Статистическая совокупность - множество единиц, обладающих массовостью, типичностью, качественной однородностью и наличием вариации.
Статистическая совокупность состоит из материально существующих объектов (Работники, предприятия, страны, регионы), является объектом .
Единица совокупности — каждая конкретная единица статистической совокупности.
Одна и таже статистическая совокупность может быть однородна по одному признаку и неоднородна по другому.
Качественная однородность — сходство всех единиц совокупности по какому-либо признаку и несходство по всем остальным.
В статистической совокупности отличия одной единицы совокупности от другой чаще имеют количественную природу. Количественные изменения значений признака разных единиц совокупности называются вариацией.
Вариация признака — количественное изменение признака (для количественного признака) при переходе от одной единицы совокупности к другой.
Признак - это свойство, характерная черта или иная особенность единиц, объектов и явлений, которая может быть наблюдаема или измерена. Признаки делятся на количественные и качественные. Многообразие и изменчивость величины признака у отдельных единиц совокупности называется вариацией .
Атрибутивные (качественные) признаки не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое выражение (состав населения по возрасту).
Показатель — это обобщающая количественно качестванная характеристика какого-либо свойства единиц или совокупности в цельм в конкретных условиях времени и места.
Система показателей — это совокупность показателей всесторонне отражающих изучаемое явление.
Например, изучается зарплата:- Признак — оплата труда
- Статистическая совокупность — все работники
- Единица совокупности — каждый работник
- Качественная однородность — начисленная зарплата
- Вариация признака — ряд цифр
Генеральная совокупность и выборка из нее
Основу составляет множество данных, полученных в результате измерения одного или нескольких признаков. Реально наблюдаемая совокупность объектов, статистически представленная рядом наблюдений случайной величины , является выборкой , а гипотетически существующая (домысливаемая) — генеральной совокупностью . Генеральная совокупность может быть конечной (число наблюдений N = const ) или бесконечной (N = ∞ ), а выборка из генеральной совокупности — это всегда результат ограниченного ряда наблюдений. Число наблюдений , образующих выборку, называется объемом выборки . Если объем выборки достаточно велик (n → ∞ ) выборка считается большой , в противном случае она называется выборкой ограниченного объема . Выборка считается малой , если при измерении одномерной случайной величины объем выборки не превышает 30 (n <= 30 ), а при измерении одновременно нескольких (k ) признаков в многомерном пространстве отношение n к k не превышает 10 (n/k < 10) . Выборка образует вариационный ряд , если ее члены являются порядковыми статистиками , т. е. выборочные значения случайной величины Х упорядочены по возрастанию (ранжированы), значения же признака называются вариантами .
Пример . Практически одна и та же случайно отобранная совокупность объектов — коммерческих банков одного административного округа Москвы, может рассматриваться как выборка из генеральной совокупности всех коммерческих банков этого округа, и как выборка из генеральной совокупности всех коммерческих банков Москвы, а также как выборка из коммерческих банков страны и т.д.
Основные способы организации выборки
Достоверность статистических выводов и содержательная интерпретация результатов зависит от репрезентативности выборки, т.е. полноты и адекватности представления свойств генеральной совокупности, по отношению к которой эту выборку можно считать представительной. Изучение статистических свойств совокупности можно организовать двумя способами: с помощью сплошного и несплошного . Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности , а несплошное (выборочное) наблюдение — только его части.
Существуют пять основных способов организации выборочного наблюдения:
1. простой случайный отбор , при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. Такие выборки называются собственно-случайными ;
2. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.) и полученные таким способом выборки называются механическими ;
3. стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что . Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). В этом случае выборки называются стратифицированными (иначе, расслоенными, типическими, районированными );
4. методы серийного отбора используются для формирования серийных или гнездовых выборок . Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала);
5. комбинированный (ступенчатый) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический); такая выборка называется комбинированной .
Виды отбора
По виду различаются индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности, при групповом отборе — качественно однородные группы (серии) единиц, а комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборку.
Бесповторным называется отбор, при котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует; при этом численность единиц генеральной совокупности N сокращается в процессе отбора. При повторном отборе попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной (метод в социально-экономических исследованиях применяется редко). Однако, при большом N (N → ∞) формулы для бесповторного отбора приближаются к аналогичным для повторного отбора и практически чаще используются последние (N = const ).
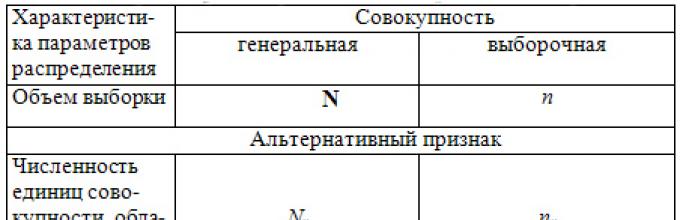
Основные характеристики параметров генеральной и выборочной совокупности
В основе статистических выводов проведенного исследования лежит распределение случайной величины , наблюдаемые же значения (х 1 , х 2 , … , х n) называются реализациями случайной величины Х (n — объем выборки). Распределение случайной величины в генеральной совокупности носит теоретический, идеальный характер, а ее выборочный аналог является эмпирическим распределением. Некоторые теоретические распределения заданы аналитически, т.е. их параметры определяют значение функции распределения в каждой точке пространства возможных значений случайной величины . Для выборки же функцию распределения определить трудно, а иногда невозможно, поэтому параметры оценивают по эмпирическим данным, а затем их подставляют в аналитическое выражение, описывающее теоретическое распределение. При этом предположение (или гипотеза ) о виде распределения может быть как статистически верным, так и ошибочным. Но в любом случае восстановленное по выборке эмпирическое распределение лишь грубо характеризует истинное. Важнейшими параметрами распределений являются математическое ожидание и дисперсия .
