный оборот составляет (47+54+65+58)/4 = 56 ден. ед.
Если в хронологическом ряду приведены моментные показатели, то при вычислении средней они заменяются полусуммами значений на начало и конец периода.
Если моментов больше двух и интервалы между ними равны, то средняя вычисляется по формуле средней хронологической
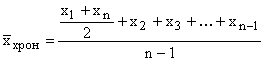 ,
,
где n- число моментов времени
В случае, когда данные сгруппированы по значениям признака
(т. е. построен дискретный вариационный ряд распределения) средняя арифметическая взвешенная
рассчитывается с использовании либо частот , либо частостей наблюдения конкретных значений признака , число которых (k) значительно меньше числа наблюдений (N) .
,
,
где k – количество групп вариационного ряда,
i – номер группы вариационного ряда.
Поскольку , а , получаем формулы, используемые для практических расчетов:
и
Пример.
Рассчитаем средний стаж рабочих бригад по сгруппированному ряду.
а) с использованием частот:
б) с использованием частостей:
В случае, когда данные сгруппированы по интервалам
, т.е. представлены в виде интервальных рядов распределения, при расчете средней арифметической в качестве значения признака принимают середину интервала, исходя из предположения о равномерном распределении единиц совокупности на данном интервале. Расчет ведется по формулам:
и
где - середина интервала: ,
где и – нижняя и верхняя границы интервалов (при условии, что верхняя граница данного интервала совпадает с нижней границей следующего интервала).
Пример.
Рассчитаем среднюю арифметическую интервального вариационного ряда, построенного по результатам исследования годовой заработной платы 30 рабочих (см. лекцию «Сводка и группировка статистических данных»).
Таблица 1 – Интервальный вариационный ряд распределения.
Интервалы, грн. |
Частота, чел. |
Частость, |
Середина интервала, |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() грн. или
грн. или ![]() грн.
грн.
Средние арифметические, вычисленные на основе исходных данных и интервальных вариационных рядов, могут не совпадать из-за неравномерности распределения значений признака внутри интервалов. В этом случае для более точного вычисления средней арифметической взвешенной следует использовать не средины интервалов, а средние арифметические простые, рассчитанные для каждой группы (групповые средние
). Средняя, вычисленная по групповым средним с использованием взвешенной формулы расчета, называется общей средней
.
Средняя арифметическая обладает рядом свойств.
1. Сумма отклонений вариант от средней равна нулю:
.
2. Если все значения вариант увеличиваются или уменьшаются на величину А, то и средняя величина увеличивается или уменьшается на ту же величину А:![]()
3. Если каждую варианту увеличить или уменьшить в В раз, то средняя величина также увеличится или уменьшатся в то же количество раз:
или ![]()
4. Сумма произведений вариант на частоты равна произведению средней величины на сумму частот:![]()
5. Если все частоты разделить или умножить на какое-либо число, то средняя арифметическая не изменится:
6) если во всех интервалах частоты равны друг другу, то средняя арифметическая взвешенная равна простой средней арифметической:![]() ,
,
где k – количество групп вариационного ряда.
Использование свойств средней позволяет упростить ее вычисление.
Допустим, что все варианты (х) сначала уменьшены на одно и то же число А, а затем уменьшены в В раз. Наибольшее упрощение достигается, когда в качестве А выбирается значение середины интервала, обладающего наибольшей частотой, а в качестве В – величина интервала (для рядов с одинаковыми интервалами). Величина А называется началом отсчета, поэтому этот метод вычисления средней называется спосо
бом отсчета от условного нуля
или способом моментов
.
После такого преобразования получим новый вариационный ряд распределения, варианты которого равны . Их средняя арифметическая, называемая моментом первого порядка,
выражаетсяформулой и согласно второго и третьего свойств средней арифметической равна средней из первоначальных вариант, уменьшенной сначала на А, а потом в В раз, т. е. .
Для получения действительной средней
(средней первоначального ряда)нужно момент первого порядка умножить на В и прибавить А:
Расчет средней арифметической по способу моментов иллюстрируется данными табл. 2.
Таблица 2 – Распределение работников цеха предприятия по стажу работы
Стаж работников, лет |
Количество работников |
Середина интервала |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
Находим момент первого порядка ![]() . Затем, зная, что А=17,5, а В=5, вычисляем средний стаж работы работников цеха:
. Затем, зная, что А=17,5, а В=5, вычисляем средний стаж работы работников цеха:
лет
Средняя гармоническая
Как было показано выше, средняя арифметическая применяется для расчета среднего значения признака в тех случаях, когда известны его варианты x и их частоты f.
