
Статистическая значимость результата (p-значение) представляет собой оцененную меру уверенности в его «истинности» (в смысле «репрезентативности выборки»). Выражаясь более технически, p-значение ‑ это показатель, находящийся в убывающей зависимости от надежности результата. Более высокое p-значение соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-значение представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, p-значение=0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Иными словами, если данная зависимость в популяции отсутствует, а вы многократно проводили бы подобные эксперименты, то примерно в одном из двадцати повторений эксперимента можно было бы ожидать такой же или более сильной зависимости между переменными.
Во многих исследованиях p-значение=0.05 рассматривается как «приемлемая граница» уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым». Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 0.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p 0.01 обычно рассматриваются как статистически значимые, а результаты с уровнем p 0.005 или p 0.001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Как было уже сказано, величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Говоря общим языком, чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна.
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена.
Объем выборки влияет на значимость зависимости. Если наблюдений мало, то соответственно имеется мало возможных комбинаций значений этих переменных и таким образом, вероятность случайного обнаружения комбинации значений, показывающих сильную зависимость, относительно велика.
Как вычисляется уровень статистической значимости. Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: «насколько значима эта зависимость?» Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ: «в зависимости от обстоятельств». Именно, значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными. Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно «насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет». Другими словами, эта функция давала бы уровень значимости (p-значение), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.
ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ
- англ. credibility /validity, statistical; нем. Validitat, statistische. Последовательность, объективность и отсутствие неясности в статистическом тесте или в к.-л. наборе измерений. Д. с. может быть проверена повторением того же теста (или вопросника) по отношению к тому же самому субъекту, чтобы убедиться, будут ли получены такие же результаты; или сравнением различных частей теста, которыми предполагают измерить один и тот же объект.
Antinazi. Энциклопедия социологии , 2009
Смотреть что такое "ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ" в других словарях:
ДОСТОВЕРНОСТЬ СТАТИСТИЧЕСКАЯ - англ. credibility /validity, statistical; нем. Validitat, statistische. Последовательность, объективность и отсутствие неясности в статистическом тесте или в к. л. наборе измерений. Д. с. может быть проверена повторением того же теста (или… … Толковый словарь по социологии
В статистике величину называют статистически значимой, если мала вероятность её случайного возникновения или еще более крайних величин. Здесь под крайностью понимается степень отклонения тестовой статистики от нуль гипотезы. Разница называется… … Википедия
Физическое явление статистической устойчивости состоит в том, что при увеличении величины выборки частота случайного события или среднее значение физической величины стремится к некоторому фиксированному числу. Феномен статистической… … Википедия
ДОСТОВЕРНОСТЬ РАЗЛИЧИЯ (сходства) - аналитико статистическая процедура установления уровня значимости различий или сходств между выборками по изучаемым показателям (переменным) … Современный образовательный процесс: основные понятия и термины
ОТЧЕТНОСТЬ, СТАТИСТИЧЕСКАЯ Большой бухгалтерский словарь
ОТЧЕТНОСТЬ, СТАТИСТИЧЕСКАЯ - форма государственного статистического наблюдения, при которой соответствующие органы получают от предприятий (организаций и учреждений) необходимые им сведения в виде уставленных в законном порядке отчетных документов (статистических отчетов) за … Большой экономический словарь
Наука, занимающаяся изучением приемов систематического наблюдения над массовыми явлениями социальной жизни человека, составления численных их описаний и научной обработки этих описаний. Таким образом, теоретическая статистика есть наука… … Энциклопедический словарь Ф.А. Брокгауза и И.А. Ефрона
Коэффициент корреляции - (Correlation coefficient) Коэффициент корреляции это статистический показатель зависимости двух случайных величин Определение коэффициента корреляции, виды коэффициентов корреляции, свойства коэффициента корреляции, вычисление и применение… … Энциклопедия инвестора
Статистика - (Statistics) Статистика это общетеоретическая наука, изучающая количественные изменения в явлениях и процессах. Государственная статистика, службы статистики, Росстат (Госкомстат), статистические данные, статистика запросов, статистика продаж,… … Энциклопедия инвестора
Корреляция - (Correlation) Корреляция это статистическая взаимосвязь двух или нескольких случайных величин Понятие корреляции, виды корреляции, коэффициент корреляции, корреляционный анализ, корреляция цен, корреляция валютных пар на Форекс Содержание… … Энциклопедия инвестора
Книги
- Исследование в математике и математика в исследовании: Методический сборник по исследовательской деятельности учащихся , Борзенко В.И.. В сборнике представлены методические разработки, применимые в организации исследовательской деятельности учащихся. Первая часть сборника посвящена применению исследовательского подхода в…
Статистика давно уже стала неотъемлемой частью жизни. С ней люди сталкиваются всюду. На основе статистики делаются выводы о том, где и какие заболевания распространены, что более востребовано в конкретном регионе или среди определенного слоя населения. На основываются даже построения политических программ кандидатов в органы власти. Ими же пользуются и торговые сети при закупке товаров, а производители руководствуются этими данными в своих предложениях.