По своей природе распределения бывают непрерывными и дискретными . Наиболее известным непрерывным распределением является нормальное . Выборочными аналогами параметров идля него являются: среднее значение и эмпирическая дисперсия . Среди дискретных в социально-экономических исследованиях наиболее часто применяется альтернативное (дихотомическое) распределение. Параметр математического ожидания этого распределения выражает относительную величину (или долю ) единиц совокупности, которые обладают изучаемым признаком (она обозначена буквой ); доля совокупности, не обладающая этим признаком, обозначается буквой q (q = 1 — p) . Дисперсия же альтернативного распределения также имеет эмпирический аналог .
В зависимости от вида распределения и от способа отбора единиц совокупности по-разному вычисляются характеристики параметров распределения. Основные из них для теоретического и эмпирического распределений приведены в табл. 9.1.
Долей выборки k n называется отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
k n = n/N .
Выборочная доля w — это отношение единиц, обладающих изучаемым признаком x к объему выборки n :
w = n n /n .
Пример. В партии товара, содержащей 1000 ед., при 5% выборке доля выборки k n в абсолютной величине составляет 50 ед. (n = N*0,05); если же в этой выборке обнаружено 2 бракованных изделия, то выборочная доля брака w составит 0,04 (w = 2/50 = 0,04 или 4%).
Так как выборочная совокупность отлична от генеральной, то возникают ошибки выборки .
Таблица 9.1 Основные параметры генеральной и выборочной совокупностей
Ошибки выборки
При любом (сплошном и выборочном) могут встретиться ошибки двух видов: регистрации и репрезентативности. Ошибки регистрации могут иметь случайный и систематический характер. Случайные ошибки складываются из множества различных неконтролируемых причин, носят непреднамеренный характер и обычно по совокупности уравновешивают друг друга (например, изменения показателей прибора при температурных колебаниях в помещении).
Систематические ошибки тенденциозны, так как нарушают правила отбора объектов в выборку (например, отклонения в измерениях при изменении настройки измерительного прибора).
Пример. Для оценки социального положения населения в городе предусмотрено обследовать 25% семей. Если при этом выбор каждой четвертой квартиры основан на ее номере, то существует опасность отобрать все квартиры только одного типа (например, однокомнатные), что обеспечит систематическую ошибку и исказит результаты; выбор же номера квартиры по жребию более предпочтителен, так как ошибка будет случайной.
Ошибки репрезентативности присущи только выборочному наблюдению, их невозможно избежать и они возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Значения показателей, получаемых по выборке, отличаются от показателей этих же величин в генеральной совокупности (или получаемых при сплошном наблюдении).
Ошибка выборочного наблюдения есть разность между значением параметра в генеральной совокупности и ее выборочным значением. Для среднего значения количественного признака она равна: , а для доли (альтернативного признака) — .
Ошибки выборки свойственны только выборочным наблюдениям. Чем больше эти ошибки, тем больше эмпирическое распределение отличается от теоретического. Параметры эмпирического распределения и являются случайными величинами, следовательно, ошибки выборки также являются случайными величинами, могут принимать для разных выборок разные значения и поэтому принято вычислять среднюю ошибку .
Средняя ошибка выборки есть величина , выражающая среднее квадратическое отклонение выборочной средней от математического ожидания. Эта величина при соблюдении принципа случайного отбора зависит прежде всего от объема выборки и от степени варьирования признака: чем больше и чем меньше вариация признака (следовательно, и значение ), тем меньше величина средней ошибки выборки . Соотношение между дисперсиями генеральной и выборочной совокупностей выражается формулой:
т.е. при достаточно больших можно считать, что . Средняя ошибка выборки показывает возможные отклонения параметра выборочной совокупности от параметра генеральной. В табл. 9.2 приведены выражения для вычисления средней ошибки выборки при разных методах организации наблюдения.
Таблица 9.2 Средняя ошибка (m) выборочных средней и доли для разных видов выборки
Где - средняя из внутригрупповых выборочных дисперсий для непрерывного признака;
Средняя из внутригрупповых дисперсий доли;
— число отобранных серий, — общее число серий;
 ,
,
где — средняя -й серии;
— общая средняя по всей выборочной совокупности для непрерывного признака;
 ,
,
где — доля признака в -й серии;
— общая доля признака по всей выборочной совокупности.
Однако о величине средней ошибки можно судить лишь с определенной, вероятностью Р (Р ≤ 1). Ляпунов А.М. доказал, что распределение выборочных средних , a следовательно, и их отклонений от генеральной средней, при достаточно большом числе приближенно подчиняется нормальному закону распределения при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически это утверждение для средней выражается в виде:

а для доли выражение (1) примет вид:
где  -
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.
-
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.

Следовательно, выражение (3) может быть прочитано так: с вероятностью Р = 0,683 (68,3%) можно утверждать, что разность между выборочной и генеральной средней не превысит одной величины средней ошибки m (t = 1) , с вероятностью Р = 0,954 (95,4%) — что она не превысит величины двух средних ошибок m (t = 2) , с вероятностью Р = 0,997 (99,7%) — не превысит трех значений m (t = 3) . Таким образом, вероятность того, что эта разность превысит трехкратную величину средней ошибки определяет уровень ошибки и составляет не более 0,3% .
В табл. 9.3 приведены формулы для вычисления предельной ошибки выборки.
Таблица 9.3 Предельная ошибка (D) выборки для средней и доли (р) для разных видов выборочного наблюдения
Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности. При малых объемах выборки эмпирические оценки параметров ( и ) могут существенно отклоняться от их истинных значений ( и ). Поэтому возникает необходимость установить границы, в пределах которых для выборочных значений параметров ( и ) лежат истинные значения ( и ).
Доверительным интервалом какого-либо параметра θгенеральной совокупности называется случайная область значений этого параметра, которая с вероятностью близкой к 1 (надежностью ) содержит истинное значение этого параметра.