Если статистическая информация не содержит частот f по отдельным вариантам x совокупности, а представлена как их произведение , применяется формула средней гармонической взвешенной
. Чтобы вычислить среднюю, обозначим , откуда . Подставив эти выражения в формулу средней арифметической взвешенной, получим формулу средней гармонической взвешенной: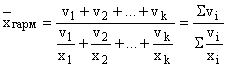 ,
,
где - объем (вес) значений признака показателя в интервале с номером i (i=1,2, …, k).
Таким образом, средняя гармоническая применяется в тех случаях, когда суммированию подлежат не сами варианты, а обратные им величины: ![]() .
.
В тех случаях, когда вес каждой варианты равен единице, т.е. индивидуальные значения обратного признака встречаются по одному разу, применяется средняя гармоническая простая
: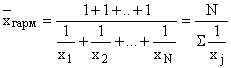 ,
,
где – отдельные варианты обратного признака, встречающиеся по одному разу;
N – число вариант.
Если по двум частям совокупности численностью и имеются средние гармонические, то общая средняя по всей совокупности рассчитывается по формуле: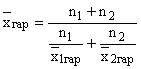
и называется взвешенной гармонической средней из групповых средних
.
Пример.
В ходе торгов на валютной бирже за первый час работы заключены три сделки. Данные о сумме продажи гривны и курсе гривны по отношению к доллару США приведены в табл. 3 (графы 2 и 3). Определить средний курс гривны по отношению к доллару США за первый час торгов.
Таблица 3 – Данные о ходе торгов на валютной бирже
Средний курс доллара определяется отношением суммы проданных в ходе всех сделок гривен к сумме приобретенных в результате этих же сделок долларов. Итоговая сумма продажи гривны известна из графы 2 таблицы, а количество купленных в каждой сделке долларов определяется делением суммы продажи гривны к ее курсу (графа 4). Всего в ходе трех сделок куплено 22 млн. дол. Значит, средний курс гривны за один доллар составил .
.
Полученное значение является реальным, т.к. замена им фактических курсов гривны в сделках не изменит итоговой суммы продаж гривны, выступающей в качестве определяющего показателя
: млн. грн.
Если бы для расчета была использована средняя арифметическая, т.е. ![]() гривны, то по обменному курсу на покупку 22 млн. дол. нужно было бы затратить 110,66 млн. грн., что не соответствует действительности.
гривны, то по обменному курсу на покупку 22 млн. дол. нужно было бы затратить 110,66 млн. грн., что не соответствует действительности.
Средняя геометрическая
Средняя геометрическая используется для анализа динамики явлений и позволяет определить средний коэффициент роста. При расчете средней геометрической индивидуальные значения признака представляют собой относительные показатели динамики, построенные в виде цепных величин, как отношения каждого уровня к предыдущему.
Средняя геометрическая простая рассчитывается по формуле: ,
,
где – знак произведения,
N – число осредняемых величин.
Пример.
Количество зарегистрированных преступлений за 4 года возросло в 1,57 раза, в т. ч. за 1-й – в 1,08 раза, за 2-й – в 1,1 раза, за 3-й – в 1,18 и за 4-й – в 1,12 раза. Тогда среднегодовой темп роста количества преступлений составляет: , т.е. число зарегистрированных преступлений ежегодно росло в среднем на 12%.
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
Для расчета средней квадратической взвешенной определяем и заносим в таблицу и . Тогда средняя величина отклонений длины изделий от заданной нормы равна:
Средняя арифметическая в данном случае была бы непригодна, т.к. в результате мы получили бы нулевое отклонение.
Применение средней квадратической будет рассмотрено далее в показателях вариации.
