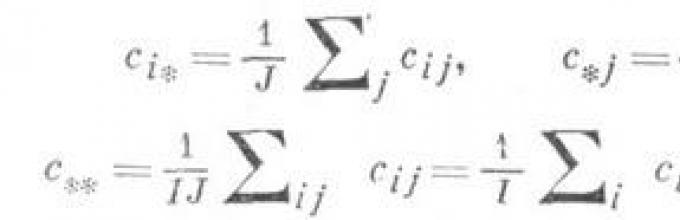
ДИСПЕРСИОННЫЙ АНАЛИЗ
в математической статистике - статистический метод, предназначенный для выявления влияния отдельных факторов на результат эксперимента, а также для последующего планирования аналогичных экспериментов. Первоначально Д. а. был предложен Р. Фишером для обработки результатов агрономич. опытов по выявлению условий, при к-рых испытываемый сорт сельскохозяйственной культуры дает максимальный урожай. Современные приложения Д. а. охватывают широкий задач экономики, социологии, биологии и техники и трактуются обычно в терминах статистич. теории выявления систематич. различий между результатами непосредственных измерений, выполненных при тех пли иных меняющихся условиях.
Если значения неизвестных постоянных a 1 , ... , a I могут быть измерены с помощью различных методов или измерительных средств М 1 ,. .., M J , и в каждом случае систематич. ошибка b ij может, вообще говоря, зависеть как от выбранного метода Mj, так и от неизвестного измеряемого значения а i , то результаты таких измерений представляют собой суммы вида
где К- количество независимых измерений неизвестной величины а i методом M j , a у ijk - случайная ошибка k-го измерения величины а i методом M j (предполагается, что все y ijk - независимые одинаково распределенные случайные величины, имеющие нулевое математич. ожидание: Е у ijk =0). Такая линейная наз. двухфакторной схемой Д. а.; первый - истинное значение измеряемой величины, второй - метод измерения, причем в данном случае для каждой возможной комбинации значений первого и второго факторов осуществляется одинаковое количество Кнезависимых измерений (это допущение для целей Д. а. не является существенным и введено здесь лишь ради простоты изложения).
Примером подобной ситуации могут служить спортивные соревнования I спортсменов, мастерство к-рых оценивается J судьями, причем каждый участник соревнований выступает Краз (имеет К"попыток"). В этом случае а i - истинное значение показателя мастерства спортсмена с номером i, b ij - систематич. ошибка, вносимая в оценку мастерства i -го спортсмена судьей с номером j, x ijk - оценка, выставленная j -м судьей г-му спортсмену после выполнений последним k-й попытки, а y ijk - соответствующая случайная . Подобная типична для так наз. субъективной экспертизы качества нескольких объектов, осуществляемой группой независимых экспертов. Другой пример - статистич. исследование урожайности сельскохозяйственной культуры в зависимости от одного из J сортов почвы и J методов ее обработки, причем для каждого сорта г почвы и каждого метода обработки с номером J осуществляется kнезависимых экспериментов (в этом примере b ij - истинное значение урожайности для г-го сорта почвы при j-м способе обработки, x ijk - соответствующая экспериментально наблюдаемая урожайность в k-м опыте, а y ijk - ее случайная ошибка, возникающая из-за тех или иных случайных причин; что же касается величин а i , то в агрономич. опытах их разумно считать равными нулю).
Положим c ij =a i +b ij , и пусть с i *, с *j и с ** - результаты осреднений с ij по соответствующим индексам, т. е.

Пусть, кроме того, a=c ** , b i = с i* - с ** , g j = с *j -с ** и d ij = с ij - с i* - с *j +c ** . Идея Д. а. основана на очевидном тождестве
Если символом (c ij
)обозначить размерности IJ
, получаемый из матрицы ||с ij
|| порядка IXJ с помощью какого-либо заранее фиксированного способа упорядочивания ее элементов, то (1) можно записать в виде равенства где все векторы имеют IJ
, причем a ij
=a, b ij
=b i
, g ij
=g j
. Так как четыре вектора в правой части (2) ортогональны, то a ij
=a - наилучшее приближение функции c ij
от аргументов i и j
постоянной величиной [в смысле минимальности суммы квадратов отклонений ![]() ]. В том же смысле a ij
+b ij
=a+b i
- наилучшее c ij
функцией, зависящей лишь от i, a ij
+g ij
=a+g j
- наилучшее приближение c ij
функцией, зависящей лишь от j, a a ij
+b ij
+g ij
=a+b i
+g j
- наилучшее приближение c ij
суммой функций, из к-рых одна (напр., a+b i
) зависит лишь от г, а другая - лишь от j. Этот факт, установленный Р. Фишером (см. ) в 1918, позднее послужил основой теории квадратичных приближений функций.
]. В том же смысле a ij
+b ij
=a+b i
- наилучшее c ij
функцией, зависящей лишь от i, a ij
+g ij
=a+g j
- наилучшее приближение c ij
функцией, зависящей лишь от j, a a ij
+b ij
+g ij
=a+b i
+g j
- наилучшее приближение c ij
суммой функций, из к-рых одна (напр., a+b i
) зависит лишь от г, а другая - лишь от j. Этот факт, установленный Р. Фишером (см. ) в 1918, позднее послужил основой теории квадратичных приближений функций.
В примере, связанном со спортивными соревнованиями, d ij выражает "взаимодействие" г-го спортсмена и j-го судьи (положительное значение б/у означает "подсуживание", т. с. систематич. завышение /-м судьей оценки мастерства i-го спортсмена, а отрицательное значение б/у означает "засуживание", т. е. систематич. снижение оценки). Равенство всех б/у нулю - необходимое требование, к-рое надлежит предъявлять к работе группы экспертов. В случае же агрономич. опытов такое равенство рассматривается как гипотеза, подлежащая проверке по результатам экспериментов, поскольку основная цель здесь - отыскание таких значений i и j, при к-рых функция (1) достигает максимального значения. Если эта гипотеза верна, то
и значит, выявление наилучших "почвы" и "обработки" может быть осуществлено раздельно, что приводит к существенному сокращению числа экспериментов (напр., можно при каком-либо одном способе обработки испытать все Iсортов "почвы" и определить наилучший сорт, а затем на этом сорте опробовать все J способов "обработки" и найти наилучший способ; общее количество экспериментов с повторениями будет равно (I+J) К). Если же гипотеза {все d ij =0} неверна, то для определения max c ij необходим описанный выше "полный план", требующий при Кповторениях IJК экспериментов.
В ситуации спортивных соревнований функция g ij =g j может трактоваться как систематич. ошибка, допускаемая j-м судьей по отношению ко всем спортсменам. В конечном счете g j - характеристика "строгости" или "либеральности" j-го судьи. В идеале хотелось бы, чтобы все g j были нулевыми, но в реальных условиях приходится мириться с наличием ненулевых значений g j и учитывать это обстоятельство при подведении итогов экспертизы (напр., за основу сравнения мастерства спортсменов можно принять не последовательности истинных значений a+b 1 +g j , ..., a+b I +g j , a лишь результаты упорядочиваний этих чисел по их величине, поскольку при всех j=1, . . . , J такие упорядочивания будут одинаковыми). Наконец, сумма двух оставшихся функций a ij +b ij =a+b i зависит лишь от iи поэтому может быть использована для характеризации мастерства г-го спортсмена. Однако здесь нужно помнить, что Поэтому упорядочивание всех спортсменов по значениям a+b i (или по a+ + b i +g j при каждом фиксированном j) может не совпадать с упорядочиванием по значениям a i . При практической обработке экспертных оценок этим обстоятельством приходится пренебрегать, так как Упомянутый полный план экспериментов не позволяет оценивать отдельно a i и b i* . Таким образом, a+b i =a i + b i* характеризует не только мастерство i -го спортсмена, но и в той или иной мере экспертов к этому мастерству. Поэтому, напр., результаты субъективных экспертных оценок, осуществленных в разное время (в частности, на нескольких Олимпийских играх), едва ли можно считать сопоставимыми. В случае же агрономич. опытов подобные трудности не возникают, поскольку все a i =0 и значит, a+b i =b i* .
Истинные значения функций a, b i , g i и d ij неизвестны и выражаются в терминах неизвестных функций c ij . Поэтому первый этап Д. а. заключается в отыскании статистич. оценок для c ij по результатам наблюдений x ijk .Несмещенная и имеющая минимальную дисперсию для c ij выражается формулой
![]()
Так как a, b i
, g j
и d ij
- линейные функции от элементов матрицы ||c ij
||, то несмещенные линейные оценки для этих функций, имеющие минимальную дисперсию, получаются в результате замены аргументов c ij
соответствующими оценками, c ij ,
т. е. причем случайные векторы ![]() и определенные так же, как введенные выше (a ij
),
(b ij
), (g ij
).
и (d ij
), обладают свойством ортогональности, и значит, они представляют собой некоррелированные случайные векторы (иными словами, любые две компоненты, принадлежащие разным векторам, имеют нулевой корреляции). Кроме того, любая вида
и определенные так же, как введенные выше (a ij
),
(b ij
), (g ij
).
и (d ij
), обладают свойством ортогональности, и значит, они представляют собой некоррелированные случайные векторы (иными словами, любые две компоненты, принадлежащие разным векторам, имеют нулевой корреляции). Кроме того, любая вида
некоррелирована с любой из компонент этих
четырех векторов. Рассмотрим пять совокупностей случайных величин {x ijk }, {x ijk
-x ij* },
![]() Так как
Так как

то дисперсии эмпирич. распределений, соответствующих указанным совокупностям, выражаются формулами

Эти эмпирич. дисперсии представляют собой суммы квадратов случайных величин, любые две из к-рых некоррелированы, если только они принадлежат разным суммам; при этом относительно всех y ijk справедливо тождество
объясняющее происхождение термина "Д. а."" Пусть и пусть

в таком случае
где s 2 - дисперсия случайных ошибок y ijk .
На основе этих формул и строится второй этап Д. а., посвященный выявлению влияния первого и второго факторов на результаты эксперимента (в агрономич. опытах первый фактор - сорт "почвы", второй - способ "обработки"). Напр., если требуется проверить гипотезу отсутствия "взаимодействия" факторов, к-рая выражается равенствомто разумно вычислить дисперсионное отношение s 2 3 /s 2 0 = F 3 . Если это отношение значимо отличается от единицы, то проверяемая гипотеза отвергается. Точно так же для проверки гипотезы полезно отношение s 2 2 /s 2 0 = F 2 , к-рое надлежит также сравнить с единицей; если при этом известно, чтото вместо F 2 целесообразно сравнить с единицей отношение

Аналогичным образом можно построить статистику, позволяющую дать заключение о справедливости или ложности гипотезы
Точный смысл понятия значимого отличия указанных отношений от единицы может быть определен лишь с учетом закона распределения случайных ошибок y ijk .
В Д. а. наиболее обстоятельно изучена ситуация, в к-рой все y ijk
распределены нормально. В этом случае - независимые случайные векторы, а ![]() - независимые случайные величины, причем
- независимые случайные величины, причем 
отношения подчиняются нецентральным распределениям хи-квадрат с f m степенями свободы и параметрами нецентральности l т, m =0, 1, 2, 3, где