Предельная ошибка выборки Δ позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы , которые равны:
Нижняя граница доверительного интервала получена путем вычитания предельной ошибки из выборочного среднего (доли), а верхняя — путем ее добавления.
Доверительный интервал для средней использует предельную ошибку выборки и для заданного уровня достоверности определяется по формуле:
Это означает, что с заданной вероятностью Р
, которая называется доверительным уровнем и однозначно определяется значением t
, можно утверждать, что истинное значение средней лежит в пределах от ![]() ,а истинное значение доли — в пределах от
,а истинное значение доли — в пределах от
При расчете доверительного интервала для трех стандартных доверительных уровней Р = 95%, Р = 99% и Р = 99,9% значение выбирается по . Приложения в зависимости от числа степеней свободы . Если объем выборки достаточно велик, то соответствующие этим вероятностям значения t равны: 1,96, 2,58 и 3,29 . Таким образом, предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
Распространение результатов выборочного наблюдения на генеральную совокупность в социально-экономических исследованиях имеет свои особенности, так как требует полноты представительности всех ее типов и групп. Основой для возможности такого распространения является расчет относительной ошибки :

где Δ % - относительная предельная ошибка выборки; , .
Существуют два основных метода распространения выборочного наблюдения на генеральную совокупность: прямой пересчет и способ коэффициентов .
Сущность прямого пересчета заключается в умножении выборочного среднего значения!!\overline{x} на объем генеральной совокупности .
Пример . Пусть среднее число детей ясельного возраста в городе оценено выборочным методом и составило человека. Если в городе 1000 молодых семей, то число необходимых мест в муниципальных детских яслях получают умножением этой средней на численность генеральной совокупности N = 1000, т.е. составит 1200 мест.
Способ коэффициентов целесообразно использовать в случае, когда выборочное наблюдение проводится с целью уточнения данных сплошного наблюдения.
При этом используют формулу:
где все переменные — это численность совокупности:
Необходимый объем выборки
Таблица 9.4 Необходимый объем (n) выборки для разных видов организации выборочного наблюдения
При планировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки необходимо правильно оценить требуемый объем выборки . Этот объем может быть определен на основе допустимой ошибки при выборочном наблюдении исходя из заданной вероятности , гарантирующей допустимую величину уровня ошибки (с учетом способа организации наблюдения). Формулы для определения необходимой численности выборки n легко получить непосредственно из формул предельной ошибки выборки. Так, из выражения для предельной ошибки:
непосредственно определяется объем выборки n :
Эта формула показывает, что с уменьшением предельной ошибки выборки Δ существенно увеличивается требуемый объем выборки , который пропорционален дисперсии и квадрату критерия Стьюдента .
Для конкретного способа организации наблюдения требуемый объем выборки вычисляется согласно формулам, приведенным в табл. 9.4.
Практические примеры расчета
Пример 1. Вычисление среднего значения и доверительного интервала для непрерывного количественного признака.
Для оценки скорости расчета с кредиторами в банке проведена случайная выборка 10 платежных документов. Их значения оказались равными (в днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятностью Р = 0,954 определить предельную ошибку Δ выборочной средней и доверительные пределы среднего времени расчетов.
Решение. Среднее значение вычисляется по формуле из табл. 9.1 для выборочной совокупности
![]()
Дисперсия вычисляется по формуле из табл. 9.1.
![]()
Средняя квадратическая погрешность дня.
Ошибка средней вычисляется по формуле:
![]()
т.е. среднее значение равно x ± m = 12,0 ± 2,3 дней .
Достоверность среднего составила
![]()
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, и для Р = 0,954 уровня достоверности.
Таким образом, среднее значение равно `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. его истинное значение лежит в пределах от 7,4 до16,6 дней.
Использование таблицы Стьюдента. Приложения позволяет заключить, что для n = 10 — 1 = 9 степеней свободы полученное значение достоверно с уровнем значимости a £ 0,001, т.е. полученное значение среднего достоверно отличается от 0.
Пример 2. Оценка вероятности (генеральной доли) р.
При механическом выборочном способе обследования социального положения 1000 семей выявлено, что доля малообеспеченных семей составила w = 0,3 (30%) (выборка была 2% , т.е. n/N = 0,02 ). Необходимо с уровнем достоверности р = 0,997 определить показатель р малообеспеченных семей во всем регионе.
Решение. По представленным значениям функции Ф(t) найдем для заданного уровня достоверности Р = 0,997 значение t = 3 (см. формулу 3). Предельную ошибку доли w определим по формуле из табл. 9.3 для бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки в % составит:
Вероятность (генеральная доля) малообеспеченных семей в регионе составит р=w±Δ w , а доверительные пределы р вычисляются исходя из двойного неравенства:
w — Δ w ≤ p ≤ w — Δ w , т.е. истинное значение р лежит в пределах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким образом, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона составляет от 28,6% до 31,4%.
Пример 3. Вычисление среднего значения и доверительного интервала для дискретного признака, заданного интервальным рядом.
В табл. 9.5. задано распределение заявок на изготовление заказов по срокам их выполнения предприятием.
Таблица 9.5 Распределение наблюдений по срокам появленияРешение. Средний срок выполнения заявок вычисляется по формуле:
Средний срок составит:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 мес.
Тот же ответ получим, если используем данные о р i из предпоследней колонки табл. 9.5, используя формулу:
Заметим, что середина интервала для последней градации находится путем искусственного ее дополнения шириной интервала предыдущей градации равной 60 — 36 = 24 мес.
Дисперсия вычисляется по формуле
![]()
где х i - середина интервального ряда.
Следовательно!!\sigma = \frac {20^2 + 14^2 + 1 + 25^2 + 49^2}{4}, а средняя квадратическая погрешность .
Ошибка средней вычисляется по формуле мес., т.е. среднее значение равно!!\overline{x} ± m = 23,1 ± 13,4.