Формулы по статистике
Тема 1: Группировка статистических данных
Определение числа групп (если группи-ка по непрер. приз-ку или дискрет. со многими знач-ями)
Определение величины равного интервала :
Тема 2: Абсолютные и относительные величины
Относительные величины :
1) относит. вел-на структуры :
2) относит. вел-на планового задания :
3) относит. вел-на выполнения плана :
4) относит. вел-на динамики или темп роста :
![]()
5) относит. вел-на сравнения
6) относит. вел-на интенсивности (пример: фондоотдача = объем/стоимость (один год))
Тема 3: Средние величины и показатели вариации
Средняя арифметическая
простая :
взвешенная :
Средняя гармоническая
простая :
взвешенная : , сумма значений признака по группе
Свойства средн. арифметической:
если каждую вари-ту х умен-ть или увел-ть на одно и то же число, то ср. вел-на умен-ется или увел-ется на это же число;
если каждую вари-ту х умен-ть или увел-ть в одно и то же число раз, то ср. вел-на умен-ется или увел-ется в одно и то же число раз;
если каждую частоту f умен-ть или увел-ть в одно и то же число раз, то ср. вел-на не изменится.
Ср. вел-на зависит от вар-ты х и структуры совок-сти , кот. харак-ется долями d .
Ряд распределения имеет 3 центра :
1) ср. аримет-кое ;
2) мода – наиболее часто встречающаяся вар-та ;
3) медиана – вар-та, стоящая в середине ряда распре-ния. Сначала находят N медианы, кот. равен n/2, если число еди-ц совок-сти n – чётное, или , если число еди-ц совок-сти нечетное .
Осн. пока-ли вариации :
1)
размах
вариации
:
![]()
2) ср. линейное отклонение (ср. арифм-кая из абсолют. откл-ний отдел. значений)
Для несгруппир. данных:
Для
сгруппир. данных:
![]()
3) ср. квадратическое отклонение (хар-ет ср. абсол. откл-ние вар-ты от ср. вел-ны)
Для
несгруппир. данных
:

Для
сгруппир. данных
:

4) Дисперсия – квадрат среднеквадр-ного откл-ния
Для
несгруппир. данных
:
![]()
Для
сгруппир. данных
:
![]()
Общая
дисперсия:
![]() (для сгрупп.)
(для сгрупп.) ![]() (для несгрупп.)
(для несгрупп.)
– ср. вел-на резул. приз-ка в сово-сти, - частота (в совокупности!)
Внутригрупповая
дисперсия:
![]() - кол-во вариант в группе i
- кол-во вариант в группе i
Междугрупповая
дисперсия:
![]() - кол-во вариант в группе i
- кол-во вариант в группе i
Правило
сложения дисперсий:
![]()
Не имеет еди-ц измерения.
5) Коэффициент вариации хар-ет ср. относит. откл-ние вар-ты от ср. вел-ны.
Способ моментов
Часто мы сталкиваемся с расчетом средней арифметической упрощенным способом.
В этом случае используются свойства средней величины. Метод упрощенного расчета называется способом моментов, либо способом отсчета от условного нуля.
Способ моментов предполагает следующие действия :
1) Выбирается начало отсчета (из х ) – условный нуль (A ). Обычно как можно ближе к середине распре-ния.
2) Находятся отклонения вариантов от условного нуля ().
4) Если эти отклонения содержат общий множитель (k ), то рассчитанные
отклонения делятся на этот множитель.
Способ моментов :

Средняя:
![]()
Дисперсия:
![]()
Тема 4: Выборочное наблюдение
Обозначения в теории выборки:
|
N – числи-ль генер. выборки |
n – числи-ль генер. выборки |
|
Генер. средняя (оценивают) |
– выбор. средняя (рассчитывают) |
|
p – генер. доля (оценивают) |
w – выбор. доля (рассчитывают) |
|
P (t ) – задаваемый уровень веро-сти |
|
Генер. средняя: с задан. уровнем вероя-сти P(t)
– ошибка выборки для ср. вел-ны
, t – критерий надеж-сти, его вел-на зав-т от уровня задан. вероя-сти P(t)
Если 1) P (t ) = 0,683, то t =1 ; 2) P (t ) = 0,954, то t =2 ; 3) P (t ) = 0,997, то t =3
– среднеквадр. ошибка выборки
– верна для повторного отбора в выборке.