Статистика играет важную роль в жизни общества и влияет на каждого его отдельного члена даже в мелочах. Например, если по , большинство людей предпочитают темные цвета в одежде в конкретном городе или регионе, то найти яркий желтый плащ с цветочным принтом в местных торговых точках будет крайне затруднительно. Но из каких величин складываются эти данные, оказывающие такое влияние? К примеру, что представляет собой «статистическая значимость»? Что именно понимается под этим определением?
Что это?
Статистика как наука складывается из сочетания разных величин и понятий. Одним из них и является понятие «статистическая значимость». Так называется значение переменных величин, вероятность появления других показателей в которых ничтожно мала.
К примеру, 9 из 10 человек надевают на ноги резиновую обувь во время утренней прогулки за грибами в осенний лес после дождливой ночи. Вероятность того что в какой-то момент 8 из них обуются в парусиновые мокасины - ничтожно мала. Таким образом, в данном конкретном примере число 9 является величиной, которая и называется «статистическая значимость».
Соответственно, если развивать далее приведенный практический пример, обувные магазины закупают к концу летнего сезона резиновые сапожки в большом количестве, чем в другое время года. Так, величина статистического значения оказывает влияние на обычную жизнь.
Разумеется, в сложных подсчетах, допустим, при прогнозе распространения вирусов, учитывается большое число переменных. Но сама суть определения значимого показателя статистических данных - аналогична, вне зависимости от сложности подсчетов и количества непостоянных величин.
Как вычисляют?
Используются при вычислении значения показателя «статистическая значимость» уравнения. То есть можно утверждать, что в этом случае все решает математика. Самым простым вариантом вычисления является цепь математических действий, в которой участвуют следующие параметры:
- два типа результатов, полученных при опросах или изучении объективных данных, к примеру, сумм на которые совершаются покупки, обозначаемые а и b;
- показатель для обеих групп - n;
- значение доли объединенной выборки - p;
- понятие «стандартная ошибка» - SE.
Следующим этапом определяется общий тестовый показатель - t, его значение сравнивается с числом 1,96. 1,96 - это усредненное значение, передающее диапазон в 95 %, согласно функции t-распределения Стьюдента.