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, для 0,954 уровня достоверности:
Таким образом, среднее значение равно:
т.е. его истинное значение лежит в пределах от 0 до 50 мес.
Пример 4. Для определения скорости расчетов с кредиторами N = 500 предприятий корпорации в коммерческом банке необходимо провести выборочное исследование методом случайного бесповторного отбора. Определить необходимый объем выборки n, чтобы с вероятностью Р = 0,954 ошибка среднего значения выборки не превышала 3-х дней, если пробные оценки показали, что среднее квадратическое отклонение s составило 10 дней.
Решение . Для определения числа необходимых исследований n воспользуемся формулой для бесповторного отбора из табл. 9.4:

В ней значение t определяется из для уровня достоверности Р = 0,954. Оно равно 2. Среднее квадратическое значение s = 10, объем генеральной совокупности N = 500, а предельная ошибка среднего значения Δ x = 3. Подставляя эти значения в формулу, получим:
![]()
т.е. выборку достаточно составить из 41 предприятия, чтобы оценить требуемый параметр — скорость расчетов с кредиторами.
Рассмотрим подробно перечисленные выше способы формирования выборочной совокупности и возникающие при этом ошибки репрезентативности.
Собственно-случайная выборка основывается на отборе единиц из генеральной совокупности наугад без каких-либо элементов системности. Технически собственно-случайный отбор проводят методом жеребьевки (например, розыгрыши лотерей) или по таблице случайных чисел.
Собственно-случайный отбор «в чистом виде» в практике выборочного наблюдения применяется редко, но он является исходным среди других видов отбора, в нем реализуются основные принципы выборочного наблюдения. Рассмотрим некоторые вопросы теории выборочного метода и формулы ошибок для простой случайной выборки.
Ошибка выборочного наблюдения - это разность между величиной параметра в генеральной совокупности, и его величиной, вычисленной по результатам выборочного наблюдения. Для средней количественного признака ошибка выборки определяется
Показатель называется предельной ошибкой выборки.
Выборочная средняя является случайной величиной, которая может принимать различные значения в зависимости от того, какие единицы попали в выборку. Следовательно, ошибки выборки также являются случайными величинами и могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок - среднюю ошибку выборки, которая зависит от:
- 1) объема выборки: чем больше численность, тем меньше величина средней ошибки;
- 2) степени изменения изучаемого признака: чем меньше вариация признака, а, следовательно, и дисперсия, тем меньше средняя ошибка выборки.
При случайном повторном отборе средняя ошибка рассчитывается
Практически генеральная дисперсия точно не известна, но в теории вероятности доказано, что
Так как величина при достаточно больших n близка к 1, можно считать, что. Тогда средняя ошибка выборки может быть рассчитана:
Но в случаях малой выборки (при n30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле

При случайной бесповторной выборке приведенные формулы корректируются на величину. Тогда средняя ошибка бесповторной выборки:


Т.к. всегда меньше, то множитель () всегда меньше 1. Это значит, что средняя ошибка при бесповторном отборе всегда меньше, чем при повторном.
Механическая выборка применяется, когда генеральная совокупность каким-либо способом упорядочена (например, списки избирателей по алфавиту, телефонные номера, номера домов, квартир). Отбор единиц осуществляется через определенный интервал, который равен обратному значению процента выборки. Так при 2% выборке отбирается каждая 50 единица =1/0,02 , при 5% каждая 1/0,05=20 единица генеральной совокупности.
Начало отсчета выбирается разными способами: случайным образом, из середины интервала, со сменой начала отсчета. Главное при этом - избежать систематической ошибки. Например, при 5% выборке, если первой единицей выбрана 13-я, то следующие 33, 53, 73 и т.д.
По точности механический отбор близок к собственно-случайной выборке. Поэтому для определения средней ошибки механической выборки используют формулы собственно-случайного отбора.
При типическом отборе обследуемая совокупность предварительно разбивается на однородные, однотипные группы. Например, при обследовании предприятий это могут быть отрасли, подотрасли, при изучении населения - районы, социальные или возрастные группы. Затем осуществляется независимый выбор из каждой группы механическим или собственно-случайным способом.
Типическая выборка дает более точные результаты по сравнению с другими способами. Типизация генеральной совокупности обеспечивает представительство в выборке каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Следовательно, при нахождении ошибки типической выборки согласно правилу сложения дисперсий () необходимо учесть лишь среднюю из групповых дисперсий. Тогда средняя ошибка выборки:
при повторном отборе
при бесповторном отборе
где - средняя из внутригрупповых дисперсий в выборке.
Серийный (или гнездовой) отбор применяется в случае, когда генеральная совокупность разбита на серии или группы до начала выборочного обследования. Этими сериями могут быть упаковки готовой продукции, студенческие группы, бригады. Серии для обследования выбираются механическим или собственно-случайным способом, а внутри серии производится сплошное обследование единиц. Поэтому средняя ошибка выборки зависит только от межгрупповой (межсерийной) дисперсии, которая вычисляется по формуле:
где r - число отобранных серий;
Средняя і-той серии.
Средняя ошибка серийной выборки рассчитывается:
при повторном отборе
при бесповторном отборе
где R - общее число серий.
Комбинированный отбор представляет собой сочетание рассмотренных способов отбора.
Средняя ошибка выборки при любом способе отбора зависит главным образом от абсолютной численности выборки и в меньшей степени - от процента выборки. Предположим, что проводится 225 наблюдений в первом случае из генеральной совокупности в 4500 единиц и во втором - в 225000 единиц. Дисперсии в обоих случаях равны 25. Тогда в первом случае при 5 %-ном отборе ошибка выборки составит:
Во втором случае при 0,1 %-ном отборе она будет равна:
Таким образом, при уменьшении процента выборки в 50 раз, ошибка выборки увеличилась незначительно, так как численность выборки не изменилась.