 - для бесповторного отбора
- для бесповторного отбора
Доказано: с задан. уровнем вероя-сти P(t)
– ошибка выборки для доли
, – среднеквадр. ошибка выборки для доли
 –для повторного отбора
–для повторного отбора
 - для бесповторного отбора
- для бесповторного отбора
Тема 5: Ряды динамики
Аналит. пока-ли:
1) Абсолют. прирост (разница уровней)
(цепной) ; (базисный)
2) Темп роста (отношение уровней)
(цепной) ; (базисный)
3) Темп прироста
![]() (цепной) ;
(цепной) ; ![]() (базисный)
(базисный)
4) Абсолютное значение 1% прироста
![]() (цепной) ;
(цепной) ; ![]() (базисный)
(базисный)
Средние показатели:
1) ср. уровни динам. ряда ;
2) ср. аналитич. показ-ли динам. ряда .
Расчет ср. уровня зав-т от вида РД:
а) для интерв. РД с равн. периодами вре-ни – ср. арифмет. простая
б) для интерв. РД с неравн. периодами вре-ни – ср. арифмет. взвешенная
в) для моментных РД с равноотстоящими датами – ср. хронологическая
г) для моментных РД с неравноотстоящими датами – ср. арифмет. взвешенная
Расчет ср. аналит. показ-лей:
а)
ср.
абсолют. прирост
![]()
б) ср. темп роста
в)
ср.
темп прироста
![]()
Смыкание РД
Для проведения смыкания РД в смыкаемых рядах находится временной момент (дата, период), когда им-ся сведения об изучаемом признаке как в прежних, так и в новых условиях. Рассчитывается коэфф-т, дальнейш. расчеты – по сомкнутом. ряду.
В ходе обработки РД важн. задачей яв-ся выявление основ. тенденции раз-тия явления (тренда) и сглаживание случ. колебаний. Для решения этой задачи сущ-ют особые способы, кот. наз-ют методами выравнивания.
3 основн. способа обработки динамического ряда:
а) укрупнение интервалов РД и расчет средних для кажд. укрупненного интервала;
(переход от менее продолжит.инт-лов к более продолжит. Средняя, рассчитанная по укрупненным инт-лам, позволяет выявить направление и характер (ускорение или замедление) основ. тенденции развития. Средняя рассчитывается по формулам простой средней арифметической.
б) метод скользящей средней;
(вычисл-ся ср. уровень из опред. числа, обычно нечетного, первых по счету уровней ряда. Затем - из такого же числа уровней, но начиная со второго по счету, далее - начиная с третьего и т. д. Т/о, средняя как бы «скользит» по временному ряду от его начала к концу, каждый раз отбрасывая один уровень в начале и добавляя один следующий.
в) аналитическое выравнивание.
Сезонные колебания и волны
Индексами сезонности яв-ся процентные отношения фактических внутригодовых уровней к постоянной или переменной средней. Совокупность этих показателей отражает сезонную волну.
Для выявления сезон. колебаний обычно испо-ют данные за несколько лет, распределенные по месяцам. Для каждого месяца рассчитывается средняя величина уровня, например за 3 года ( ), затем из них вычисляется средний уровень для всего ряда ( ), далее определяется процентное отношение средних для каждого месяца к общему среднемесячному уровню ряда:
![]()
где - средний уровень для каждого месяца;
Среднемесячный уровень для всего ряда.
Для наглядного представления сезонной волны индексы сезонности изображают в виде графиков.
Индивидуальные индексы:
|
себестоимости |
стоимости |
денежных затрат |
затрат труда |
||
|
i q |
i p |
i z |
i pq |
i qz |
i qt |
Общие индексы:
|
Общий индекс физического объема (как в среднем изм-лось кол-во товаров на рынке) | |
|
Абсолютное изм-ние стои-сти за счет изм-ния кол-ва товаров |
|
|
Общий индекс цен (агрегатный) (как в среднем изм-лись цены на рынке) | |
|
Абсолютное изм-ние стои-сти за счет изм-ния цен |
|
|
Общий индекс товарооборота (стоимости) общ. относит. изме-ния стои-сти товаров на рынке |
|
|
Общ. абсолют. изм-ние стои-сти товаров на рынке |
|
|
Взаимосвязь индексов |
I pq = I p I q |
|
Общий индекс себестоимости | |
|
Общий индекс физич. объема (по себестоимости) | |
|
Взаимосвязь между индексами | |
|
Общий индекс затрат на производство |

(называемых моментами или моментными функциями ) , интегрируемых по мере , выполнены условия на моменты
Пусть - выборка случайной величины X. Предполагается, что соотношения аналогичные условиям на моменты выполнены и для выборки, а именно вместо математического ожидания в условиях на моменты необходимо использовать выборочные средние:
причем в данном представлении (когда справа от равенства - ноль) достаточно использовать просто суммы вместо средних.