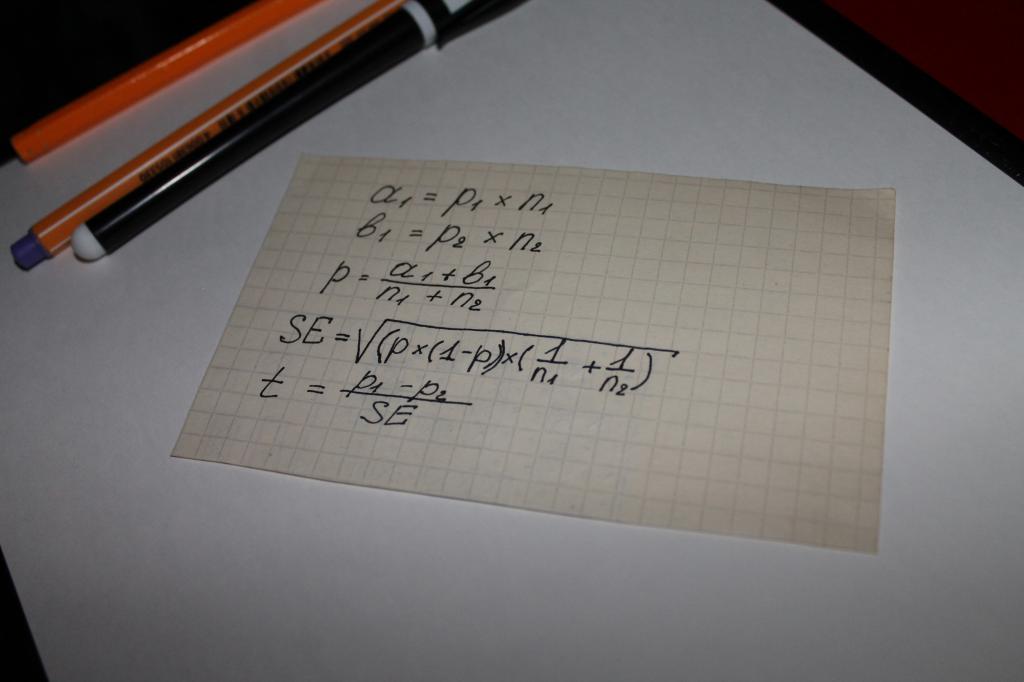
Часто возникает вопрос о том, в чем отличие значений n и p. Этот нюанс просто прояснить при помощи примера. Допустим, вычисляется статистическая значимость лояльности к какому-либо товару или бренду мужчин и женщин.
В этом случае за буквенными обозначениями будет стоять следующее:
- n - число опрошенных;
- p - число довольных продуктом.
Численность опрошенных женщин в этом случае будет обозначено, как n1. Соответственно, мужчин - n2. То же значение будут иметь цифры «1» и «2» у символа p.
Сравнение тестового показателя с усредненными значениями расчетных таблиц Стьюдента и становится тем, что называется «статистическая значимость».
Что понимается под проверкой?
Результаты любого математического вычисления всегда можно проверить, этому учат детей еще в начальных классах. Логично предположить, что раз статистические показатели определяются при помощи цепи вычислений, то и проверяются.
Однако проверка статистической значимости - не только математика. Статистика имеет дело с большим количеством переменных величин и различных вероятностей, далеко не всегда поддающихся расчету. То есть если вернутся к приведенному в начале статьи примеру с резиновой обувью, то логичное построение статистических данных, на которые станут опираться закупщики товаров для магазинов, может быть нарушено сухой и жаркой погодой, которая не типична для осени. В результате этого явления число людей, приобретающих резиновые сапоги, снизится, а торговые точки потерпят убытки. Предусмотреть погодную аномалию математическая формула, разумеется, не в состоянии. Этот момент называется - «ошибка».

Вот как раз вероятность таких ошибок и учитывает проверка уровня вычисленной значимости. В ней учитываются как вычисленные показатели, так и принятые уровни значимости, а также величины, условно называемые гипотезами.
Что такое уровень значимости?
Понятие «уровень» входит в основные критерии статистической значимости. Используется оно в прикладной и практической статистике. Это своего рода величина, учитывающая вероятность возможных отклонений или ошибок.
Уровень основывается на выявлении различий в готовых выборках, позволяет установить их существенность либо же, наоборот, случайность. У этого понятия есть не только цифровые значения, но и их своеобразные расшифровки. Они объясняют то, как нужно понимать значение, а сам уровень определяется сравнением результата с усредненным индексом, это и выявляет степень достоверности различий.

Таким образом, можно представить понятие уровня просто - это показатель допустимой, вероятной погрешности или же ошибки в сделанных из полученных статистических данных выводах.
Какие уровни значимости используются?
Статистическая значимость коэффициентов вероятности допущенной ошибки на практике отталкивается от трех базовых уровней.
Первым уровнем считается порог, при котором значение равно 5 %. То есть вероятность погрешности не превышает уровня значимости в 5 %. Это означает, что уверенность в безупречности и безошибочности выводов, сделанных на основе данных статистических исследований, составляет 95 %.
Вторым уровнем является порог в 1 %. Соответственно, эта цифра означает, что руководствоваться полученными при статистических расчетах данными можно с уверенностью в 99 %.
Третий уровень - 0,1 %. При таком значении вероятность наличия ошибки равна доле процента, то есть погрешности практически исключаются.
Что такое гипотеза в статистике?