Предположим, что численность выборки увеличили до 625 наблюдений. В этом случае ошибка выборки равна:
Увеличение выборки в 2,8 раза при одной и той же численности генеральной совокупности снижает размеры ошибки выборки более чем в 1,6 раза.
Между показателями выборочной совокупности и искомыми показателями (параметрами) генеральной совокупности, как правило, существуют некоторые разногласия, которые называют ошибками выборки. Общая ошибка выборочной характеристики состоит из ошибок двух родов: ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации свойственны любому статистическому наблюдению и появление их может быть вызвано невнимательностью регистратора, неточностью подсчетов, несовершенством измерительных приборов и т.д.
Ошибки репрезентативности присущи только выборочному наблюдению и обусловлены самой его природой поскольку как бы тщательно и правильно не проводился отбор единиц средние и относительные показатели выборочной совокупности всегда будут в какой-то степени отличаться от соответствующих показателей генеральной совокупности.
Различают систематические и случайные ошибки репрезентативности. Систематические ошибки репрезентативности - это неточности, которые возникают вследствие несоблюдения условий отбора единиц в выборочную совокупность, не предоставление равной возможности каждой единице генеральной совокупности попасть в выборку. Случайные ошибки репрезентативности - это погрешности, которые возникают вследствие того, что выборочная совокупность точно не воспроизводит характеристики генеральной совокупности (среднее, долю, дисперсию и др.) в силу несплошного характера обследования.
При соблюдении принципа случайного отбора размер ошибки выборки прежде всего зависит от численности выборки. Чем больше численность выборки при прочих равных условиях, тем меньше величина ошибки выборки. При большой численности выборки отчетливее проявляется действие закона больших чисел, согласно которому: с вероятностью, сколь угодно близкой к единице, можно утверждать, что при достаточно большом объеме выборки и ограниченной дисперсии выборочные характеристики (средняя доля) будут сколь угодно мало отличаться от соответствующих генеральных характеристик.
Размеры ошибки выборки также непосредственно связаны со степенью варьирования изучаемого признака, а степень варьирования, как отмечалось выше, в статистике характеризуется размером дисперсии (рассеяния): чем меньше дисперсия, тем меньше ошибка выборки, тем более надежные статистические выводы. Поэтому на практике дисперсию отождествляют с ошибкой выборки.
Поскольку параметр генеральной совокупности есть искомая величина и он неизвестен, нужно ориентироваться не на конкретную ошибку, а среднюю из всех возможных выборок.
Если из генеральной совокупности отобрать несколько выборочных совокупностей, то каждая из полученных выборок даст разное значение конкретной ошибки.
Средняя квадратическая величина /и исчисленная из всех возможных значений конкретных ошибок (;) составит:
где *и - выборочные средние; х - генеральная средняя;)] - численность выборок по величине є1 = ~си - х.
Среднее квадратическое отклонение выборочных средних от генеральной средней называют средней ошибкой выборки.
Зависимость величины ошибки выборки от ее численности и от степени варьирования признака находит выражение в формуле средней ошибки выборки /и.
Квадрат средней ошибки (дисперсия выборочных средних) прямо пропорционален дисперсии Сто и обратно пропорционален численности выборки п:
где - дисперсия признака в генеральной совокупности.
Отсюда среднюю ошибку в общем виде определяют по формуле:
Итак, определив по выборке среднее квадратичное отклонение, можно установить значение средней ошибки выборки, величина которой, как следует из формулы, тем больше, чем больше вариация случайной величины и тем меньше, чем больше численность выборки.
Поэтому по мере роста объема выборки размер средней ошибки уменьшается. Если, например, нужно уменьшить среднюю ошибку выборки в два раза, то численность выборки следует увеличить в четыре раза, если надо уменьшить ошибку выборки в три раза, то объем выборки следует увеличить в девять раз и т. д.
В практических расчетах применяются две формулы средней ошибки выборки для средней и для доли.
При выборочном изучении средних показателей формула средней ошибки такая:
При изучении относительных показателей (частных признаков) формула средней ошибки имеет вид:
где г - доля признака в генеральной совокупности.
Применение приведенных формул средней ошибки предполагает, что известны генеральная дисперсия и генеральная доля. Однако в действительности эти показатели неизвестны и вычислить их невозможно из-за отсутствия данных относительно генеральной совокупности. Поэтому возникает потребность замены генеральной дисперсии и генеральной доли другими, близкими к ним, величинами.
В математической статистике доказано, что такими величинами могут быть выборочная дисперсия(ст) и выборочная доля (со).
С учетом сказанного формулы средней ошибки могут быть записаны так:
![]()
Эти формулы дают возможность определить среднюю ошибку при повторной выборке. Применения простой случайной повторной выборки в практике является ограниченным. Прежде всего практически нецелесообразно, а иногда невозможно повторное обследование тех же единиц. Применение бесповторного отбора вместо повторного диктуется также требованием повышения степени точности и надежности выборки. Поэтому на практике чаще используют способ бесповторного случайного отбора. По этому способу отбора единица совокупности, отобранная в выборку, в дальнейшем отборе не участвует. Единицы отбирают из генеральной совокупности, уменьшенной на количество ранее отобранных единиц. Поэтому в связи с изменением численности генеральной совокупности после каждого отбора и вероятности отбора для единиц, что остались, в формулы средней ошибки выборки вводится поправочный множитель
где N - численность генеральной совокупности; п - численность выборки. При достаточно большом значении N можно единицей в знаменателе пренебречь. Тогда
![]()
Следовательно, формулы средней ошибки выборки для бесповторного отбора для средней и для доли соответственно имеют вид:
Поскольку п всегда меньше М, то дополнительный множитель всегда меньше единицы. Следовательно, абсолютное значение ошибки выборки при бесповторном отборе всегда будет меньше, чем при повторном.