Оценки, получаемые из решения этой системы уравнений (выборочных условий на моменты), называются оценками метода моментов . Название метода связано с тем, что чаще всего в качестве функций выступают функции степенного вида, математические ожидания от которых в теории вероятностей и математической статистике принято называть моментами.
Если моментные функции непрерывны, то оценки метода моментов состоятельны .
Частные случаи
Некоторые классические методы оценки регрессионных моделей можно представить как частные случаи метода моментов. Например, если линейная регрессионная модель удовлетворяет условию , то условия на моменты выглядят следующим образом:
Следовательно, в этом случае оценка метода моментов будет совпадать с оценкой метода наименьших квадратов
Таким образом, МНК является частным случаем метода моментов, когда выполняется условие ортогональности регрессоров и случайных ошибок
Рассмотрим другой случай, когда имеются некоторые переменные z, ортогональные случайным ошибкам линейной регрессионной модели, то есть . Тогда имеем выборочный аналог этого условия:
Следовательно оценка метода моментов будет совпадать с оценкой метода инструментальных переменных : .
В некоторых случаях, редких при больших объемах данных и более частых при малом их количестве, оценки, даваемые методом моментов могут оказаться вне допустимой области. Такая проблема никогда не возникает в методе максимального правдоподобия. Также, оценки по методу моментов не обязательно оказываются достаточной статистикой , то есть, они иногда извлекают из данных не всю имеющуюся в них информацию.
См. также
Wikimedia Foundation . 2010 .
Смотреть что такое "Метод моментов" в других словарях:
метод моментов - momentų metodas statusas T sritis fizika atitikmenys: angl. method of moments; moments method vok. Momentenmethode, f rus. метод моментов, m pranc. méthode de moments, f … Fizikos terminų žodynas
В математической статистике это способ построения оценок, основанный на уравнивании теоретических и выборочных моментов. (Пирсон 1894г.) Содержание 1 Определение 2 Замечания … Википедия
- (ОММ, GMM Generalized Method of Moments) метод, применяемый в математической статистике и эконометрике для оценки неизвестных параметров распределений и эконометрических моделей, являющийся обобщением классического метода моментов. Метод был… … Википедия
- (ИП, IV Instrumental Variables) метод оценки параметров регрессионных моделей, основанный на использовании дополнительных, не участвующих в модели, так называемых инструментальных переменных. Метод применяется в случае, когда факторы… … Википедия
Или метод наибольшего правдоподобия (ММП, ML, MLE Maximum Likelihood Estimation) в математической статистике это метод оценивания неизвестного параметра путём максимизации функции правдоподобия. Основан на предположении о том, что… … Википедия
метод распределения моментов - Метод расчёта сложных статически неопределимых рам, при котором первоначально неуравновешенные моменты в узлах уравновешиваются по методу последовательных приближений с помощью коэффициентов распределения моментов [Терминологический словарь по… … Справочник технического переводчика
Метод определения распределения вероятностей по его моментам. В теоретич. отношении М. м. основан на единственности решения моментов проблемы:если нек рые постоянные, то при каких условиях существует единственное распределение такое, что суть… … Математическая энциклопедия
Метод расчёта сложных статически неопределимых рам, при котором первоначально неуравновешенные моменты в узлах уравновешиваются по методу последовательных приближений с помощью коэффициентов распределения моментов (Болгарский язык; Български)… … Строительный словарь
- (от греч. methodos путь, способ исследования, обучения, изложения) совокупность приемов и операций познания и практической деятельности; способ достижения определенных результатов в познании и практике. Применение того или иного М. определяется… … Философская энциклопедия
- (лат. associatio соединение, присоединение) исследовательский, диагностический и терапевтический прием психоанализа. Основан на использовании феномена ассоциативности мышления для познания глубинных (преимущественно бессознательных) психических… … Новейший философский словарь
Книги
- Электродинамическое моделирование антенных и СВЧ структур с использованием FEKO , Курушин Александр Александрович, Банков Сергей Евгеньевич, Грибанов Александр Николаевич. Данная книга представляет собой систематическое описание одной из самых мощных современных программ электродинамического моделирования - FEKO. Программа FEKO имеет мощную систему черчения…