Ошибки как понятие разделяются по двум направлениям, касающимся принятия или же отклонения нулевой гипотезы. Гипотеза - это понятие, за которым скрывается, согласно определению, набор иных данных или же утверждений. То есть описание вероятностного распределения чего-либо, относящегося к предмету статистического учета.

Гипотез при простых расчетах бывает две - нулевая и альтернативная. Разница между ними в том, что нулевая гипотеза берет за основу представление об отсутствии принципиальных отличий между участвующими в определении статистической значимости выборками, а альтернативная ей полностью противоположна. То есть альтернативная гипотеза основана на наличии весомой разницы в данных выборок.
Какими бывают ошибки?
Ошибки как понятие в статистике находятся в прямой зависимости от принятия за истинную той или иной гипотезы. Их можно разделить на два направления или же типа:
- первый тип обусловлен принятием нулевой гипотезы, оказавшейся неверной;
- второй - вызван следованием альтернативной.

Первый тип ошибок называется ложноположительным и встречается достаточно часто во всех сферах, где используются статистические данные. Соответственно, ошибка второго типа называется ложноотрицательной.
Для чего нужна регрессия в статистике?
Статистическая значимость регрессии в том, что с ее помощью можно установить, насколько соответствует реальности вычисленная на основе данных модель различных зависимостей; позволяет выявить достаточность или же нехватку факторов для учета и выводов.
Определяется регрессивное значение с помощью сравнения результатов с перечисленными в таблицах Фишера данными. Или же при помощи дисперсионного анализа. Важное значение показатели регрессии имеют при сложных статистических исследованиях и расчетах, в которых участвует большое количество переменных величин, случайных данных и вероятных изменений.
Проверка гипотез проводится с помощью статистического анализа. Статистическую значимость находят с помощью Р-значения, которое соответствует вероятности данного события при предположении, что некоторое утверждение (нулевая гипотеза) истинно. Если Р-значение меньше заданного уровня статистической значимости (обычно это 0,05), экспериментатор может смело заключить, что нулевая гипотеза неверна, и перейти к рассмотрению альтернативной гипотезы. С помощью t-критерия Стьюдента можно вычислить Р-значение и определить значимость для двух наборов данных.
Шаги
Часть 1
Постановка эксперимента- Нулевая гипотеза (H 0) обычно утверждает, что между двумя наборами данных нет разницы. Например: те ученики, которые читают материал перед занятиями, не получают более высокие оценки.
- Альтернативная гипотеза (H a) противоположна нулевой гипотезе и представляет собой утверждение, которое нужно подтвердить с помощью экспериментальных данных. Например: те ученики, которые читают материал перед занятиями, получают более высокие оценки.
-
Установите уровень значимости, чтобы определить, насколько распределение данных должно отличаться от обычного, чтобы это можно было считать значимым результатом. Уровень значимости (его называют также α {\displaystyle \alpha } -уровнем) - это порог, который вы определяете для статистической значимости. Если Р-значение меньше уровня значимости или равно ему, данные считаются статистически значимыми.
- Как правило, уровень значимости (значение α {\displaystyle \alpha } ) принимается равным 0,05, и в этом случае вероятность обнаружения случайной разницы между разными наборами данных составляет всего лишь 5%.
- Чем выше уровень значимости (и, соответственно, меньше Р-значение), тем достовернее результаты.
- Если вы хотите получить более достоверные результаты, понизьте Р-значение до 0,01. Как правило, более низкие Р-значения используются в производстве, когда необходимо выявить брак в продукции. В этом случае требуется высокая достоверность, чтобы быть уверенным, что все детали работают так, как положено.
- Для большинства экспериментов с гипотезами достаточно принять уровень значимости равным 0,05.
-
Решите, какой критерий вы будете использовать: односторонний или двусторонний. Одно из предположений в t-критерии Стьюдента гласит, что данные распределены нормальным образом. Нормальное распределение представляет собой колоколообразную кривую с максимальным количеством результатов посередине кривой. t-критерий Стьюдента - это математический метод проверки данных, который позволяет установить, выпадают ли данные за пределы нормального распределения (больше, меньше, либо в “хвостах” кривой).
- Если вы не уверены, находятся ли данные выше или ниже контрольной группы значений, используйте двусторонний критерий. Это позволит вам определить значимость в обоих направлениях.