Если численность выборки достаточно велика, то величина 1 ^ близка к единице, а потому ею можно пренебречь. Тогда среднюю ошибку случайного бесповторного отбора определяют по формуле собственно-случайной повторной выборки.
Рассчитаем для нашего примера среднюю ошибку для урожайности и доли участков с урожайностью 25 ц/га и более.
Средняя ошибка выборки
а) средней урожайности ячменя

Средняя урожайность ячменя в генеральной совокупности х -Г^ = 25,1 ± 0,12 ц/га, то есть находится в пределах от 24,98 до 25,22 ц/га.
Доля участков с урожайностью 25 ц/га и более в генеральной совокупности р
Т-^Г = 0,80 ± 0,07, т.е. находится в пределах от 73 до 87%.
Средняя ошибка выборки показывает возможные отклонения характеристик выборочной совокупности от характеристик генеральной совокупности. Вместе с тем при проведении выборочного наблюдения перед исследователями часто стоит задача расчета не только средней ошибки, но и определение предельной возможной ошибки выборки. Зная среднюю ошибку, можно определить границы, за которые не выйдет величина ошибки выборки. Однако утверждать, что эти отклонения не превысят заданной величины, можно не с абсолютной достоверностью, а лишь с определенной степенью вероятности. Уровень вероятности, что принимается при определении возможных пределов, в которых содержатся значения параметров генеральной совокупности, называется доверительным уровнем вероятности.
Доверительная вероятность - это довольно высокая и, такая, что практически считается осуществленной в каждом конкретном случае, вероятность, что гарантирует получение надежных статистических выводов. Обозначим ее через Г а вероятность превысить этот уровень - а. Итак, а =1 - Р Вероятность а называют уровнем значимости (существенности), который характеризует относительное число ошибочных выводов в общем числе выводов и определяется как разница между единицей и доверительной вероятностью, что принимается.
Уровень доверительной вероятности устанавливает исследователь исходя из степени ответственности и характера задач, которые решаются. В статистических исследованиях в экономике чаще всего принимается уровень доверительной вероятности Г = 0,95; Р = 0,99 (соответственно уровень значимости а = 0,05; а = 0,01) реже Г = 0,999. Например, доверительная вероятность Г = 0,99 означает, что ошибка оценки в 99 случаях из 100 не превысит установленной величины и только в одном случае из 100 может достичь вычисленного значения, или превысить его.
Ошибка выборки, исчисленная с заданной степенью надежной вероятности, называется предельной ошибкой выборки Ер.
Рассмотрим, как устанавливается величина возможной предельной ошибки выборки. Величина ер связана с нормированным отклонением и, которое определяется как отношение предельной ошибки выборки ер к средней ошибки и:
Для удобства расчетов отклонения случайной величины от ее среднего значения обычно выражают в единицах среднего квадратического отклонения. Выражение
называют нормированным отклонением. в В статистической литературе и называют коэффициентом доверия, или коэффициентом кратности средней ошибки выборки.
Так, нормированное отклонение выборочной средней можно определить по формуле:

и _є_р_
Из выражения 1 можно найти возможную предельную ошибку выборки
ер = и/л.
Подставив вместо г. в ее значение, приведем формулы предельных ошибок выборки для средней и для доли при бесповторном случайном отборе:
Следовательно, предельная ошибка выборки зависит от величины средней ошибки и нормированного отклонения и равна ± кратному числу средних ошибок выборки.
Средняя и предельная ошибки выборки - именованные величины и выражаются в тех же единицах, что и средняя арифметическая и среднее квадратическое отклонения.
Нормированное отклонение функционально связано с вероятностью. Для нахождения значений и составлены специальные таблицы (доб.2), по которым можно найти значение и при заданном уровне доверительной вероятности и значения вероятности при известном и.
Приведем значения и и соответствующие им вероятности для выборок с численностью п > 30, что чаще всего используется в практических расчетах:
Следовательно, при и = 1 вероятность отклонения выборочных характеристик от генеральных на величину однократной средней ошибки выборки равна 0,6827. Это означает, что в среднем с каждой 1000 выборок 683 дадут обобщенные характеристики, которые будут отличаться от генеральных обобщенных характеристик не более, чем на величину однократной средней ошибки. При и = 2 вероятность равна 0,9545. в Это означает, что с каждого 1000 выборок 954 дадут обобщенные характеристики, которые будут отличаться от генеральных обобщенных характеристик не более чем на двукратную среднюю ошибку выборки и т.д.
Однако в связи с тем, что, как правило, проводится только одна выборка, то мы говорим, что, например, с вероятностью 0,9545 можно гарантировать, что размеры предельной ошибки не превысят двукратную среднюю ошибку выборки.
Математически доказано, что отношение ошибки выборки к средней ошибки, как правило, не превышает ± 3д при достаточно большой численности п, несмотря на то, что ошибка выборки может приобретать любые значения. Другими словами можно сказать, что при достаточно высокой вероятности суждения (Р = 0,9973) предельная ошибка выборки, как правило, не превышает трех средних ошибок выборки. Поэтому величину Ер = 3д можно принять за предел возможной ошибки выборки.
Определим для нашего примера предельную ошибку выборки для средней урожайности и доли участков с урожайностью 25 ц/га и более. Доверительный уровень вероятности примем равным Р = 0,9545. в По таблице (прил .2) найдем значения и = 2. Средние ошибки выборки для урожайности и доли участков с урожайностью 25 ц/га и больше были найдены ранее и соответственно составляли: Ц~ = ±0,12 ц/га; МР = ± 0,07.
Предельная ошибка средней урожайности ячменя:
Итак, разница между выборочной средней урожайностью и генеральной средней будет не больше 0,24 ц/га. Пределы средней урожайности в генеральной совокупности: х = х ±есть~ = 25,1 + 0,24, то есть от 24,86 до 25,34 ц/га.