Если параметр нецентральности равен нулю, то нецентральное хи-квадрат совпадает с обычным распределением хи-квадрат. Поэтому в случае справедливости гипотезы l 3 =0 отношение подчиняется F-распре делению (распределению дисперсионного отношения) с параметрами f 3 и f 0 . Пусть х- такое число, для к-рого события {F 3 >x} равна заданному значению е, называемому уровнем значимости (таблицы функции х= х (e; f 3 , f 0) имеются в большинстве пособий по математич. статистике). Критерием для проверки гипотезы l 3 =0 служит правило, согласно к-рому эта гипотеза отвергается, если наблюдаемое значение F 3 превышает х;в противном случае гипотеза считается не противоречащей результатам наблюдений. Аналогичным образом конструируются критерии, основанные на статистиках F 2 и F* 2 .
Дальнейшие этапы Д. а. существенно зависят не только от реального содержания конкретной задачи, но также и от результатов статистич. проверки гипотез на втором этапе. Напр., в условиях агрономич. опытов справедливость гипотезы l 3 =0, как указано выше, позволяет более экономно спланировать аналогичные дальнейшие эксперименты (если помимо гипотезы l 3 =0 справедлива также и гипотеза l 2 =0, то это означает, что урожайность зависит лишь от сорта "почвы", и поэтому в дальнейших опытах можно воспользоваться схемой однофакторного Д. а.); если же гипотеза l 3 =0 отвергается, то разумно проверить, нет ли в данной задаче неучтенного третьего фактора? Если сорта "почвы" и способы ее "обработки" варьировались не в одном и том же месте, а в различных географич. зонах, то таким фактором могут быть климатич. или географич. условия, и "обработка" наблюдений потребует применения трехфакторного Д. а.
В случае экспертных оценок статистически подтвержденная справедливость гипотезы l 3 = 0 дает основание для упорядочивания сравниваемых объектов (напр., спортсменов) по значениям величин i=l, . .. , I.
Если же гипотеза l 3 =0 отвергается (в задаче о спортивных соревнованиях это означает статистич. обнаружение "взаимодействия" нек-рых спортсменов и судей), то естественно попытаться перевычнслить все результаты заново, предварительно исключив из рассмотрения x ijk с такими парами индексов (i, j ), для к-рых абсолютные значения статистич. оценок d ij превышают нек-рый заранее установленный допустимый уровень. Это означает, что из матрицы ||x ij* || вычеркиваются нек-рые элементы, и значит, план Д. а. становится неполным.
Модели современного Д. а. охватывают широкий круг реальных экспериментальных схем (напр., схемы неполных планов, со случайно или неслучайно отобранными элементами x ij* ). Соответствующие этим схемам статистич. выводы во многих случаях находятся в стадии разработки. В частности, еще (к 1978) далеки от окончательного решения те задачи, в к-рых результаты наблюдений x ijk =c ij +y ijk не являются одинаково распределенными случайными величинами; еще более трудная задача возникает в случае зависимости величин x ijk . Неизвестно проблемы выбора факторов (даже в линейном случае). Суть этой проблемы заключается в следующем: пусть с=с ( и, v )- и пусть u=u (z, w )и u=u (z, w )- какие-либо линейные функции от переменных г и w. Фиксируя значения z 1 , . .., z I и w 1 , . . ., w J , можно при каждом заданном выборе линейных функций ии u. определить c ij формулой и построить Д. а. этих величин по результатам соответствующих наблюдений x ijk . Проблема заключается в отыскании таких линейных функций u и u, к-рым соответствует минимальное значение суммы квадратов
где (предполагается, что функция с( и, v )неизвестна). В терминах Д. а. эта проблема сводится к статистич. отысканию таких факторов z=z (u, v )и w-w (u, v ), к-рым соответствует "наименьшее взаимодействие".
Лит. : Fisher R. A., Statistical methods for research workers, Edinburgh, 1925; Шеффе Г., Дисперсионный анализ, пер. с англ., М., 1963; Xальд А., Математическая с техническими приложениями, пер. с англ., М., 1956; Снедекор Д ж. У., Статистические методы в применении к исследованиям в сельском хозяйстве и биологии, пер. с англ., М., 1961.
Л. Н. Большее.
Математическая энциклопедия. - М.: Советская энциклопедия . И. М. Виноградов . 1977-1985 .
Смотреть что такое "ДИСПЕРСИОННЫЙ АНАЛИЗ" в других словарях:
Метод в математической статистике, направленный на поиск зависимостей в экспериментальных данных путём исследования значимости различий в средних значениях. В литературе также встречается обозначение ANOVA (от англ. ANalysis Of… … Википедия
- (analysis of variance) Статистический метод, основанный на разложении общей дисперсии (variance) какой либо характеристики населения на составные части, коррелирующие с другими характеристиками, и остаточную вариацию (residual variation). В… … Экономический словарь
Один из методов математической статистики, применяемый для анализа результатов наблюдений, зависящих от различных, одновременно действующих факторов, к рые не поддаются, как правило, количеств. описанию. Рассмотрим простейшую из задач Д. а. Пусть … Физическая энциклопедия
Дисперсионный анализ - раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента (физического, производственного, экономического эксперимента). Д.а. возник как средство обработки результатов… … Экономико-математический словарь
дисперсионный анализ - — дисперсионный анализ Раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента (физического, производственного,… … Справочник технического переводчика
Как было уже отмечено, дисперсионный метод тесно связан со статистическими группировками и предполагает, что изучаемая совокупность подразделена на группы по факторным признакам, влияние которых должно быть изучено.
На основе дисперсионного анализа производится:
1. оценка достоверности различий в групповых средних по одному факторному признаку или нескольким;
2. оценка достоверности взаимодействий факторов;
3. оценка частных различий между парами средних.
В основе применения дисперсионного анализа лежит закон разложения дисперсий (вариаций) признака на составляющие.
Общая вариация D о результативного признака при группировке может быть разложена на следующие составные части:
1. на межгрупповую D м связанную с группировочным признаком;
2. на остаточную (внутригрупповую) D B , не связанную с группировочным признаком.
Соотношение между этими показателями выражается следующим образом:
D о = D м + D в. (1.30)
Рассмотрим применение дисперсионного анализа на примере.
Допустим, требуется доказать, влияют ли сроки посева на урожайность пшеницы. Исходные опытные данные для дисперсионного анализа представлены в табл. 8.
Таблица 8
В данном примере N = 32, K = 4, l = 8.
Определим общую суммарную вариацию урожайности, которая представляет собой сумму квадратов отклонений индивидуальных значений признака от общей средней:
где N – число единиц совокупности; Y i – индивидуальные значения урожайности; Y o – общая средняя урожайности по всей совокупности.

Для определения межгрупповой суммарной вариации, определяющей вариацию результативного признака за счет изучаемого фактора, необходимо знать средние значения результативного признака по каждой группе. Эта суммарная вариация равна сумме квадратов отклонений групповых средних величин от общей средней величины признака, взвешенной на число единиц совокупности в каждой из групп:

Внутригрупповая суммарная вариация равна сумме квадратов отклонений индивидуальных значений признака от групповых средних по каждой группе, суммированной по всем группам совокупности.

Влияние фактора на результативный признак проявляется в соотношении между D м и D в: чем сильнее влияние фактора на величину изучаемого признака, тем больше D м и меньше D в.
Для проведения дисперсионного анализа нужно установить источники варьирования признака, объем вариации по источникам, определить число степеней свободы для каждой компоненты вариации.
Объем вариации уже установлен, теперь необходимо определить число степеней свободы вариации. Число степеней свободы – это число независимых отклонений индивидуальных значений признака от его среднего значения. Общее число степеней свободы, соответствующее общей сумме квадратов отклонений в дисперсионном анализе, разлагается по составляющим вариации. Так, общей сумме квадратов отклонений D о соответствует число степеней свободы вариации, равное N – 1 = 31. Групповой вариации D м соответствует число степеней свободы вариации, равное K – 1 = 3. Внутригрупповой остаточной вариации соответствует число степеней свободы вариации, равное N – K = 28.
Теперь, зная суммы квадратов отклонений и число степеней свободы, можно определить дисперсии для каждой составляющей. Обозначим эти дисперсии: d м – групповые и d в – внутригрупповые.

После вычисления этих дисперсий приступим к установлению значимости влияния фактора на результативный признак. Для этого находим отношение: d M /d B = F ф,
Величина F ф, называемая критерием Фишера , сравнивается с табличным, F табл. Как уже было отмечено, если F ф > F табл, то влияние фактора на результативный признак доказано. Если F ф < F табл то можно утверждать, что различие между дисперсиями находится в пределах возможных случайных колебаний и, следовательно, не доказывает с достаточной вероятностью влияние изучаемого фактора.
Теоретическая величина связана с вероятностью, и в таблице ее значение приводится при определенном уровне вероятности суждения. В приложении имеется таблица, позволяющая установить возможную величину F при вероятности суждения, наиболее часто используемой: уровень вероятности «нулевой гипотезы» – 0,05. Вместо вероятностей «нулевой гипотезы» таблица может быть названа таблицей для вероятности 0,95 существенности влияния фактора. Повышение уровня вероятности требует для сравнения более высокого значения F табл.
Величина F табл зависит также от числа степеней свободы двух сравниваемых дисперсий. Если число степеней свободы стремится к бесконечности, то F табл стремится к единице.
Таблица значений F табл построена следующим образом: в столбцах таблицы указаны степени свободы вариации для большей дисперсии, а в строках – степени свободы для меньшей (внутригрупповой) дисперсии. Величина F находится на пересечении столбца и строки соответствующих степеней свободы вариации.
Так, в нашем примере F ф = 21,3/3,8 = 5,6. Табличное же значение F табл для вероятности 0,95 и степеней свободы, соответственно равных 3 и 28, F табл = 2,95.
Значение F ф полученное в опыте, превышает теоретическое значение даже для вероятности 0,99. Следовательно, опыт с вероятностью более 0,99 доказывает влияние изучаемого фактора на урожайность, т. е. опыт можно считать надежным, доказанным, а значит, сроки посева оказывают существенное влияние на урожайность пшеницы. Оптимальным сроком посева следует считать период с 10 по 15 мая, так как именно при этом сроке посева получены наилучшие результаты урожайности.
Нами рассмотрена методика дисперсионного анализа при группировке по одному признаку и случайному распределению повторностей внутри группы. Однако часто бывает так, что опытный участок имеет какие-то различия в плодородии почвы и т. д. Поэтому может возникнуть такая ситуация, что большее число делянок одного из вариантов попадет на лучшую часть, и его показатели будут завышены, а другого варианта – на худшую часть, и результаты в этом случае, естественно, будут хуже, т. е. занижены.
Чтобы исключить варьирование, которое вызывается не относящимися к опыту причинами, надо из внутригрупповой (остаточной) дисперсии вычленить дисперсию, рассчитанную по повторностям (блокам).
Общая сумма квадратов отклонений подразделяется в этом случае уже на 3 составляющие:
D о = D м + D повт + D ост. (1.33)
Для нашего примера сумма квадратов отклонений, вызванная повторностями, будет равна:

Стало быть, собственно случайная сумма квадратов отклонений будет равна:
D ост = D в – D повт; D ост = 106 – 44 = 62.
Для остаточной дисперсии число степеней свободы будет равно 28 – 7 = 21. Результаты дисперсионного анализа представлены в табл. 9.
Таблица 9

Поскольку фактические значения F-критерия для вероятности 0,95 превышают табличные, то влияние сроков посева и повторностей на урожайность пшеницы следует считать существенным. Рассмотренный способ построения опыта, когда участок предварительно делится на блоки с относительно выровненными условиями, а проверяемые варианты распределяются внутри блока в случайном порядке, называется способом рендомизированных блоков.
С помощью анализа дисперсионным методом можно изучить влияние не только одного фактора на результат, а двух и более. Дисперсионный анализ в этом случае будет называться многофакторным дисперсионным анализом .
Двухфакторный дисперсионный анализ отличается от двух однофакторных тем, что он может ответить на следующие вопросы:
1. 1каково влияние обоих факторов вместе?
2. какова роль сочетания этих факторов?
Рассмотрим дисперсионный анализ опыта, в котором следует выявить влияние не только сроков посева, но и сортов на урожайность пшеницы (табл. 10).
Таблица 10. Данные опыта по влиянию сроков посева и сортов на урожайность пшеницы

– это сумма квадратов отклонений индивидуальных значений от общей средней.
Вариация по совместному влиянию сроков посева и сорта
– это сумма квадратов отклонений средних по подгруппам от общей средней, взвешенных на число повторностей, т. е. на 4.
Вычисление вариации по влиянию только сроков посева:

Остаточная вариация определяется как разность между общей вариацией и вариацией по совместному влиянию изучаемых факторов:
D ост = D о – D пс = 170 – 96 = 74.
Все расчеты можно оформить в виде таблицы (табл. 11).
Таблица 11. Результаты дисперсионного анализа