- Если вы знаете, в каком направлении данные могут выйти за пределы нормального распределения, используйте односторонний критерий. В приведенном выше примере мы ожидаем, что оценки студентов повысятся, поэтому можно использовать односторонний критерий.
-
Определите объем выборки с помощью статистической мощности. Статистическая мощность исследования - это вероятность того, что при данном объеме выборки получится ожидаемый результат. Распространенный порог мощности (или β) составляет 80%. Анализ статистической мощности без каких-либо предварительных данных может представлять определенные сложности, поскольку требуется некоторая информация об ожидаемых средних значениях в каждой группе данных и об их стандартных отклонениях. Используйте для анализа статистической мощности онлайн-калькулятор, чтобы определить оптимальный объем выборки для ваших данных.
- Обычно ученые проводят небольшое пробное исследование, которое позволяет получить данные для анализа статистической мощности и определить объем выборки, необходимый для более расширенного и полного исследования.
- Если у вас нет возможности провести пробное исследование, постарайтесь на основании литературных данных и результатов других людей оценить возможные средние значения. Возможно, это поможет вам определить оптимальный объем выборки.
Часть 2
Вычислите стандартное отклонение-
Запишите формулу для стандартного отклонения. Стандартное отклонение показывает, насколько велик разброс данных. Оно позволяет заключить, насколько близки данные, полученные на определенной выборке. На первый взгляд формула кажется довольно сложной, но приведенные ниже объяснения помогут понять ее. Формула имеет следующий вид: s = √∑((x i – µ) 2 /(N – 1)).
- s - стандартное отклонение;
- знак ∑ указывает на то, что следует сложить все полученные на выборке данные;
- x i соответствует i-му значению, то есть отдельному полученному результату;
- µ - это среднее значение для данной группы;
- N - общее число данных в выборке.
-
Найдите среднее значение в каждой группе. Чтобы вычислить стандартное отклонение, необходимо сначала найти среднее значение для каждой исследуемой группы. Среднее значение обозначается греческой буквой µ (мю). Чтобы найти среднее, просто сложите все полученные значения и поделите их на количество данных (объем выборки).
- Например, чтобы найти среднюю оценку в группе тех учеников, которые изучают материал перед занятиями, рассмотрим небольшой набор данных. Для простоты используем набор из пяти точек: 90, 91, 85, 83 и 94.
- Сложим вместе все значения: 90 + 91 + 85 + 83 + 94 = 443.
- Поделим сумму на число значений, N = 5: 443/5 = 88,6.
- Таким образом, среднее значение для данной группы составляет 88,6.
-
Вычтите из среднего каждое полученное значение. Следующий шаг заключается в вычислении разницы (x i – µ). Для этого следует вычесть из найденной средней величины каждое полученное значение. В нашем примере необходимо найти пять разностей:
- (90 – 88,6), (91- 88,6), (85 – 88,6), (83 – 88,6) и (94 – 88,6).
- В результате получаем следующие значения: 1,4, 2,4, -3,6, -5,6 и 5,4.
-
Возведите в квадрат каждую полученную величину и сложите их вместе. Каждую из только что найденных величин следует возвести в квадрат. На этом шаге исчезнут все отрицательные значения. Если после данного шага у вас останутся отрицательные числа, значит, вы забыли возвести их в квадрат.
- Для нашего примера получаем 1,96, 5,76, 12,96, 31,36 и 29,16.
- Складываем полученные значения: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Поделите на объем выборки минус 1. В формуле сумма делится на N – 1 из-за того, что мы не учитываем генеральную совокупность, а берем для оценки выборку из числа всех студентов.
- Вычитаем: N – 1 = 5 – 1 = 4
- Делим: 81,2/4 = 20,3
-
Извлеките квадратный корень. После того как вы поделите сумму на объем выборки минус один, извлеките из найденного значения квадратный корень. Это последний шаг в вычислении стандартного отклонения. Есть статистические программы, которые после введения начальных данных производят все необходимые вычисления.
- В нашем примере стандартное отклонение оценок тех учеников, которые читают материал перед занятиями, составляет s =√20,3 = 4,51.