Предельная ошибка доли участков с урожайностью 25 ц/га и более:
![]()
Следовательно, предельная ошибка в определении доли участков с урожайностью 25 ц/га и больше не превысит 14%, то есть удельный вес участков с указанной урожайностью в генеральной совокупности находится в пределах: г = а> ± ер = 0,80 ± 0,14, то есть от 66 до 94%.
 Зачем эта презентация? Во-первых, «средняя квадратическая / стандартная ошибка выборки» – длинное и сложное название, которое часто обрубают в задачах до «средней» или «стандартной» ошибки. То, что это одно и то же, в свое время было для меня настоящим открытием. Эта пресловутая ошибка бывает разная и записывается всегда по-разному, что здорово путает. Оказывается, эта штука много где попадается, но постоянно меняет обличья. Из-за этого мы зубрим целую кучу формул, когда можно обойтись однойдвумя.
Зачем эта презентация? Во-первых, «средняя квадратическая / стандартная ошибка выборки» – длинное и сложное название, которое часто обрубают в задачах до «средней» или «стандартной» ошибки. То, что это одно и то же, в свое время было для меня настоящим открытием. Эта пресловутая ошибка бывает разная и записывается всегда по-разному, что здорово путает. Оказывается, эта штука много где попадается, но постоянно меняет обличья. Из-за этого мы зубрим целую кучу формул, когда можно обойтись однойдвумя.

 Как ее обозначают? Как только не измывались над несчастной! Это варианты написания стандартной ошибки для средней в лекциях и учебниках. Над ошибкой доли издевались точно так же, или вообще забыли о ее существовании и записывали сразу формулой, что здорово путает несчастных студентов. Здесь я обозначу ее через «ε» , потому что это, хвала Богам, редкая буква, и ее не перепутать ни с моментом, ни с выборочным СКО.
Как ее обозначают? Как только не измывались над несчастной! Это варианты написания стандартной ошибки для средней в лекциях и учебниках. Над ошибкой доли издевались точно так же, или вообще забыли о ее существовании и записывали сразу формулой, что здорово путает несчастных студентов. Здесь я обозначу ее через «ε» , потому что это, хвала Богам, редкая буква, и ее не перепутать ни с моментом, ни с выборочным СКО.
 Собственно, формула (корень из дисперсии на число элементов в выборке или СКО разделить на корень из объема выборки) Это основная формула, фундамент, основа основ. Достаточно выучить только её, а дальше просто поработать головой! Как? Читай дальше!
Собственно, формула (корень из дисперсии на число элементов в выборке или СКО разделить на корень из объема выборки) Это основная формула, фундамент, основа основ. Достаточно выучить только её, а дальше просто поработать головой! Как? Читай дальше!
 Разновидности и откуда они взялись 1. Для доли. У доли дисперсия считается необычно. Если долю изучаемого признака взять за p, а долю «всего остального» - за q, то дисперсия равна p*q или p*(1 p). Отсюда взялась формула:
Разновидности и откуда они взялись 1. Для доли. У доли дисперсия считается необычно. Если долю изучаемого признака взять за p, а долю «всего остального» - за q, то дисперсия равна p*q или p*(1 p). Отсюда взялась формула:
 Разновидности и откуда они взялись (2) 2. Где взять генеральное СКО? σ – это, вообще-то, генеральное СКО, которое вам в задаче фиг дадут. Есть выход – выборочная дисперсия S 2 , которая, как всем известно, смещена. Поэтому оцениваем генеральную так: (чтобы и не думала смещаться), и подставляем. А можно сразу так: Но есть такая фишка. Если n>30, разница между S и σ крайне мала ©, поэтому можно схитрить и написать проще:
Разновидности и откуда они взялись (2) 2. Где взять генеральное СКО? σ – это, вообще-то, генеральное СКО, которое вам в задаче фиг дадут. Есть выход – выборочная дисперсия S 2 , которая, как всем известно, смещена. Поэтому оцениваем генеральную так: (чтобы и не думала смещаться), и подставляем. А можно сразу так: Но есть такая фишка. Если n>30, разница между S и σ крайне мала ©, поэтому можно схитрить и написать проще:
 Разновидности и откуда они взялись (3) «Откуда взялись еще какие-то скобки и энки? ? ? » Есть 2 метода формирования выборки, помним? – повторный и бесповторный. Так вот, все предыдущие формулы годятся для повторной выборки или когда выборка n по отношению к генеральной совокупности N настолько мала, что отношением n/N можно пренебречь. В случае, когда прям принципиально, что выборка бесповторная, или когда в задаче открытым текстом говорится, сколько единиц в генеральной совокупности, обязательно использовать.
Разновидности и откуда они взялись (3) «Откуда взялись еще какие-то скобки и энки? ? ? » Есть 2 метода формирования выборки, помним? – повторный и бесповторный. Так вот, все предыдущие формулы годятся для повторной выборки или когда выборка n по отношению к генеральной совокупности N настолько мала, что отношением n/N можно пренебречь. В случае, когда прям принципиально, что выборка бесповторная, или когда в задаче открытым текстом говорится, сколько единиц в генеральной совокупности, обязательно использовать.
Формула доверительной вероятности при оценке генеральной средней. Средняя квадратическая ошибка повторной и бесповторной выборок и построение доверительного интервала для генеральной средней.
Формула доверительной вероятности при оценке генераль ной доли признака. Средняя квадратическая ошибка повторной и бесповторной выборок и построение доверительного интервала для генеральной доли признака.
Построение доверительного интервала для гeнеральной средней и гeнеральной доли по большим выборкам . Для построения доверительных интервалов для параметров генеральных совокупностей м.б. реализованы 2 подхода, основанных на знании точного (при данном объеме выборки n) или асимптотического (при n → ∞) распределения выборочных характеристик (или некоторых функций от них). Первый подход реализован далее при построении интервальных оценок параметров для малых выборок. В данном параграфе рассматривается второй подход, применимый для больших выборок (порядка сотен наблюдений).