Результаты дисперсионного анализа показывают, что влияние изучаемых факторов, т. е. сроков посева и сорта, на урожайность пшеницы существенно, так как F-критерии фактические по каждому из факторов значительно превышают табличные, найденные для соответствующих степеней свободы, и при этом с достаточно высокой вероятностью (р = 0,99). Влияние же сочетания факторов в данном случае отсутствует, так как факторы независимы друг от друга.
Анализ влияния трех факторов на результат ведется по такому же принципу, что и для двух факторов, только в этом случае будет три дисперсии по факторам и четыре дисперсии по сочетанию факторов. С увеличением числа факторов резко увеличивается объем расчетных работ и, кроме того, становится затруднительно оформлять исходную информацию в комбинационную таблицу. Поэтому вряд ли целесообразно изучать влияние многих факторов на результат с использованием дисперсионного анализа; лучше взять меньшее их число, но выбрать наиболее существенные факторы с точки зрения экономического анализа.
Нередко исследователю приходится иметь дело с так называемыми непропорциональными дисперсионными комплексами, т. е. такими, в которых не соблюдается пропорциональность численностей вариантов.
В таких комплексах вариация суммарного действия факторов не равна сумме вариации по факторам и вариации сочетания факторов. Она отличается на величину, зависящую от степени связей между отдельными факторами, возникающих вследствие нарушения пропорциональности.
В этом случае возникают трудности при определении степени влияния каждого фактора, так как сумма частных влияний не равна суммарному влиянию.
Одним из способов приведения непропорционального комплекса к единой структуре является способ его замены пропорциональным комплексом, в котором частоты усреднены по группам. Когда такая замена произведена, задача решается по принципам пропорциональных комплексов.
Ум заключается не только в знании, но и в умении прилагать знание на деле. (Аристотель)
Дисперсионный анализ
Вводный обзор
В этом разделе мы рассмотрим основные методы, предположения и терминологию дисперсионного анализа.
Отметим, что в англоязычной литературе дисперсионный анализ обычно называется анализом вариации. Поэтому, для краткости, ниже мы иногда будем использовать термин ANOVA (An alysis o f va riation ) для обычного дисперсионного анализа и термин MANOVA для многомерного дисперсионного анализа. В этом разделе мы последовательно рассмотрим основные идеи дисперсионного анализа (ANOVA ), ковариационного анализа (ANCOVA ), многомерного дисперсионного анализа (MANOVA ) и многомерного ковариационного анализа (MANCOVA ). После краткого обсуждения достоинств анализа контрастов и апостериорных критериев рассмотрим предположения, на которых основаны методы дисперсионного анализа. Ближе к концу этого раздела поясняются преимущества многомерного подхода для анализа повторных измерений по сравнению с традиционным одномерным подходом.
Основные идеи
Цель дисперсионного анализа. Основной целью дисперсионного анализа является исследование значимости различия между средними. Глава (глава 8) содержит краткое введение в исследование статистической значимости. Если вы просто сравниваете средние в двух выборках, дисперсионный анализ даст тот же результат, что и обычный t - критерий для независимых выборок (если сравниваются две независимые группы объектов или наблюдений) или t - критерий для зависимых выборок (если сравниваются две переменные на одном и том же множестве объектов или наблюдений). Если вы не достаточно знакомы с этими критериями, рекомендуем обратиться к вводному обзору главы (глава 9).
Откуда произошло название Дисперсионный анализ ? Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними, мы на самом деле анализируем дисперсии.
Разбиение суммы квадратов
Для выборки объема n выборочная дисперсия вычисляется как сумма квадратов отклонений от выборочного среднего, деленная на n-1 (объем выборки минус единица). Таким образом, при фиксированном объеме выборки n дисперсия есть функция суммы квадратов (отклонений), обозначаемая, для краткости, SS (от английского Sum of Squares – Сумма Квадратов). В основе дисперсионного анализа лежит разделение (или разбиение) дисперсии на части. Рассмотрим следующий набор данных:
Средние двух групп существенно различны (2 и 6 соответственно). Сумма квадратов отклонений внутри каждой группы равна 2. Складывая их, получаем 4. Если теперь повторить эти вычисления без учета групповой принадлежности, то есть, если вычислить SS исходя из общего среднего этих двух выборок, то получим 28. Иными словами, дисперсия (сумма квадратов), основанная на внутригрупповой изменчивости, приводит к гораздо меньшим значениям, чем при вычислении на основе общей изменчивости (относительно общего среднего). Причина этого, очевидно, заключается в существенной разнице между средними значениями, и это различие между средними и объясняет существующее различии между суммами квадратов. В самом деле, если использовать для анализа приведенных данных модуль Дисперсионный анализ , будут получены следующие результаты:
Как видно из таблицы, общая сумма квадратов SS =28 разбита на сумму квадратов, обусловленную внутригрупповой изменчивостью (2+2=4 ; см. вторую строку таблицы) и сумму квадратов, обусловленную различием средних значений. (28-(2+2)=24; см первую строку таблицы).
SS ошибок и SS эффекта. Внутригрупповая изменчивость (SS ) обычно называется дисперсией ошибки. Это означает, что обычно при проведении эксперимента она не может быть предсказана или объяснена. С другой стороны, SS эффекта (или межгрупповую изменчивость) можно объяснить различием между средними значениями в изучаемых группах. Иными словами, принадлежность к некоторой группе объясняет межгрупповую изменчивость, т.к. нам известно, что эти группы обладают разными средними значениями.
Проверка значимости. Основные идеи проверки статистической значимости обсуждаются в главе Элементарные понятия статистики (глава 8). В этой же главе объясняются причины, по которым многие критерии используют отношение объясненной и необъясненной дисперсии. Примером такого использования является сам дисперсионный анализ. Проверка значимости в дисперсионном анализе основана на сравнении дисперсии, обусловленной межгрупповым разбросом (называемой средним квадратом эффекта или MS эффект ) и дисперсии, обусловленной внутригрупповым разбросом (называемой средним квадратом ошибки или MS ошибка ). Если верна нулевая гипотеза (равенство средних в двух популяциях), то можно ожидать сравнительно небольшое различие в выборочных средних из-за случайной изменчивости. Поэтому при нулевой гипотезе внутригрупповая дисперсия будет практически совпадать с общей дисперсией, подсчитанной без учета группой принадлежности. Полученные внутригрупповые дисперсии можно сравнить с помощью F - критерия, проверяющего, действительно ли отношение дисперсий значимо больше 1. В рассмотренном выше примере F - критерий показывает, что различие между средними статистически значимо.
Основная логика дисперсионного анализа. Подводя итоги, можно сказать, что целью дисперсионного анализа является проверка статистической значимости разницы между средними (для групп или переменных). Эта проверка проводится с помощью анализа дисперсии, т.е. с помощью разбиения общей дисперсии (вариации) на части, одна из которых обусловлена случайной ошибкой (то есть внутригрупповой изменчивостью), а вторая связана с различием средних значений. Последняя компонента дисперсии затем используется для анализа статистической значимости различия между средними значениями. Если это различие значимо, нулевая гипотеза отвергается и принимается альтернативная гипотеза о существовании различия между средними.
Зависимые и независимые переменные. Переменные, значения которых определяется с помощью измерений в ходе эксперимента (например, балл, набранный при тестировании), называются зависимыми переменными. Переменные, которыми можно управлять при проведении эксперимента (например, методы обучения или другие критерии, позволяющие разделить наблюдения на группы) называются факторами или независимыми переменными. Более подробно эти понятия описаны в главе Элементарные понятия статистики (глава 8).
Многофакторный дисперсионный анализ
В рассмотренном выше простом примере вы могли бы сразу вычислить t-критерий для независимых выборок, используя соответствующую опцию модуля Основные статистики и таблицы. Полученные результаты, естественно, совпадут с результатами дисперсионного анализа. Однако дисперсионный анализ содержит гибкие и мощные технические средства, которые могут быть использованы для гораздо более сложных исследований.
Множество факторов. Мир по своей природе сложен и многомерен. Ситуации, когда некоторое явление полностью описывается одной переменной, чрезвычайно редки. Например, если мы пытаемся научиться выращивать большие помидоры, следует рассматривать факторы, связанные с генетической структурой растений, типом почвы, освещенностью, температурой и т.д. Таким образом, при проведении типичного эксперимента приходится иметь дело с большим количеством факторов. Основная причина, по которой использование дисперсионного анализа предпочтительнее повторного сравнения двух выборок при разных уровнях факторов с помощью t - критерия, заключается в том, что дисперсионный анализ более эффективен и, для малых выборок, более информативен.
Управление факторами. Предположим, что в рассмотренном выше примере анализа двух выборок мы добавим еще один фактор, например, Пол - Gender . Пусть каждая группа состоит из 3 мужчин и 3 женщин. План этого эксперимента можно представить в виде таблицы 2 на 2:
| Эксперимент. Группа 1 | Эксперимент. Группа 2 | |
|---|---|---|
| Мужчины | 2 | 6 |
| 3 | 7 | |
| 1 | 5 | |
| Среднее | 2 | 6 |
| Женщины | 4 | 8 |
| 5 | 9 | |
| 3 | 7 | |
| Среднее | 4 | 8 |
До проведения вычислений, можно заметить, что в этом примере общая дисперсия имеет, по крайней мере, три источника:
(1) случайная ошибка (внутригрупповая дисперсия),
(2) изменчивость, связанная с принадлежностью к экспериментальной группе, и
(3) изменчивость, обусловленная полом объектов наблюдения.
(Отметим, что существует еще один возможный источник изменчивости – взаимодействие факторов , который мы обсудим позднее). Что произойдет, если мы не будем включать пол –gender как фактор при проведении анализа и вычислим обычный t -критерий? Если мы будем вычислять суммы квадратов, игнорируя пол – gender (т.е., объединяя объекты разного пола в одну группу при вычислении внутригрупповой дисперсии, получив при этом сумму квадратов для каждой группы равную SS =10, и общую сумму квадратов SS = 10+10 = 20), то получим большее значение внутригрупповой дисперсии, чем при более точном анализе с дополнительным разбиением на подгруппы по полу - gender (при этом внутригрупповые средние будут равны 2, а общая внутригрупповая сумма квадратов равна SS = 2+2+2+2 = 8). Это различие связано с тем, что среднее значение для мужчин - males меньше, чем среднее значение для женщин – female , и это различие в средних значениях увеличивает суммарную внутригрупповую изменчивость, если фактор пола не учитывается. Управление дисперсией ошибки увеличивает чувствительность (мощность) критерия.
На этом примере видно еще одно преимущество дисперсионного анализа по сравнению с обычным t -критерием для двух выборок. Дисперсионный анализ позволяет изучать каждый фактор, управляя значениями остальных факторов. Это, в действительности, и является основной причиной его большей статистической мощности (для получения значимых результатов требуются меньшие объемы выборок). По этой причине дисперсионный анализ даже на небольших выборках дает статистически более значимые результаты, чем простой t - критерий.
Эффекты взаимодействия
Существует еще одно преимущество применения дисперсионного анализа по сравнению с обычным t - критерием: дисперсионный анализ позволяет обнаружить взаимодействие между факторами и, следовательно, позволяет изучать более сложные модели. Для иллюстрации рассмотрим еще один пример.
Главные эффекты, попарные (двухфакторные) взаимодействия. Предположим, что имеется две группы студентов, причем психологически студенты первой группы настроены на выполнение поставленных задач и более целеустремленны, чем студенты второй группы, состоящей из более ленивых студентов. Разобьем каждую группу случайным образом пополам и предложим одной половине в каждой группе сложное задание, а другой - легкое. После этого измерим, насколько напряженно студенты работают над этими заданиями. Средние значения для этого (вымышленного) исследования показаны в таблице:
Какой вывод можно сделать из этих результатов? Можно ли заключить, что: (1) над сложным заданием студенты трудятся более напряженно; (2) целеустремленные студенты работают упорнее, чем ленивые? Ни одно из этих утверждений не отражает сущность систематического характера средних, приведенных в таблице. Анализируя результаты, правильнее было бы сказать, что над сложными заданиями работают упорнее только целеустремленные студенты, в то время как над легкими заданиями только ленивые работают упорнее. Другими словами характер студентов и сложность задания взаимодействуя между собой влияют на затрачиваемое усилие. Это пример парного взаимодействия между характером студентов и сложностью задания. Отметим, что утверждения 1 и 2 описывают главные эффекты .
Взаимодействия высших порядков. В то время как объяснить попарные взаимодействия еще сравнительно легко, взаимодействия высших порядков объяснить значительно сложнее. Представим себе, что в рассматриваемый выше пример, введен еще один фактор пол -Gender и мы получили следующую таблицу средних значений:
Какие теперь выводы можно сделать из полученных результатов? Графики средних позволяют легко интерпретировать сложные эффекты. Модуль дисперсионного анализа позволяет строить эти графики практически одним щелчком мышки.
Изображение на графиках внизу представляет собой изучаемое трехфакторное взаимодействие.