Часть 3
Определите значимость-
Рассчитайте дисперсию между двумя группами данных. До этого шага мы рассматривали пример лишь для одной группы данных. Если вы хотите сравнить две группы, очевидно, следует взять данные для обеих групп. Вычислите стандартное отклонение для второй группы данных, а затем найдите дисперсию между двумя экспериментальными группами. Дисперсия вычисляется по следующей формуле: s d = √((s 1 /N 1) + (s 2 /N 2)).
Определите свою гипотезу. Первый шаг при оценке статистической значимости состоит в том, чтобы выбрать вопрос, ответ на который вы хотите получить, и сформулировать гипотезу. Гипотеза - это утверждение об экспериментальных данных, их распределении и свойствах. Для любого эксперимента существует как нулевая, так и альтернативная гипотеза. Вообще говоря, вам придется сравнивать два набора данных, чтобы определить, схожи они или различны.
Статистическая значимость
Результаты, полученные с помощью определенной процедуры исследования, называют статистически значимыми , если вероятность их случайного появления очень мала. Эту концепцию можно проиллюстрировать на примере кидания монеты. Предположим, что монету подбросили 30 раз; 17 раз выпал «орел» и 13 раз выпала «решка». Является ли значимым отклонение этого результата от ожидаемого (15 выпадений «орла» и 15 - «решки»), или это отклонение случайно? Чтобы ответить на этот вопрос, можно, например, много раз кидать ту же монету по 30 раз подряд, и при этом отмечать, сколько раз повторится соотношение «орлов» и «решек», равное 17:13. Статистический анализ избавляет нас от этого утомительного процесса. С его помощью после первых 30 киданий монеты можно произвести оценку возможного числа случайных выпадений 17 «орлов» и 13 «решек». Такая оценка называется вероятностным утверждением.
В научной литературе по индустриально-организационной психологии вероятностное утверждение в математической форме обозначается выражением р (вероятность) < (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (р < 0,01). Этот факт важен для понимания литературы, но не следует считать, что он говорит о бессмысленности проведения наблюдений, не соответствующих этим стандартам. Так называемые незначимые результаты исследований (наблюдения, которые можно получить случайно более одного или пяти раз из 100) могут быть весьма полезными для выявления тенденций и как руководство к будущим исследованиям.
Необходимо также заметить, что не все психологи соглашаются с традиционными стандартами и процедурами (например, Cohen, 1994; Sauley & Bedeian, 1989). Вопросы, связанные с измерениями, сами по себе являются главной темой работы многих исследователей, изучающих точность методов измерений и предпосылки, которые лежат в основе существующих методов и стандартов, а также разрабатывают новые медики и инструменты. Может быть, когда-нибудь в будущем исследования в этой власти приведут к изменению традиционных стандартов оценки статистической значимости, и эти изменения завоюют всеобщее признание. (Пятое отделение Американской психологической ассоциации объединяет психологов, которые специализируются на изучении оценок, измерений и статистики.)
В отчетах об исследованиях вероятностное утверждение, такое как р < 0,05, связано некоторой статистикой, то есть числом, которое получено в результате проведения определенного набора математических вычислительных процедур. Вероятностное подтверждение получают путем сравнения этой статистики с данными из специальных таблиц, которые публикуются для этой цели. В индустриально-организационных психологических исследованиях часто встречаются такие статистики, как r, F, t, г> (читается «хи квадрат») и R (читается «множественный R»). В каждом случае статистику (одно число), полученную в результате анализа серии наблюдений, можно сравнить числами из опубликованной таблицы. После этого можно сформулировать вероятностное утверждение о вероятности случайного получения этого числа, то есть сделать вывод о значимости наблюдений.
Для понимания исследований, описанных в этой книге, достаточно иметь ясное представление о концепции статистической значимости и необязательно знать, как рассчитываются упомянутые выше статистики. Однако было бы полезно обсудить одно предположение, которое лежит в основе всех этих процедур. Это предположение о том, что все наблюдаемые переменные распределяются приблизительно по нормальному закону. Кроме того, при чтении отчетов об индустриально-организационных психологических исследованиях часто встречаются еще три концепции, которые играют важную роль - во-первых, корреляция и корреляционная связь, во-вторых, детерминант/ предсказывающая переменная и «ANOVA» (дисперсионный анализ), в-третьих, группа статистических методов под общим названием «метаанализ».