Теорема . Вер-ть того, что отклонение выборочной средней (или доли) от генеральной средней (или доли) не превзойдет число Δ > 0 (по абсолютной величине), равна:
|
Где
|
Где
|

 ,
, .
.Ф(t) - функция (интеграл вероятностей) Лапласа.
Формулы получили название формул доверительной вер-ти для средней и доли .
Среднее квадратическое
отклонение выборочной средней
 и выборочной доли
и выборочной доли собственно-случайной выборки называетсясредней
квадратической (стандартной) ошибкой
выборки (для бесповторной выборки
обозначаем соответственно
собственно-случайной выборки называетсясредней
квадратической (стандартной) ошибкой
выборки (для бесповторной выборки
обозначаем соответственно
 и
и ).
).
Следствие 1 . При заданной доверительной вер-ти γ предельная ошибка выборки равна t-кратной величине средней квадратической ошибки, где Ф(t) = γ, т.е.
 ,
,
 .
.
Следствие 2 . Интервальные оценки (доверительные интервалы) для генеральной средней и генеральной доли могут быть найдены по формулам:
 ,
,
 .
.

Определение необходимого объема повторной и бесповторной выборок при оценке генеральной средней и доли.
Для проведения выборочного наблюдения весьма важно правильно установить объем выборки n, к-ый в значительной степени определяет необходимые при этом временные, трудовые и стоимостные затраты для определения n необходимо задать надежность (доверительную вер-ть) оценки γ и точность (предельную ошибку выборки) Δ.

Если найден объем повторной выборки n, то объем соответствующей бесповторной выборки n" можно определить по формуле:
 .
.
Т.к.
 ,
то при одних и тех же точности и надежности
оценок объем бесповторной выборки n"
всегда меньше объема повторной выборки
n.
,
то при одних и тех же точности и надежности
оценок объем бесповторной выборки n"
всегда меньше объема повторной выборки
n.
Статистическая гипотеза и статистический критерий. Ошибки 1-го и 2-го рода. Уровень значимости и мощность критерия. Принцип практической уверенности.
Определение . Статистической гипотезой называется любое предположение о виде или параметрах неизвестного закона распределения.
Различают простую и сложную статистические гипотезы . Простая гипотеза , в отличие от сложной, полностью определяет теоретическую функцию распределения СВ.
Проверяемую гипотезу обычно называют нулевой (или основной ) и обозначают Н 0 . Наряду с нулевой гипотезой рассматривают альтернативную , или конкурирующую , гипотезу H 1 , являющуюся логическим отрицанием Н 0 . Нулевая и альтернативная гипотезы представляют собой 2 возможности выбора, осуществляемого в задачах проверки статистических гипотез.
Суть проверки
статистической гипотезы заключается
в том, что используется специально
составленная выборочная характеристика
(статистика)
 ,
полученная по выборке
,
полученная по выборке ,
точное или приближенное распределение
которой известно.
,
точное или приближенное распределение
которой известно.
Затем по этому
выборочному распределению определяется
критическое значение
 - такое, что если гипотеза Н 0
верна, то вер-ть
- такое, что если гипотеза Н 0
верна, то вер-ть
 мала; так что в соответствии с принципом
практической уверенности в условиях
данного исследования событие
мала; так что в соответствии с принципом
практической уверенности в условиях
данного исследования событие можно (с некоторым риском) считать
практически невозможным. Поэтому, если
в данном конкретном случае обнаруживается
отклонение
можно (с некоторым риском) считать
практически невозможным. Поэтому, если
в данном конкретном случае обнаруживается
отклонение ,
то гипотеза Н 0
отвергается, в то время как появление
значения
,
то гипотеза Н 0
отвергается, в то время как появление
значения
 ,
считается совместимым с гипотезой Н 0 ,
которая тогда принимается (точнее, не
отвергается). Правило, по которому
гипотеза Н 0
отвергается или принимается, называется
статистическим
критерием
или статистическим
тестом
.
,
считается совместимым с гипотезой Н 0 ,
которая тогда принимается (точнее, не
отвергается). Правило, по которому
гипотеза Н 0
отвергается или принимается, называется
статистическим
критерием
или статистическим
тестом
.
Принцип практической уверенности:
Если вер-ть события А в данном испытании очень мала, то при однократном выполнении испытания можно быть уверенным в том, что событие А не произойдет, и в практической д-ти вести себя так, как будто событие А вообще невозможно.
Т.о., множество
возможных значений статистики - критерия
(критической статистики)
 разбивается на 2 непересекающихся
подмножества:критическую
область
(область отклонения гипотезы) W
и область
допустимых значений
(область принятия гипотезы)
разбивается на 2 непересекающихся
подмножества:критическую
область
(область отклонения гипотезы) W
и область
допустимых значений
(область принятия гипотезы)
 .
Если фактически наблюдаемое значение
статистики критерия
.
Если фактически наблюдаемое значение
статистики критерия попадает в критическую область W, то
гипотезу Н 0
отвергают. При этом возможны четыре
случая:
попадает в критическую область W, то
гипотезу Н 0
отвергают. При этом возможны четыре
случая:

Определение . Вероятность α допустить ошибку l-го рода, т.е. отвергнуть гипотезу Н 0 , когда она верна, называется уровнем значимости , или размером критерия .
Вероятность допустить ошибку 2-го рода, т.е. принять гипотезу Н 0 , когда она неверна, обычно обозначают β.
Определение . Вероятность (1-β) не допустить ошибку 2-го рода, т.е. отвергнуть гипотезу Н 0 , когда она неверна, называется мощностью (или функцией мощности ) критерия .
Следует предпочесть ту критическую область, при которой мощность критерия будет наибольшей.