Глядя на графики, можно сказать, что у женщин существует взаимодействие между характером и сложностью теста: целеустремленные женщины работают над трудным заданием более напряженно, чем над легким. У мужчин это же взаимодействие носит обратный характер. Видно, что описание взаимодействия между факторами становится более запутанным.
Общий способ описания взаимодействий. В общем случае взаимодействие между факторами описывается в виде изменения одного эффекта под воздействием другого. В рассмотренном выше примере двухфакторное взаимодействие можно описать как изменение главного эффекта фактора, характеризующего сложность задачи, под воздействием фактора, описывающего характер студента. Для взаимодействия трех факторов из предыдущего параграфа можно сказать, что взаимодействие двух факторов (сложности задачи и характера студента) изменяется под воздействием пола – Gender . Если изучается взаимодействие четырех факторов, можно сказать, что взаимодействие трех факторов, изменяется под воздействием четвертого фактора, т.е. существуют различные типы взаимодействий на разных уровнях четвертого фактора. Оказалось, что во многих областях взаимодействие пяти или даже большего количества факторов не является чем-то необычным.
Сложные планы
Межгрупповые и внутригрупповые планы (планы с повторными измерениями)
При сравнении двух различных групп обычно используется t - критерий для независимых выборок (из модуля Основные статистики и таблицы ). Когда сравниваются две переменные на одном и том же множестве объектов (наблюдений), используется t -критерий для зависимых выборок. Для дисперсионного анализа также важно зависимы или нет выборки. Если имеются повторные измерения одних и тех же переменных (при разных условиях или в разное время) для одних и тех же объектов , то говорят о наличии фактора повторных измерений (называемого также внутригрупповым фактором, поскольку для оценки его значимости вычисляется внутригрупповая сумма квадратов). Если сравниваются разные группы объектов (например, мужчины и женщины, три штамма бактерий и т.п.), то разница между группами описывается межгрупповым фактором. Способы вычисления критериев значимости для двух описанных типов факторов различны, но общая их логика и интерпретации совпадает.
Меж- и внутригрупповые планы. Во многих случаях эксперимент требует включение в план и межгруппового фактора, и фактора повторных измерений. Например, измеряются математические навыки студентов женского и мужского пола (где пол – Gender -межгрупповой фактор) в начале и в конце семестра. Два измерения навыковкаждого студента образуют внутригрупповой фактор (фактор повторных измерений). Интерпретация главных эффектов и взаимодействий для межгрупповых факторов и факторов повторных измерений совпадает, и оба типа факторов могут, очевидно, взаимодействовать между собой (например, женщины приобретают навыки в течение семестра, а мужчины их теряют).
Неполные (гнездовые) планы
Во многих случаях можно пренебречь эффектом взаимодействия. Это происходит или когда известно, что в популяции эффект взаимодействия отсутствует, или когда осуществление полного факторного плана невозможно. Например, изучается влияние четырех добавок к топливу на расход горючего. Выбираются четыре автомобиля и четыре водителя. Полный факторный эксперимент требует, чтобы каждая комбинация: добавка, водитель, автомобиль - появились хотя бы один раз. Для этого нужно не менее 4 x 4 x 4 = 64 групп испытаний, что требует слишком больших временных затрат. Кроме того, вряд ли существует взаимодействие между водителем и добавкой к топливу. Принимая это во внимание, можно использовать план Латинские квадраты, в котором содержится лишь16 групп испытаний (четыре добавки обозначаются буквами A, B, C и D):
Латинские квадраты описаны в большинстве книг по планированию экспериментов (например, Hays, 1988; Lindman, 1974; Milliken and Johnson, 1984; Winer, 1962), и здесь они не будут детально обсуждаться. Отметим, что латинские квадраты это не n олные планы, в которых участвуют не все комбинации уровней факторов. Например, водитель 1 управляет автомобилем 1 только с добавкой А, водитель 3 управляет автомобилем 1 только с добавкой С. Уровни фактора добавок (A, B, C и D) вложены в ячейки таблицы автомобиль x водитель – как яйца в гнезда. Это мнемоническое правило полезно для понимания природы гнездовых или вложенных планов. Модуль Дисперсионный анализ предоставляет простые способы анализ планов такого типа.
Ковариационный анализ
Основная идея
В разделе Основные идеи кратко обсуждалась идея управления факторами и то, каким образом включение аддитивных факторов позволяет уменьшать сумму квадратов ошибок и увеличивать статистическую мощность плана. Все это может быть распространено и на переменные с непрерывным множеством значений. Когда такие непрерывные переменные включаются в план в качестве факторов, они называются ковариатами .
Фиксированные ковариаты
Предположим, что сравниваются математические навыки двух групп студентов, которые обучались по двум различным учебникам. Предположим также, что имеются данные о коэффициенте интеллекта (IQ) для каждого студента. Можно предположить, что коэффициент интеллекта связан с математическими навыками, и использовать эту информацию. Для каждой из двух групп студентов можно вычислить коэффициент корреляции между IQ и математическими навыками. Используя этот коэффициент корреляции, можно выделить долю дисперсии в группах, объясняемую влиянием IQ и необъясняемую долю дисперсии (см. также Элементарные понятия статистики (глава 8) и Основные статистики и таблицы (глава 9)). Оставшаяся доля дисперсии используется при проведении анализа как дисперсия ошибки. Если имеется корреляция между IQ и математическими навыками, то можно существенно уменьшить дисперсии ошибки SS /(n -1) .
Влияние ковариат на F- критерий. F- критерий оценивает статистическую значимость различия средних значений в группах, при этом вычисляется отношение межгрупповой дисперсии (MS effect ) к дисперсии ошибок (MS error ) . Если MS error уменьшается, например, при учете фактора IQ, значение F увеличивается.
Множество ковариат. Рассуждения, использованные выше для одной ковариаты (IQ), легко распространяются на несколько ковариат. Например, кроме IQ, можно включить измерение мотивации, пространственного мышления и т.д. Вместо обычного коэффициента корреляции при этом используется множественный коэффициент корреляции.
Когда значение F -критерия уменьшается. Иногда введение ковариат в план эксперимента уменьшает значение F -критерия. Обычно это указывает на то, что ковариаты коррелированы не только с зависимой переменной (например, математическими навыками), но и с факторами (например, с разными учебниками). Предположим, что IQ измеряется в конце семестра, после почти годового обучения двух групп студентов по двум разным учебникам. Хотя студенты разбивались на группы случайным образом, может оказаться, что различие учебников настолько велико, что и IQ и математические навыки в разных группах будут сильно различаться. В этом случае, ковариаты не только уменьшают дисперсию ошибок, но и межгрупповую дисперсию. Другими словами, после контроля за разностью IQ в разных группах, разность в математических навыках уже будет несущественной. Можно сказать иначе. После “исключения” влияния IQ, неумышленно исключается и влияние учебника на развитие математических навыков.
Скорректированные средние. Когда ковариата влияет на межгрупповой фактор, следует вычислять скорректированные средние , т.е. такие средние, которые получаются после удаления всех оценок ковариат.
Взаимодействие между ковариатами и факторами. Также как исследуется взаимодействие между факторами, можно исследовать взаимодействие между ковариатами и между группами факторов. Предположим, что один из учебников особенно подходит для умных студентов. Второй учебник для умных студентов скушен, а для менее умных студентов этот же учебник труден. В результате имеется положительная корреляция между IQ и результатом обучения в первой группе (более умные студенты, лучше результат) и нулевая или небольшая отрицательная корреляция во второй группе (чем умнее студент, тем менее вероятно приобретение математических навыков из второго учебника). В некоторых исследованиях эта ситуация обсуждается как пример нарушения предположений ковариационного анализа. Однако так как в модуле Дисперсионный анализ используются самые общие способы ковариационного анализа, можно, в частности, оценить статистическую значимость взаимодействия между факторами и ковариатами.
Переменные ковариаты
В то время как фиксированные ковариаты обсуждаются в учебниках достаточно часто, переменные ковариаты упоминаются намного реже. Обычно, при проведении экспериментов с повторными измерениями, нас интересуют различия в измерениях одних и тех же величин в разные моменты времени. А именно, нас интересует значимость этих различий. Если одновременно с измерениями зависимых переменных проводится измерение ковариат, можно вычислить корреляцию между ковариатой и зависимой переменной.
Например, можно изучать интерес к математике и математические навыки в начале и в конце семестра. Интересно было бы проверить, коррелированы ли между собой изменения в интересе к математике с изменением математических навыков.
Модуль Дисперсионный анализ в STATISTICA автоматически оценивает статистическую значимость изменения ковариат в тех планах, где это возможно.
Многомерные планы: многомерный дисперсионный и ковариационный анализ
Межгрупповые планы
Все рассматриваемые ранее примеры включали только одну зависимую переменную. Когда одновременно имеется несколько зависимых переменных, возрастает лишь сложность вычислений, а содержание и основные принципы не меняются.
Например, проводится исследование двух различных учебников. При этом изучаются успехи студентов в изучении физики и математики. В этом случае имеются две зависимые переменные и нужно выяснить, как влияют на них одновременно два разных учебника. Для этого можно воспользоваться многомерным дисперсионным анализом (MANOVA). Вместо одномерного F критерия, используется многомерный F критерий (l-критерий Уилкса), основанный на сравнении ковариационной матрицы ошибок и межгрупповой ковариационной матрицы.
Если зависимые переменные коррелированы между собой, то эта корреляция должна учитываться при вычислении критерия значимости. Очевидно, если одно и то же измерение повторяется дважды, то ничего нового получить при этом нельзя. Если к имеющемуся измерению добавляется коррелированное с ним измерение, то получается некоторая новая информация, но при этом новая переменная содержит избыточную информацию, которая отражается в ковариации между переменными.
Интерпретация результатов. Если общий многомерный критерий значим, можно заключить, что соответствующий эффект (например, тип учебника) значим. Однако встают следующие вопросы. Влияет ли тип учебника на улучшение только математических навыков, только физических навыков, или одновременно на улучшение тех и других навыков. В действительности, после получения значимого многомерного критерия, для отдельного главного эффекта или взаимодействия исследуется одномерный F критерий. Другими словами, отдельно исследуются зависимые переменные, которые вносят вклад в значимость многомерного критерия.
Планы с повторными измерениями
Если измеряются математические и физические навыки студентов в начале семестра и в конце, то это и есть повторные измерения. Изучение критерия значимости в таких планах это логическое развитие одномерного случая. Заметим, что методы многомерного дисперсионного анализа обычно также используются для исследования значимости одномерных факторов повторных измерений, имеющих более чем два уровня. Соответствующие применения будут рассмотрены позднее в этой части.
Суммирование значений переменных и многомерный дисперсионный анализ
Даже опытные пользователи одномерного и многомерного дисперсионного анализа часто приходят в затруднение, получая разные результаты при применении многомерного дисперсионного анализа, например, для трех переменных, и при применении одномерного дисперсионного анализа к сумме этих трех переменных, как к одной переменной.
Идея суммирования переменных состоит в том, что каждая переменная содержит в себе некоторую истинную переменную, которая и исследуется, а также случайную ошибку измерения. Поэтому при усреднении значений переменных, ошибка измерения будет ближе к 0 для всех измерений и усредненное значений будет более надежным. На самом деле, в этом случае применение дисперсионного анализа к сумме переменных разумно и является мощным методом. Однако если зависимые переменные по своей природе многомерны, суммирование значений переменных неуместно.
Например, пусть зависимые переменные состоят из четырех показателей успеха в обществе . Каждый показатель характеризует совершенно независимую сторону человеческой деятельности (например, профессиональный успех, преуспеваемость в бизнесе, семейное благополучие и т.д.). Сложение этих переменных подобно сложению яблока и апельсина. Сумма этих переменных не будет подходящим одномерным показателем. Поэтому с такими данными нужно обходится как с многомерными показателями в многомерном дисперсионном анализе .
Анализ контрастов и апостериорные критерии
Почему сравниваются отдельные множества средних?
Обычно гипотезы относительно экспериментальных данных формулируются не просто в терминах главных эффектов или взаимодействий. Примером может служить такая гипотеза: некоторый учебник повышает математические навыки только у студентов мужского пола, в то время как другой учебник примерно одинаково эффективен для обоих полов, но все же менее эффективен для мужчин. Можно предсказать, что эффективность учебника взаимодействует с полом студента. Однако этот прогноз касается также природы взаимодействия. Ожидается значительное различие между полами для обучающихся по одной книге и практически не зависимые от пола результаты для обучающихся по другой книге. Такой тип гипотез обычно исследуется с помощью анализа контрастов.
Анализ контрастов
Если говорить коротко, то анализ контрастов позволяет оценивать статистическую значимость некоторых линейных комбинаций эффектов сложного плана. Анализ контрастов главный и обязательный элемент любого сложного плана дисперсионного анализа. Модуль Дисперсионный анализ имеет достаточно разнообразные возможности анализа контрастов, которые позволяют выделять и анализировать любые типы сравнений средних.
Апостериорные сравнения
Иногда в результате обработки эксперимента обнаруживается неожиданный эффект. Хотя в большинстве случаев творческий исследователь сможет объяснить любой результат, это не дает возможностей для дальнейшего анализа и получения оценок для прогноза. Эта проблема является одной из тех, для которых используются апостериорные критерии , то есть критерии, не использующие априорные гипотезы. Для иллюстрации рассмотрим следующий эксперимент. Предположим, что на 100 карточках записаны числа от 1 до 10. Опустив все эти карточки в шапку, мы случайным образом выбираем 20 раз по 5 карточек, и вычисляем для каждой выборки среднее значение (среднее чисел, записанных на карточки). Можно ли ожидать, что найдутся две выборки, у которых средние значения значимо отличаются? Это очень правдоподобно! Выбирая две выборки с максимальным и минимальным средним, можно получить разность средних, сильно отличающуюся от разности средних, например, первых двух выборок. Эту разность можно исследовать, например, с помощью анализа контрастов. Если не вдаваться в детали, то существует несколько, так называемых апостериорных критериев, которые основаны в точности на первом сценарии (взятие экстремальных средних из 20 выборок), т. е. эти критерии основаны на выборе наиболее отличающихся средних для сравнения всехсредних значений в плане. Эти критерии применяются для того, чтобы чисто случайно не получить искусственный эффект, например, обнаружить значимое различие между средними, когда его нет. Модуль Дисперсионный анализ предлагает широкий выбор таких критериев. Когда в эксперименте, связанном с несколькими группами, встречаются неожиданные результаты, то используются апостериорные процедуры для исследования статистической значимости полученных результатов.
Сумма квадратов типа I, II, III и IV
Многомерная регрессия и дисперсионный анализ
Существует тесная взаимосвязь между методом многомерной регрессии и дисперсионным анализом (анализом вариаций). И в том и в другом методе исследуется линейная модель. Если говорить коротко, то практически все планы эксперимента можно исследовать с помощью многомерной регрессии. Рассмотрим следующий простой межгрупповой 2 x 2 план.
| DV | A | B | AxB |
|---|---|---|---|
| 3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 |
| 4 | 1 | -1 | -1 |
| 5 | 1 | -1 | -1 |
| 6 | -1 | 1 | -1 |
| 6 | -1 | 1 | -1 |
| 3 | -1 | -1 | 1 |
| 2 | -1 | -1 | 1 |
Столбцы А и В содержат коды, характеризующие уровни факторов А и В, столбец АxВ содержит произведение двух столбцов А и В. Мы можем анализировать эти данные с помощью многомерной регрессии. Переменная DV определяется как зависимая переменная, переменные от A до AxB как независимые переменные. Исследование значимости для коэффициентов регрессии будет совпадать с вычислениями в дисперсионном анализе значимости главных эффектов факторов A и B и эффекта взаимодействия AxB .
Несбалансированные и сбалансированные планы
При вычислении корреляционной матрицы для всех переменных, например, для данных, изображенных выше, можно заметить, что главные эффекты факторов A и B и эффект взаимодействия AxB некоррелированы. Это свойство эффектов называют также ортогональностью. Говорят, что эффекты A и B - ортогональны или независимы друг от друга. Если все эффекты в плане ортогональны друг другу, как в приведенном выше примере, то говорят, что план сбалансирован .
Сбалансированные планы обладают “хорошим свойством”. Вычисления при анализе таких планов очень просты. Все вычисления сводятся к вычислению корреляции между эффектами и зависимыми переменными. Так как эффекты ортогональны, частные корреляции (как в полной многомерной регрессии) не вычисляются. Однако в реальной жизни планы не всегда сбалансированы.
Рассмотрим реальные данные с неравным числом наблюдений в ячейках.
| Фактор A | Фактор B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | 2 |
Если закодировать эти данные как выше и вычислить корреляционную матрицу для всех переменных, то окажется, что факторы плана коррелированы друг с другом. Факторы в плане теперь не ортогональны и такие планы называются несбалансированными. Заметим, что в рассматриваемом примере, корреляция между факторами полностью связана с различием частот 1 и -1 в столбцах матрицы данных. Другими словами, планы экспериментов с неравными объемами ячеек (точнее, непропорциональными объемами) будут несбалансированными, это означает, что главные эффекты и взаимодействия будут смешиваться. В этом случае для вычисления статистической значимости эффектов нужно полностью вычислять многомерную регрессию. Здесь имеется несколько стратегий.
Сумма квадратов типа I, II, III и IV
Сумма квадратов типа I и III . Для изучения значимости каждого фактора в многомерной модели можно вычислять частную корреляцию каждого фактора, при условии, что все другие факторы уже учтены в модели. Можно также вводить факторы в модель пошаговым способом, фиксируя все факторы, уже введенные в модель и игнорируя все остальные факторы. Вообще, в этом и состоит различие между типом III и типом I суммы квадратов (эта терминология была введена в SAS, см. например, SAS, 1982; подробное обсуждение можно также найти в Searle, 1987, стр. 461; Woodward, Bonett, and Brecht, 1990, стр. 216; или Milliken and Johnson, 1984, стр. 138).
Сумма квадратов типа II. Следующая “промежуточная” стратегия формирования модели состоит: в контроле всех главных эффектов при исследовании значимости отдельного главного эффекта; в контроле всех главных эффектов и всех попарных взаимодействий, когда исследуется значимость отдельного попарного взаимодействия; в контроле всех главных эффектов всех попарных взаимодействий и всех взаимодействий трех факторов; при исследовании отдельного взаимодействия трех факторов и т.д. Суммы квадратов для эффектов, вычисляемые таким способом, называются типом II суммы квадратов. Итак, тип II суммы квадратов контролирует все эффекты того же порядка и ниже, игнорируя все эффекты более высокого порядка.
Сумма квадратов типа IV . Наконец, для некоторых специальных планов с пропущенными ячейками (неполными планами) можно вычислять, так называемые, типа IV суммы квадратов. Этот метод будет обсуждаться позднее в связи с неполными планами (планами с пропущенными ячейками).
Интерпретация гипотезы о сумме квадратов типа I, II, и III
Сумму квадратов типа III легче всего интерпретировать. Напомним, что суммы квадратов типа III исследуют эффекты после контроля всех других эффектов. Например, после нахождения статистически значимого типа III эффекта для фактора A в модуле Дисперсионный анализ , можно сказать, что существует единственный значимый эффект фактора A , после введения всех других эффектов (факторов) и соответственно интерпретировать этот эффект. Вероятно в 99% всех приложений дисперсионного анализа именно этот тип критерия интересует исследователя. Этот тип суммы квадратов обычно вычисляется в модуле Дисперсионный анализ по умолчанию, независимо от того выбрана опция Регрессионный подход или нет (стандартные подходы принятые в модуле Дисперсионный анализ обсуждаются ниже).
Значимые эффекты, полученные с помощью сумм квадратов типа или типа II суммы квадратов интерпретировать не так легко. Лучше всего их интерпретировать в контексте пошаговой многомерной регрессии. Если при использовании суммы квадратов типа I главный эффект фактора В оказался значим (после включения в модель фактора А, но перед добавлением взаимодействия между А и В), можно заключить, что существует значимый главный эффект фактора В, при условии, что нет взаимодействия между факторами А и В. (Если при использовании критерия типа III , фактор В также оказался значимым, то можно заключить, что существует значимый главный эффект фактора B, после введения в модель всех других факторов и их взаимодействий).
В терминах маргинальных средних гипотезы типа I и типа II обычно не имеют простой интерпретации. В этих случаях говорят, что нельзя интерпретировать значимость эффектов, рассматривая только маргинальные средние. Скорее представленные p значений средних имеют отношение к сложной гипотезе, которая комбинирует средние и объем выборки. Например, тип II гипотезы для фактора А в простом примере плана 2 x 2, рассматриваемом ранее будут (см. Woodward, Bonett, and Brecht, 1990, стр. 219):
nij - число наблюдений в ячейке
uij - среднее значение в ячейке
n . j - маргинальное среднее
Если не вдаваться в детали (более подробно см. Milliken and Johnson, 1984, глава 10), то ясно, что это не простые гипотезы и в большинстве случаев ни одна из них не представляет особенного интереса у исследователя. Однако существуют случаи, когда гипотезы типа I могут быть интересны.
Принимаемый по умолчанию вычислительный подход в модуле Дисперсионный анализ
По умолчанию, если не отмечена опция Регрессионный подход , модуль Дисперсионный анализ использует модель средних по ячейкам . Для этой модели характерно, что суммы квадратов для разных эффектов вычисляются для линейных комбинаций средних значений по ячейкам. В полном факторном эксперименте это приводит к суммам квадратов, которые совпадают с суммами квадратов, обсуждаемыми ранее как тип III . Однако в опции Спланированные сравнения (в окне Результаты дисперсионного анализа ), пользователь может проверять гипотезу относительно любой линейной комбинации взвешенных или невзвешенных средних по ячейкам. Таким образом, пользователь может проверять не только гипотезы типа III , но гипотезы любого типа (включая тип IV ). Этот общий подход особенно полезен, когда исследуются планы с пропущенными ячейками (так называемые неполные планы).
Для полных факторных планов этот подход полезно также использовать в тех случаях, когда хотят анализировать взвешенные маргинальные средние. Например, предположим, что в рассматриваемом ранее простом 2 x 2 плане, нужно сравнить взвешенные (по уровням фактора B ) маргинальные средние для фактора А. Это бывает полезным, когда распределение наблюдений по ячейкам не готовилось экспериментатором, а строилось случайно, и эта случайность отражается в распределении числа наблюдений по уровням фактора B в совокупности.
Например, имеется фактор - возраст вдов. Возможная выборка респондентов разбита на две группы: моложе 40 лет и старше 40 (фактор В). Второй фактор (фактор А) в плане - получали или нет социальную поддержку вдовы в некотором агентстве (при этом одни вдовы были выбраны случайно, другие служили в качестве контроля). В этом случае распределение вдов по возрастам в выборке отражает действительное распределение вдов по возрастам в совокупности. Оценке эффективности группы социальной поддержки вдов по всем возрастам будет соответствовать взвешенное среднее для двух возрастных групп (с весами соответствующими числу наблюдений в группе).
Спланированные сравнения
Заметим, что сумма введенных коэффициентов контрастов не обязательно равна 0 (нулю). Вместо этого программа будет автоматически вносить поправки, чтобы соответствующие гипотезы не смешивались с общим средним.
Для иллюстрации этого вернемся опять к простому 2 x 2 плану, рассмотренному ранее. Напомним, что числа наблюдений в ячейках этого несбалансированного плана -1, 2, 3, и 1. Предположим, что мы хотим сравнить взвешенные маргинальные средние для фактора А (взвешенные с частотой уровней фактора В). Можно ввести коэффициенты контраста:
Заметим, что эти коэффициенты не дают в сумме 0. Программа будет устанавливать коэффициенты так, что в сумме они будут давать 0, и при этом будут сохраняться их относительные значения, т. е.:
1/3 2/3 -3/4 -1/4
Эти контрасты будут сравнивать взвешенные средние для фактора А.
Гипотезы о главном среднем. Гипотеза, о том, что не взвешенное главное среднее равно 0 может исследоваться с помощью коэффициентов:
Гипотеза о том, что взвешенное главное среднее равно 0 проверяется с помощью:
Ни в одном случае программа не производит корректировки коэффициентов контрастов.
Анализ планов с пропущенными ячейками (неполные планы)
Факторные планы, содержащие пустые ячейки (обработка комбинаций ячеек, в которых нет наблюдений) называются неполными. В таких планах некоторые факторы обычно не ортогональны и некоторые взаимодействия не могут быть вычислены. Вообще не существует лучшего метода анализа таких планов.
Регрессионный подход
В некоторых старых программах, которые основаны на анализе планов дисперсионного анализа с помощью многомерной регрессии, факторы в неполных планах по умолчанию задаются обычным образом (как будто план полный). Затем производится многомерный регрессионный анализ для этих фиктивно закодированных факторов. К несчастью, этот метод приводит к результатам, которые очень трудно, или даже невозможно, интерпретировать, так как неясно, как каждый эффект участвует в линейной комбинации средних значений. Рассмотрим следующий простой пример.
| Фактор A | Фактор B | |
|---|---|---|
| B1 | B2 | |
| A1 | 3 | 4, 5 |
| A2 | 6, 6, 7 | Пропущено |
Если будет выполняться многомерная регрессия вида Зависимая переменная = Константа + Фактор A + Фактор B , то гипотеза о значимости факторов A и B в терминах линейных комбинаций средних выглядит так:
Фактор A: Ячейка A1,B1 = Ячейка A2,B1
Фактор B: Ячейка A1,B1 = Ячейка A1,B2
Этот случай прост. В более сложных планах невозможно фактически определить, что точно будет исследоваться.
Средние ячеек, подход дисперсионного анализа, гипотезы типа IV
Подход, который рекомендуется в литературе и который кажется предпочтительнее - исследование осмысленных (с точки зрения исследовательских задач) априорных гипотез о средних, наблюдаемых в ячейках плана. Подробное обсуждение этого подхода можно найти в Dodge (1985), Heiberger (1989), Milliken and Johnson (1984), Searle (1987), или Woodward, Bonett, and Brecht (1990). Суммы квадратов, ассоциированные с гипотезами о линейной комбинации средних в неполных планах, исследующие оценки части эффектов, называются также суммами квадратов IV .
Автоматическая генерация гипотез типа IV . Когда многофакторные планы имеют сложный характер пропущенных ячеек, желательно определить ортогональные (независимые) гипотезы, исследование которых эквивалентно исследованию главных эффектов или взаимодействий. Были развиты алгоритмические (вычислительные) стратегии (основанные на псевдообратной матрице плана) для генерирования подходящих весов для таких сравнений. К сожалению, окончательные гипотезы определяются не единственным образом. Конечно, они зависят от порядка, в котором эффекты были определены и редко допускают простую интерпретацию. Поэтому рекомендуется внимательно изучить характер пропущенных ячеек, затем формулировать гипотезы типа IV , которые наиболее содержательно соответствуют целям исследования. Затем исследовать эти гипотезы, используя опцию Спланированные сравнения в окне Результаты . Самый легкий путь задать сравнения в этом случае - требовать введения вектора контрастов для всех факторов вместе в окне Спланированные сравнения. После вызова диалогового окна Спланированные сравнения будут показаны все группы текущего плана и помечены те, которые пропущены.
Пропущенные ячейки и проверка специфического эффекта
Существует несколько типов планов, в которых расположение пропущенных ячеек не случайно, но тщательно спланировано, что позволяет проводить простой анализ главных эффектов не затрагивая другие эффекты. Например, когда необходимое число ячеек в плане недоступно, часто используются планы Латинские квадраты для оценивания главных эффектов нескольких факторов с большим числом уровней. Например, 4 x 4 x 4 x 4 факторный план требует 256 ячеек. В то же время можно использовать Греко-латинский квадрат для оценки главных эффектов, имея только 16 ячеек в плане (глава Планирование эксперимента , том IV, содержит детальное описание таких планов). Неполные планы, в которых главные эффекты (и некоторые взаимодействия) могут быть оценены с помощью простых линейных комбинаций средних, называются сбалансированными неполными планами .
В сбалансированных планах стандартный (по умолчанию) метод генерирования контрастов (весов) для главных эффектов и взаимодействий будет затем производить анализ таблицы дисперсий, в которой суммы квадратов для соответствующих эффектов не смешиваются друг с другом. Опция Специфический эффекты окна Результаты будет генерировать пропущенные контрасты, записывая ноль в пропущенные ячейки плана. Сразу после того, как будет запрошена опция Специфический эффекты для пользователя, изучающего некоторую гипотезу, появляется таблица результатов с фактическими весами. Заметим, что в сбалансированном плане, суммы квадратов соответствующих эффектов вычисляются только, если эти эффекты ортогональны (независимы) всем другим главным эффектам и взаимодействиям. В противном случае нужно воспользоваться опцией Спланированные сравнения для изучения содержательных сравнений между средними.
Пропущенные ячейки и объединенные эффекты/члены ошибки
Если опция Регрессионное подход в стартовой панели модуля Дисперсионный анализ не выбрана, то при вычислении суммы квадратов для эффектов будет использоваться модель средних по ячейкам (установка по умолчанию). Если план не сбалансирован, то при объединении неортогональных эффектов (см. выше обсуждение опции Пропущенные ячейки и специфический эффект ) можно получить сумму квадратов, состоящую из неортогональных (или перекрывающихся) компонент. Полученные при этом результаты, обычно не интерпретируемы. Поэтому нужно быть очень осторожным при выборе и реализации сложных неполных экспериментальных планов.
Существует много книг с детальным обсуждением планов разного типа. (Dodge, 1985; Heiberger, 1989; Lindman, 1974; Milliken and Johnson, 1984; Searle, 1987; Woodward and Bonett, 1990), но такого рода информация лежит вне границ этого учебника. Тем не менее, позднее в этом разделе будет продемонстрирован анализ различного типа планов.
Предположения и эффекты нарушения предположений
Отклонение от предположения о нормальности распределений
Предположим, что зависимая переменная измерена в числовой шкале. Предположим также, что зависимая переменная имеет нормальное распределение внутри каждой группы. Дисперсионный анализ содержит широкий набор графиков и статистик для обоснования этого предположения.
Эффекты нарушения. Вообще F критерий очень устойчив к отклонению от нормальности (подробные результаты см. в работе Lindman, 1974). Если эксцесс больше 0, то значение статистики F может стать очень маленьким. Нулевая гипотеза при этом принимается, хотя она может быть и не верна. Ситуация меняется на противоположную, когда эксцесс меньше 0. Асимметрия распределения обычно незначительно влияет на F статистику. Если число наблюдений в ячейке достаточно большое, то отклонение от нормальности не имеет особого значения в силу центральной предельной теоремы , в соответствии с которой, распределение среднего значения близко к нормальному, независимо от начального распределения. Подробное обсуждение устойчивости F статистики можно найти в Box and Anderson (1955), или Lindman (1974).
Однородность дисперсии
Предположения. Предполагается, что дисперсии разных групп плана одинаковы. Это предположение называется предположением об однородности дисперсии. Вспомним, что в начале этого раздела, описывая вычисление суммы квадратов ошибок, мы производили суммирование внутри каждой группы. Если дисперсии в двух группах отличаются друг от друга, то сложение их не очень естественно и не дает оценки общей внутригрупповой дисперсии (так как в этом случае общей дисперсии вообще не существует). Модуль Дисперсионный анализ - ANOVA /MANOVA содержит большой набор статистических критериев обнаружения отклонения от предположений однородности дисперсии.
Эффекты нарушения. Линдман (Lindman 1974, стр. 33) показывает, что F критерий вполне устойчив относительно нарушения предположений однородности дисперсии (неоднородность дисперсии, см. также Box, 1954a, 1954b; Hsu, 1938).
Специальный случай: коррелированность средних и дисперсий. Бывают случаи, когда F статистика может вводить в заблуждение. Это бывает, когда в ячейках плана средние значения коррелированы с дисперсией. Модуль Дисперсионный анализ позволяет строить диаграммы рассеяния дисперсии или стандартного отклонения относительно средних для обнаружения такой корреляции. Причина, по которой такая корреляция опасна, состоит в следующем. Представим себе, что имеется 8 ячеек в плане, 7 из которых имеют почти одинаковое среднее, а в одной ячейке среднее намного больше остальных. Тогда F критерий может обнаружить статистически значимый эффект. Но предположим, что в ячейке с большим средним значением и дисперсия значительно больше остальных, т.е. среднее значение и дисперсия в ячейках зависимы (чем больше среднее, тем больше дисперсия). В этом случае большое среднее значение ненадежно, так как оно может быть вызвано большой дисперсией данных. Однако F статистика, основанная на объединенной дисперсии внутри ячеек, будет фиксировать большое среднее, хотя критерии, основанные на дисперсии в каждой ячейке, не все различия в средних будут считать значимыми.
Такой характер данных (большое среднее и большая дисперсия) - часто встречается, когда имеются резко выделяющиеся наблюдения. Одно или два резко выделяющихся наблюдений сильно смещают среднее значение и очень увеличивают дисперсию.
Однородность дисперсии и ковариаций
Предположения. В многомерных планах, с многомерными зависимыми измерениями, также применяются предположение об однородности дисперсии, описанные ранее. Однако так как существуют многомерные зависимые переменные, то требуется так же чтобы их взаимные корреляции (ковариации) были однородны по всем ячейкам плана. Модуль Дисперсионный анализ предлагает разные способы проверки этих предположений.
Эффекты нарушения . Многомерный аналог F - критерия - λ-критерий Уилкса. Не так много известно об устойчивости (робастности) λ-критерия Уилкса относительно нарушения указанных выше предположений. Тем не менее, так как интерпретация результатов модуля Дисперсионный анализ основывается обычно на значимости одномерных эффектов (после установления значимости общего критерия), обсуждение робастности касается, в основном, одномерного дисперсионного анализа. Поэтому должна быть внимательно исследована значимость одномерных эффектов.
Специальный случай: ковариационный анализ. Особенно серьезные нарушения однородности дисперсии/ковариаций могут происходить, когда в план включаются ковариаты. В частности, если корреляция между ковариатами и зависимыми измерениями различна в разных ячейках плана, может последовать неверное истолкование результатов. Следует помнить, что в ковариационном анализе, в сущности, проводится регрессионный анализ внутри каждой ячейки для того, чтобы выделить ту часть дисперсии, которая соответствует ковариате. Предположение об однородности дисперсии/ковариации предполагает, что этот регрессионный анализ проводится при следующем ограничении: все регрессионные уравнения (наклоны) для всех ячеек одинаковы. Если это не предполагается, то могут появиться большие ошибки. Модуль Дисперсионный анализ имеет несколько специальных критериев для проверки этого предположения. Можно посоветовать использовать эти критерии, для того, чтобы убедиться, что регрессионные уравнения для различных ячеек примерно одинаковы.
Сферичность и сложная симметрия: причины использования многомерного подхода к повторным измерениям в дисперсионном анализе
В планах, содержащих факторы повторных измерений с более чем двумя уровнями, применение одномерного дисперсионного анализа требует дополнительных предположений: предположения о сложной симметрии и предположения о сферичности. Эти предположения редко выполняются (см. ниже). Поэтому в последние годы многомерный дисперсионный анализ завоевал популярность в таких планах (оба подхода совмещены в модуле Дисперсионный анализ ).
Предположение о сложной симметрии Предположение о сложной симметрии состоит в том, что дисперсии (общие внутригрупповые) и ковариации (по группам) для различных повторных измерений однородны (одинаковы). Это достаточное условие для того, чтобы одномерный F критерий для повторных измерений был обоснованным (т.е. выданные F-значения в среднем соответствовали F-распределению). Однако в данном случае это условие не является необходимым.
Предположение о сферичности. Предположение о сферичности является необходимым и достаточным условием того, чтобы F-критерий был обоснованным. Оно состоит в том, что внутри групп все наблюдения независимы и одинаково распределены. Природа этих предположений, а также влияние их нарушений обычно не очень хорошо описаны в книгах по дисперсионному анализу - эта будет описано в следующих параграфах. Там же будет показано, что результаты одномерного подхода могут отличаться от результатов многомерного подхода, и будет объяснено, что это означает.
Необходимость независимости гипотез. Общий способ анализа данных в дисперсионном анализе – это подгонка модели . Если относительно модели, соответствующей данным, имеются некоторые априорные гипотезы, то дисперсия разбивается для проверки этих гипотез (критерии главных эффектов, взаимодействий). С точки зрения вычислений, этот подход генерирует некоторое множество контрастов (множество сравнений средних в плане). Однако если контрасты не независимы друг от друга, разбиение дисперсий становится бессодержательным. Например, если два контраста A и B тождественны и выделяется соответствующая им часть из дисперсии, то одна и та же часть выделяется дважды. Например, глупо и бессмысленно выделять две гипотезы: “среднее в ячейке 1 выше среднего в ячейке 2” и “среднее в ячейке 1 выше среднего в ячейке 2”. Итак, гипотезы должны быть независимы или ортогональны.
Независимые гипотезы при повторных измерениях. Общий алгоритм, реализованный в модуле Дисперсионный анализ , будет пытаться для каждого эффекта генерировать независимые (ортогональные) контрасты. Для фактора повторных измерений эти контрасты задают множество гипотез относительно разностей между уровнями рассматриваемого фактора. Однако если эти разности коррелированы внутри групп, то результирующие контрасты не являются больше независимыми. Например, в обучении, где обучающиеся измеряются три раза за один семестр, может случиться, что изменения между 1 и 2 измерением отрицательно коррелируют с изменением между 2 и 3 измерениями субъектов. Те, кто большую часть материала освоил между 1 и 2 измерениями, осваивают меньшую часть в течение того времени, которое прошло между 2 и 3 измерением. В действительности, для большинства случаев, где дисперсионный анализ используются при повторных измерениях, можно предположить, что изменения по уровням коррелированы по субъектам. Однако когда это случается, предположение о сложной симметрии и предположения о сферичности не выполняются и независимые контрасты не могут быть вычислены.
Влияние нарушений и способы их исправления. Когда предположения о сложной симметрии или о сферичности не выполняются, дисперсионный анализ может выдать ошибочные результаты. До того, как были достаточно разработаны многомерные процедуры, было предложено несколько предположений для компенсации нарушений этих предположений. (см., например, работы Greenhouse & Geisser, 1959 и Huynh & Feldt, 1970). Эти методы до сих пор широко используются (поэтому они представлены в модуле Дисперсионный анализ ).
Подход многомерного дисперсионного анализа к повторным измерениям. В целом проблемы сложной симметрии и сферичности относятся к тому факту, что множества контрастов, включенных в исследование эффектов факторов повторных измерений (с числом уровней большим, чем 2) не независимы друг от друга. Однако им не обязательно быть независимыми, если используется многомерный критерий для одновременной проверки статистического значимости двух или более контрастов фактора повторных измерений. Это является причиной того, что методы многомерного дисперсионного анализа стали чаще использоваться для проверки значимости факторов одномерных повторных измерений с более чем 2 уровнями. Этот подход широко распространен, так как он, в общем случае, не требует предположения о сложной симметрии и предположения о сферичности.
Случаи, в которых подходмногомерного дисперсионного анализа не может быть использован. Существуют примеры (планы), когда подход многомерного дисперсионного анализа не может быть применен. Обычно это случаи, когда имеется небольшое количество субъектов в плане и много уровней в факторе повторных измерений. Тогда для проведения многомерного анализа может быть слишком мало наблюдений. Например, если имеется 12 субъектов, p = 4 фактора повторных измерений, и каждый фактор имеет k = 3 уровней. Тогда взаимодействие 4-х факторов будет “расходовать”(k -1)P = 2 4 = 16 степеней свободы. Однако имеется лишь 12 субъектов, следовательно, в этом примере многомерный тест не может быть проведен. Модуль Дисперсионный анализ самостоятельно обнаружит эти наблюдения и вычислит только одномерные критерии.
Различия в одномерных и многомерных результатах. Если исследование включает большое количество повторных измерений, могут возникнуть случаи, когда одномерный подход дисперсионного анализа к повторным измерениям дает результаты, сильно отличающиеся от тех, которые были получены при многомерном подходе. Это означает, что разности между уровнями соответствующих повторных измерений коррелированы по субъектам. Иногда этот факт представляет некоторый самостоятельный интерес.
Многомерный дисперсионный анализ и структурное моделирование уравнений
В последние годы моделирование структурных уравнений стало популярным, как альтернатива многомерному анализу дисперсии (см. например, Bagozzi and Yi, 1989; Bagozzi, Yi, and Singh, 1991; Cole, Maxwell, Arvey, and Salas, 1993). Этот подход позволяет проверять гипотезы не только о средних в разных группах, но так же и о корреляционных матрицах зависимых переменных. Например, можно ослабить предположения об однородности дисперсии и ковариаций и явно включить в модель для каждой группы дисперсии и ковариации ошибки. Модуль STATISTICA Моделирование структурными уравнениями (SEPATH ) (см. том III) позволяет проводить такой анализ.
Дисперсионный анализ
Курсовая работа по дисциплине: «Системный анализ»
Исполнитель студент гр. 99 ИСЭ-2 Жбанов В.В.
Оренбургский государственный университет
Факультет информационных технологий
Кафедра прикладной информатики
г. Оренбург-2003
Введение
Цель работы: познакомится с таким статистическим методом, как дисперсионный анализ.
Дисперсионный анализ (от латинского Dispersio – рассеивание) – статистический метод, позволяющий анализировать влияние различных факторов на исследуемую переменную. Метод был разработан биологом Р. Фишером в 1925 году и применялся первоначально для оценки экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость дисперсионного анализа для экспериментов в психологии, педагогике, медицине и др.
Целью дисперсионного анализа является проверка значимости различия между средними с помощью сравнения дисперсий. Дисперсию измеряемого признака разлагают на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации /1/.
При истинности нулевой гипотезы (о равенстве средних в нескольких группах наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии.
При проведении исследования рынка часто встает вопрос о сопоставимости результатов. Например, проводя опросы по поводу потребления какого-либо товара в различных регионах страны, необходимо сделать выводы, на сколько данные опроса отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели не имеет смысла и поэтому процедура сравнения и последующей оценки производится по некоторым усредненным значениям и отклонениям от этой усредненной оценки. Изучается вариация признака. За меру вариации может быть принята дисперсия. Дисперсия σ 2 – мера вариации, определяемая как средняя из отклонений признака, возведенных в квадрат.
На практике часто возникают задачи более общего характера – задачи проверки существенности различий средних выборочных нескольких совокупностей. Например, требуется оценить влияние различного сырья на качество производимой продукции, решить задачу о влиянии количества удобрений на урожайность с/х продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность нескольких совокупностей (дисперсии этих совокупностей одинаковы по предположению; если дисперсионный анализ покажет, что и математические ожидания одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности можно объединить в одну и тем самым получить о ней более полную информацию, следовательно, и более надежные выводы /2/.
1 Дисперсионный анализ
1.1 Основные понятия дисперсионного анализа
В процессе наблюдения за исследуемым объектом качественные факторы произвольно или заданным образом изменяются. Конкретная реализация фактора (например, определенный температурный режим, выбранное оборудование или материал) называется уровнем фактора или способом обработки. Модель дисперсионного анализа с фиксированными уровнями факторов называют моделью I, модель со случайными факторами - моделью II. Благодаря варьированию фактора можно исследовать его влияние на величину отклика. В настоящее время общая теория дисперсионного анализа разработана для моделей I.
В зависимости от количества факторов, определяющих вариацию результативного признака, дисперсионный анализ подразделяют на однофакторный и многофакторный.
Основными схемами организации исходных данных с двумя и более факторами являются:
Перекрестная классификация, характерная для моделей I, в которых каждый уровень одного фактора сочетается при планировании эксперимента с каждой градацией другого фактора;
Иерархическая (гнездовая) классификация, характерная для модели II, в которой каждому случайному, наудачу выбранному значению одного фактора соответствует свое подмножество значений второго фактора.
Если одновременно исследуется зависимость отклика от качественных и количественных факторов, т.е. факторов смешанной природы, то используется ковариационный анализ /3/.
Таким образом, данные модели отличаются между собой способом выбора уровней фактора, что, очевидно, в первую очередь влияет на возможность обобщения полученных экспериментальных результатов. Для дисперсионного анализа однофакторных экспериментов различие этих двух моделей не столь существенно, однако в многофакторном дисперсионном анализе оно может оказаться весьма важным.
При проведении дисперсионного анализа должны выполняться следующие статистические допущения: независимо от уровня фактора величины отклика имеют нормальный (Гауссовский) закон распределения и одинаковую дисперсию. Такое равенство дисперсий называется гомогенностью. Таким образом, изменение способа обработки сказывается лишь на положении случайной величины отклика, которое характеризуется средним значением или медианой. Поэтому все наблюдения отклика принадлежат сдвиговому семейству нормальных распределений.
Говорят, что техника дисперсионного анализа является "робастной". Этот термин, используемый статистиками, означает, что данные допущения могут быть в некоторой степени нарушены, но несмотря на это, технику можно использовать.
При неизвестном законе распределения величин отклика используют непараметрические (чаще всего ранговые) методы анализа.
В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Вариацию, обусловленную влиянием фактора, положенного в основу группировки, характеризует межгрупповая дисперсия σ 2 . Она является мерой вариации частных средних по группам вокруг общей средней и определяется по формуле:
 ,
,
где k - число групп;
n j - число единиц в j-ой группе;
Частная средняя по j-ой группе;
Общая средняя по совокупности единиц.
Вариацию, обусловленную влиянием прочих факторов, характеризует в каждой группе внутригрупповая дисперсия σ j 2 .
 .
.
Между общей дисперсией σ 0 2 , внутригрупповой дисперсией σ 2 и межгрупповой дисперсией существует соотношение:
σ 0 2 = + σ 2 .
Внутригрупповая дисперсия объясняет влияние неучтенных при группировке факторов, а межгрупповая дисперсия объясняет влияние факторов группировки на среднее значение по группе /2/.
1.2 Однофакторный дисперсионный анализ
Однофакторная дисперсионная модель имеет вид:
x ij = μ + F j + ε ij , (1)
где х ij – значение исследуемой переменой, полученной на i-м уровне фактора (i=1,2,...,т) c j-м порядковым номером (j=1,2,...,n);
F i – эффект, обусловленный влиянием i-го уровня фактора;
ε ij – случайная компонента, или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией переменой внутри отдельного уровня.
Основные предпосылки дисперсионного анализа:
Математическое ожидание возмущения ε ij равно нулю для любых i, т.е.
M(ε ij) = 0; (2)
Возмущения ε ij взаимно независимы;
Дисперсия переменной x ij (или возмущения ε ij) постоянна для
любых i, j, т.е.
D(ε ij) = σ 2 ; (3)
Переменная x ij (или возмущение ε ij) имеет нормальный закон
распределения N(0;σ 2).
Влияние уровней фактора может быть как фиксированным или систематическим (модель I), так и случайным (модель II).
Пусть, например, необходимо выяснить, имеются ли существенные различия между партиями изделий по некоторому показателю качества, т.е. проверить влияние на качество одного фактора - партии изделий. Если включить в исследование все партии сырья, то влияние уровня такого фактора систематическое (модель I), а полученные выводы применимы только к тем отдельным партиям, которые привлекались при исследовании. Если же включить только отобранную случайно часть партий, то влияние фактора случайное (модель II). В многофакторных комплексах возможна смешанная модель III, в которой одни факторы имеют случайные уровни, а другие – фиксированные.
Пусть имеется m партий изделий. Из каждой партии отобрано соответственно n 1 , n 2 , …, n m изделий (для простоты полагается, что n 1 =n 2 =...=n m =n). Значения показателя качества этих изделий представлены в матрице наблюдений:
x 11 x 12 … x 1n
x 21 x 22 … x 2n
………………… = (x ij), (i = 1,2, …, m; j = 1,2, …, n).
x m 1 x m 2 … x mn
Необходимо проверить существенность влияния партий изделий на их качество.
Если полагать, что элементы строк матрицы наблюдений – это численные значения случайных величин Х 1 ,Х 2 ,...,Х m , выражающих качество изделий и имеющих нормальный закон распределения с математическими ожиданиями соответственно a 1 ,а 2 ,...,а m и одинаковыми дисперсиями σ 2 , то данная задача сводится к проверке нулевой гипотезы Н 0: a 1 =a 2 =...= а m , осуществляемой в дисперсионном анализе.
Усреднение по какому-либо индексу обозначено звездочкой (или точкой) вместо индекса, тогда средний показатель качества изделий i-й партии, или групповая средняя для i-го уровня фактора, примет вид:
где i * – среднее значение по столбцам;
Ij – элемент матрицы наблюдений;
n – объем выборки.
А общая средняя:
 . (5)
. (5)
Сумма квадратов отклонений наблюдений х ij от общей средней ** выглядит так:
 2
=
2
= 2
+
2
+ 2
+
2
+
2 2
. (6)
2
. (6)
Q = Q 1 + Q 2 + Q 3 .
Последнее слагаемое равно нулю
так как сумма отклонений значений переменной от ее средней равна нулю, т.е.
 2
=0.
2
=0.
Первое слагаемое можно записать в виде:

В результате получается тождество:
Q = Q 1 + Q 2 , (8)
где  - общая, или полная, сумма квадратов отклонений;
- общая, или полная, сумма квадратов отклонений;
 - сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная) сумма квадратов отклонений;
- сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная) сумма квадратов отклонений;
 - сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений.
- сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая (остаточная) сумма квадратов отклонений.
В разложении (8) заключена основная идея дисперсионного анализа. Применительно к рассматриваемой задаче равенство (8) показывает, что общая вариация показателя качества, измеренная суммой Q, складывается из двух компонент – Q 1 и Q 2 , характеризующих изменчивость этого показателя между партиями (Q 1) и изменчивость внутри партий (Q 2), характеризующих одинаковую для всех партий вариацию под воздействием неучтенных факторов.
В дисперсионном анализе анализируются не сами суммы квадратов отклонений, а так называемые средние квадраты, являющиеся несмещенными оценками соответствующих дисперсий, которые получаются делением сумм квадратов отклонений на соответствующее число степеней свободы.
Число степеней свободы определяется как общее число наблюдений минус число связывающих их уравнений. Поэтому для среднего квадрата s 1 2 , являющегося несмещенной оценкой межгрупповой дисперсии, число степеней свободы k 1 =m-1, так как при его расчете используются m групповых средних, связанных между собой одним уравнением (5). А для среднего квадрата s22, являющегося несмещенной оценкой внутригрупповой дисперсии, число степеней свободы k2=mn-m, т.к. при ее расчете используются все mn наблюдений, связанных между собой m уравнениями (4).
Таким образом:
Если найти математические ожидания средних квадратов и , подставить в их формулы выражение xij (1) через параметры модели, то получится:
 (9)
(9)
т.к. с учетом свойств математического ожидания
 а
а

 (10)
(10)
Для модели I с фиксированными уровнями фактора F i (i=1,2,...,m) – величины неслучайные, поэтому
M(S) = 2 /(m-1) +σ 2 .
Гипотеза H 0 примет вид F i = F * (i = 1,2,...,m), т.е. влияние всех уровней фактора одно и то же. В случае справедливости этой гипотезы
M(S)= M(S)= σ 2 .
Для случайной модели II слагаемое F i в выражении (1) – величина случайная. Обозначая ее дисперсией

получим из (9)
![]() (11)
(11)
и, как и в модели I
В таблице 1.1 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.1 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии |
Сумма квадратов |
Число степеней свободы |
Средний квадрат |
Математическое ожидание среднего квадрата |
| Межгрупповая |
|
|
||
| Внутригрупповая |
|
|||
|
|



Гипотеза H 0 примет вид σ F 2 =0. В случае справедливости этой гипотезы
M(S)= M(S)= σ 2 .
В случае однофакторного комплекса как для модели I, так и модели II средние квадраты S 2 и S 2 , являются несмещенными и независимыми оценками одной и той же дисперсии σ 2 .
Следовательно, проверка нулевой гипотезы H 0 свелась к проверке существенности различия несмещенных выборочных оценок S и S дисперсии σ 2 .
Гипотеза H 0 отвергается, если фактически вычисленное значение статистики F = S/S больше критического F α: K 1: K 2 , определенного на уровне значимости α при числе степеней свободы k 1 =m-1 и k 2 =mn-m, и принимается, если F < F α: K 1: K 2 .
F- распределение Фишера (для x > 0) имеет следующую функцию плотности (для = 1, 2, ...; = 1, 2, ...):
где - степени свободы;
Г - гамма-функция.
Применительно к данной задаче опровержение гипотезы H 0 означает наличие существенных различий в качестве изделий различных партий на рассматриваемом уровне значимости.
Для вычисления сумм квадратов Q 1 , Q 2 , Q часто бывает удобно использовать следующие формулы:
 (12)
(12)
 (13)
(13)
 (14)
(14)
т.е. сами средние, вообще говоря, находить не обязательно.
Таким образом, процедура однофакторного дисперсионного анализа состоит в проверке гипотезы H 0 о том, что имеется одна группа однородных экспериментальных данных против альтернативы о том, что таких групп больше, чем одна. Под однородностью понимается одинаковость средних значений и дисперсий в любом подмножестве данных. При этом дисперсии могут быть как известны, так и неизвестны заранее. Если имеются основания полагать, что известная или неизвестная дисперсия измерений одинакова по всей совокупности данных, то задача однофакторного дисперсионного анализа сводится к исследованию значимости различия средних в группах данных /1/.
1.3 Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным дисперсионным анализом нет. Многофакторный анализ не меняет общую логику дисперсионного анализа, а лишь несколько усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. Таким образом, то новое, что вносит в анализ данных многофакторный дисперсионный анализ, касается в основном возможности оценить межфакторное взаимодействие. Тем не менее, по-прежнему остается возможность оценивать влияние каждого фактора в отдельности. В этом смысле процедура многофакторного дисперсионного анализа (в варианте ее компьютерного использования) несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие /3/.
Общая схема двухфакторного эксперимента, данные которого обрабатываются дисперсионным анализом имеет вид:
 |
Рисунок 1.1 – Схема двухфакторного эксперимента
Данные, подвергаемые многофакторному дисперсионному анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в рассматриваемой задаче о качестве различных m партий изделия изготавливались на разных t станках и требуется выяснить, имеются ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к задаче двухфакторного дисперсионного анализа.
Все данные представлены в таблице 1.2, в которой по строкам - уровни A i фактора А, по столбцам - уровни B j фактора В, а в соответствующих ячейках, таблицы находятся значения показателя качества изделий x ijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 1.2 – Показатели качества изделий
| x 11l ,…,x 11k |
x 12l ,…,x 12k |
x 1jl ,…,x 1jk |
x 1ll ,…,x 1lk |
|||
| x 2 1l ,…,x 2 1k |
x 22l ,…,x 22k |
x 2jl ,…,x 2jk |
x 2ll ,…,x 2lk |
|||
| x i1l ,…,x i1k |
x i2l ,…,x i2k |
x ijl ,…,x ijk |
x jll ,…,x jlk |
|||
| x m1l ,…,x m1k |
x m2l ,…,x m2k |
x mjl ,…,x mjk |
x mll ,…,x mlk |
Двухфакторная дисперсионная модель имеет вид:
x ijk =μ+F i +G j +I ij +ε ijk , (15)
где x ijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
F i - эффект, обусловленный влиянием i-го уровня фактора А;
G j - эффект, обусловленный влиянием j-го уровня фактора В;
I ij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели (15);
ε ijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что ε ijk имеет нормальный закон распределения N(0; с 2), а все математические ожидания F * , G * , I i * , I * j равны нулю.
Групповые средние находятся по формулам:
В ячейке:
по строке:

по столбцу:

общая средняя:

В таблице 1.3 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.3 – Базовая таблица дисперсионного анализа
| Компоненты дисперсии |
Сумма квадратов |
Число степеней свободы |
Средние квадраты |
| Межгрупповая (фактор А) |
|
||
| Межгрупповая (фактор B) |
|
||
| Взаимодействие |
|
|
|
| Остаточная |
|
|
|
|
|






Проверка нулевых гипотез HA, HB, HAB об отсутствии влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется сравнением отношений , , (для модели I с фиксированными уровнями факторов) или отношений , , (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера – Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
Если n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и средний квадрат , так как в этом случае не может быть речи о взаимодействии факторов.
С точки зрения техники вычислений для нахождения сумм квадратов Q 1 , Q 2 , Q 3 , Q 4 , Q целесообразнее использовать формулы:




Q 3 = Q – Q 1 – Q 2 – Q 4 .
Отклонение от основных предпосылок дисперсионного анализа - нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) - не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы /1/.
2 Применение дисперсионного анализа в различных процессах и исследованиях
2.1 Использование дисперсионного анализа при изучении миграционных процессов
Миграция - сложное социальное явление, во многом определяющее экономическую и политическую стороны жизни общества. Исследование миграционных процессов связано с выявлением факторов заинтересованности, удовлетворенности условиями труда, и оценкой влияния полученных факторов на межгрупповое движение населения.
λ ij =c i q ij a j ,
где λ ij – интенсивность переходов из исходной группы i (выхода) в новую j (входа);
c i – возможность и способности покинуть группу i (c i ≥0);
q ij – привлекательность новой группы по сравнению с исходной (0≤q ij ≤1);
a j – доступность группы j (a j ≥0).
ν ij ≈ n i λ ij =n i c i q ij a j . (16)
На практике для отдельного человека вероятность p перехода в другую группу мала, а численность рассматриваемой группы n велика. В этом случае действует закон редких событий, то есть пределом ν ij является распределение Пуассона с параметром μ=np:
![]() .
.
С ростом μ распределение приближается к нормальному. Преобразованную же величину √ν ij можно считать нормально распределенной.
Если прологарифмировать выражение (16) и сделать необходимые замены переменных, то можно получить модель дисперсионного анализа:
ln√ν ij =½lnν ij =½(lnn i +lnc i +lnq ij +lna j)+ε ij ,
X i,j =2ln√ν ij -lnn i -lnq ij ,
X i,j =C i +A j +ε.
Значения C i и A j позволяют получить модель двухфакторного дисперсионного анализа с одним наблюдением в клетке. Обратным преобразованием из C i и A j вычисляются коэффициенты c i и a j .
При проведении дисперсионного анализа в качестве значений результативного признака Y следует взять величины:
Х=(Х 1,1 +Х 1,2 +:+Х mi,mj)/mimj,
где mimj- оценка математического ожидания Х i,j ;
Х mi и Х mj - соответственно количество групп выхода и входа.
Уровнями фактора I будут mi групп выхода, уровнями фактора J - mj групп входа. Предполагается mi=mj=m. Встает задача проверки гипотез H I
и H J
о равенствах математических ожиданий величины Y при уровнях I i
и при уровнях J j
, i,j=1,…,m. Проверка гипотезы H I
основывается на сравнении величин несмещенных оценок дисперсии s I
2
и s o
2
. Если гипотеза H I
верна, то величина F (I)
= s I
2
/s o
2
имеет распределение Фишера с числами степеней свободы k 1
=m-1 и k 2
=(m-1)(m-1). Для заданного уровня значимости α находится правосторонняя критическая точка x пр,α
кр. Если числовое значение F (I)
чис
величины попадает в интервал (x пр,α
кр, +∞), то гипотеза H I
отвергается и считается, что фактор I влияет на результативный признак. Степень этого влияния по результатам наблюдений измеряется выборочным коэффициентом детерминации, который показывает, какая доля дисперсии результативного признака в выборке обусловлена влиянием на него фактора I. Если же F (I)
чис
2.2 Принципы математико-статистического анализа данных медико-биологических исследований
В зависимости от поставленной задачи, объема и характера материала, вида данных и их связей находится выбор методов математической обработки на этапах как предварительного (для оценки характера распределения в исследуемой выборке), так и окончательного анализа в соответствии с целями исследования. Крайне важным аспектом является проверка однородности выбранных групп наблюдения, в том числе контрольных, что может быть проведено или экспертным путем, или методами многомерной статистики (например, с помощью кластерного анализа). Но первым этапом является составление вопросника, в котором предусматривается стандартизованное описание признаков. В особенности при проведении эпидемиологических исследований, где необходимо единство в понимании и описании одних и тех же симптомов разными врачами, включая учет диапазонов их изменений (степени выраженности). В случае существенности различий в регистрации исходных данных (субъективная оценка характера патологических проявлений различными специалистами) и невозможности их приведения к единому виду на этапе сбора информации, может быть затем осуществлена так называемая коррекция ковариант, которая предполагает нормализацию переменных, т.е. устранение ненормальностей показателей в матрице данных. "Согласование мнений" осуществляется с учетом специальности и опыта врачей, что позволяет затем сравнивать полученные ими результаты обследования между собой. Для этого могут использоваться многомерный дисперсионный и регрессионный анализы. Признаки могут быть как однотипными, что бывает редко, так и разнотипными. Под этим термином понимается их различная метрологическая оценка. Количественные или числовые признаки - это замеренные в определенной шкале и в шкалах интервалов и отношений (I группа признаков). Качественные, ранговые или балльные используются для выражения медицинских терминов и понятий не имеющих цифровых значений (например, тяжесть состояния) и замеряются в шкале порядка (II группа признаков). Классификационные или номинальные (например, профессия, группа крови) - это замеренные в шкале наименований (III группа признаков). Во многих случаях делается попытка анализа крайне большого числа признаков, что должно способствовать повышению информативности представленной выборки. Однако выбор полезной информации, то есть осуществление отбора признаков является операцией совершенно необходимой, поскольку для решения любой классификационной задачи должны быть отобраны сведения, несущие полезную для данной задачи информацию. В случае, если это не осуществлено по каким-то причинам исследователем самостоятельно или отсутствуют достаточно обоснованные критерии для снижения размерности пространства признаков по содержательным соображениям, борьба с избыточностью информации осуществляется уже формальными методами путем оценки информативности. Дисперсионный анализ позволяет определить влияние разных факторов (условий) на исследуемый признак (явление), что достигается путем разложения совокупной изменчивости (дисперсии, выраженной в сумме квадратов отклонений от общего среднего) на отдельные компоненты, вызванные влиянием различных источников изменчивости. С помощью дисперсионного анализа исследуются угрозы заболевания при наличии факторов риска. Концепция относительного риска рассматривает отношение между пациентами с определенной болезнью и не имеющими ее. Величина относительного риска дает возможность определить, во сколько раз увеличивается вероятность заболеть при его наличии, что может быть оценено с помощью следующей упрощенной формулы: где a - наличие признака в исследуемой группе; b - отсутствие признака в исследуемой группе; c - наличие признака в группе сравнения (контрольной); d - отсутствие признака в группе сравнения (контрольной). Показатель атрибутивного риска (rA) служит для оценки доли заболеваемости, связанной с данным фактором риска: где Q - частота признака, маркирующего риск, в популяции; r" - относительный риск. Выявление факторов, способствующих возникновению (проявлению) заболевания, т.е. факторов риска может осуществляться различными способами, например, путем оценки информативности с последующим ранжированием признаков, что однако не указывает на совокупное действие отобранных параметров, в отличие от применения регрессионного, факторного анализов, методов теории распознавания образов, которые дают возможность получать "симптомокомплексы" риск-факторов. Кроме того, более сложные методы позволяют анализировать и непрямые связи между факторами риска и заболеваниями /5/. 2.3 Биотестирование почвы
Многообразные загрязняющие вещества, попадая в агроценоз, могут претерпевать в нем различные превращения, усиливая при этом свое токсическое действие. По этой причине оказались необходимыми методы интегральной оценки качества компонентов агроценоза. Исследования проводили на базе многофакторного дисперсионного анализа в 11-ти польном зернотравянопропашном севообороте. В опыте изучалось влияние следующих факторов: плодородие почвы (А), система удобрений (В), система защиты растений (С). Плодородие почвы, система удобрений и система защиты растений изучались в дозах 0, 1, 2 и 3. Базовые варианты были представлены следующими комбинациями: 000 - исходный уровень плодородия, без применения удобрений и средств защиты растений от вредителей, болезней и сорняков; 111 - средний уровень плодородия почвы, минимальная доза удобрения, биологическая защита растений от вредителей и болезней; 222 - исходный уровень плодородия почвы, средняя доза удобрений, химическая защита растений от сорняков; 333 - высокий уровень плодородия почвы, высокая доза удобрений, химическая защита растений от вредителей и болезней. Изучались варианты, где представлен только один фактор: 200 – плодородие: 020 – удобрения; 002 - средства защиты растений. А также варианты с различным сочетанием факторов - 111, 131, 133, 022, 220, 202, 331, 313, 311. Целью исследования являлось изучение торможения хлоропластов и коэффициента мгновенного роста, как показателей загрязнения почвы, в различных вариантах многофакторного опыта. Торможение фототаксиса хлоропластов ряски малой исследовали в различных горизонтах почвы: 0-20, 20-40 см. Анализ изменчивости фототаксиса в разных вариантах опыта показал достоверное влияние каждого из факторов (плодородия почвы, системы удобрений и системы защиты растений). Доля в общей дисперсии плодородия почвы составила 39,7%, системы удобрений - 30,7%, системы защиты растений - 30,7 %. Для исследования совокупного влияния факторов на торможение фототаксиса хлоропластов использовались различные сочетания вариантов опыта: в первом случае - 000, 002, 022, 222, 220, 200, 202, 020, во втором случае - 111, 333, 331, 313, 133, 311, 131. Результаты двухфакторного дисперсионного анализа свидетельствуют о достоверном влиянии взаимодействующих системы удобрений и системы защиты растений на различия в фототаксисе для первого случая (доля в общей дисперсии составила 10,3%). Для второго случая обнаружено достоверное влияние взаимодействующих плодородия почвы и системы удобрений (53,2%). Трехфакторный дисперсионный анализ показал в первом случае достоверное влияние взаимодействия всех трех факторов. Доля в общей дисперсии составила 47,9%. Коэффициент мгновенного роста исследовали в различных вариантах опыта 000, 111, 222, 333, 002, 200, 220. Первый этап тестирования - до внесения гербицидов на посевах озимой пшеницы (апрель), второй этап - после внесения гербицидов (май) и последний - на момент уборки (июль). Предшетвенники - подсолнечник и кукуруза на зерно. Появление новых листецов наблюдали после короткой лаг-фазы с периодом суммарного удвоения сырой массы 2 - 4 суток. В контроле и в каждом варианте на основании полученных результатов рассчитывали коэффициент мгновенного роста популяции r и далее рассчитывали время удвоения численности листецов (t удв). t удв
=ln2/r. Расчет этих показателей был проведен в динамике с анализом почвенных образцов. Анализ данных показал, что время удвоения популяции рясок до обработки почвы было наименьшем по сравнению с данными после обработки и на момент уборки. В динамике наблюдений больший интерес вызывает отклик почвы после внесения гербицида и на момент уборки. Прежде всего взаимодействие с удобрениями и уровнем плодородия. Подчас получить прямой отклик на внесение химических препараратов может быть осложнено взаимодействием препарата с удобрениями, как органическими, так и минеральными. Полученные данные позволили проследить динамику отклика вносимых препаратов, во всех вариантах с химическими средствами защиты, где отмечается приостановка роста индикатора. Данные однофакторного дисперсионного анализа показали достоверное влияние каждого показателя на темпы роста ряски малой на первом этапе. На втором этапе эффект различий по плодородию почвы составил 65,0 %, по системе удобрений и системе защиты растений - по 65,0%. Факторы показали достоверные различия среднего по коэффициенту мгновенного роста варианта 222 и вариантов 000, 111, 333. На третьем этапе доля в общей дисперсии плодородия почвы составила 42,9%, системы удобрений и системы защиты растений - по 42,9%. Отмечено достоверное различие по средним значениям вариантов 000 и 111, вариантов 333 и 222. Исследуемые образцы почвы с вариантов полевого мониторинга отличаются друг от друга по показателю торможение фототаксиса. Отмечено влияние факторов плодородия, система удобрений и средства защиты растений с долями 30,7 и 39,7% при однофакторном анализе, при двух факторном и трехфакторном - зарегистрировали совместное влияние факторов. Анализ результатов опыта показал незначительные различия между горизонтами почвы по показателю - торможение фототаксиса. Отличия отмечены по средним значениям. На всех вариантах, где имеются средства защиты растений наблюдается изменения положения хлоропластов и приостановка роста ряски малой /6/. 2.4 Грипп вызывает повышенную выработку гистамина
Исследователи из детской больницы в Питсбурге (США) получили первые доказательства того, что при острых респираторных вирусных инфекциях повышается уровень гистамина. Несмотря на то, что и раньше предполагалось, что гистамин играет определенную роль в возникновении симптомов острых респираторных инфекциях верхних дыхательных путей. Ученых интересовало, почему многие люди применяют для самолечения «простудных» заболеваний и насморка антигистаминные препараты, которые во многих странах входят в категорию OTC, т.е. доступны без рецепта врача. Целью проведенного исследования было определить, повышается ли продукция гистамина при экспериментальной инфекции, вызванной вирусом гриппа А. 15 здоровым добровольцам интраназально ввели вирус гриппа А, а затем наблюдали за развитием инфекции. Ежедневно в течение заболевания у добровольцев собиралась утренняя порция мочи, а затем проводилось определение гистамина и его метаболитов и рассчитывалось общее количество гистамина и его метаболитов, выделенных за сутки. Заболевание развилось у всех 15 добровольцев. Дисперсионный анализ подтвердил достоверно более высокий уровень гистамина в моче на 2-5 сутки вирусной инфекции (p<0,02) - период, когда симптомы «простуды» наиболее выражены. Парный анализ показал, что наиболее значительно уровень гистамина повышается на 2 день заболевания. Кроме этого, оказалось, что суточное количество гистамина и его метаболитов в моче при гриппе примерно такое же, как и при обострении аллергического заболевания. Результаты данного исследования служат первыми прямыми доказательствами того, что уровень гистамина повышается при острых респираторных инфекциях /7/. Дисперсионный анализ в химии
Дисперсионный анализ – совокупность методов определения дисперсности, т. е. характеристики размеров частиц в дисперсных системах. Дисперсионный анализ включает различные способы определения размеров свободных частиц в жидких и газовых средах, размеров каналов-пор в тонкопористых телах (в этом случае вместо понятия дисперсности используют равнозначное понятие пористости), а также удельной поверхности. Одни из методов дисперсионного анализа позволяют получать полную картину распределения частиц по размерам (объёмам), а другие дают лишь усреднённую характеристику дисперсности (пористости). К первой группе относятся, например, методы определения размеров отдельных частиц непосредственным измерением (ситовой анализ, оптическая и электронная микроскопия) или по косвенным данным: скорости оседания частиц в вязкой среде (седиментационный анализ в гравитационном поле и в центрифугах), величине импульсов электрического тока, возникающих при прохождении частиц через отверстие в непроводящей перегородке (кондуктометрический метод). Вторая группа методов объединяет оценку средних размеров свободных частиц и определение удельной поверхности порошков и пористых тел. Средний размер частиц находят по интенсивности рассеянного света (нефелометрия), с помощью ультрамикроскопа, методами диффузии и т.д., удельную поверхность - по адсорбции газов (паров) или растворённых веществ, по газопроницаемости, скорости растворения и др. способами. Ниже приведены границы применимости различных методов дисперсионного анализа (размеры частиц в метрах): Ситовой анализ – 10 -2
-10 -4 Седиментационный анализ в гравитационном поле – 10 -4
-10 -6 Кондуктометрический метод – 10 -4
-10 -6 Микроскопия – 10 -4
-10 -7 Метод фильтрации – 10 -5
-10 -7 Центрифугирование – 10 -6
-10 -8 Ультрацентрифугирование – 10 -7
-10 -9 Ультрамикроскопия – 10 -7
-10 -9 Нефелометрия – 10 -7
-10 -9 Электронная микроскопия – 10 -7
-10 -9 Метод диффузии – 10 -7
-10 -10 Дисперсионный анализ широко используют в различных областях науки и промышленного производства для оценки дисперсности систем (суспензий, эмульсий, золей, порошков, адсорбентов и т.д.) с величиной частиц от нескольких миллиметров (10 -3
м) до нескольких нанометров (10 -9
м) /8/. 2.6 Использование прямого преднамеренного внушения в бодрствующем состоянии в методике воспитания физических качеств
Физическая подготовка – основополагающая сторона спортивной тренировки, так как в большей мере, чем другие стороны подготовки, характеризуется физическими нагрузками, воздействующими на морфофункциональные свойства организма. От уровня физической подготовленности зависят успешность технической подготовки, содержание тактики спортсмена, реализация личностных свойств в процессе тренировок и состязаний. Одной из основных задач физической подготовки является воспитание физических качеств. В связи с этим возникает необходимость в разработке педагогических средств и методов, позволяющих учитывать возрастные особенности юных спортсменов, сохраняющих их здоровье, не требующих дополнительных затрат времени и в то же время стимулирующих рост физических качеств и, как следствие, - спортивного мастерства. Использование вербального гетеровоздействия в тренировочном процессе в группах начальной подготовки - одно из перспективных направлений исследований по данной проблеме. Анализ теории и практики реализации внушающего вербального гетеровоздействия выявил основные противоречия: Доказанность эффективного использования специфических методов вербального гетеровоздействия в тренировочном процессе и практическую невозможность их использования тренером; Признание прямого преднамеренного внушения (далее ППВ) в бодрствующем состоянии как одного из основных методов вербального гетеровоздействия в педагогической деятельности тренера и отсутствие теоретического обоснования методических особенностей его применения в спортивной подготовке, и в частности в процессе воспитания физических качеств. В связи с выявленными противоречиями и недостаточной разработанностью проблема использования системы методов вербального гетеровоздействия в процессе воспитания физических качеств спортсменов предопределила цель исследования - разработать рациональные целенаправленные методики ППВ в бодрствующем состоянии, способствующие совершенствованию процесса воспитания физических качеств на основе оценки психического состояния, проявления и динамики физических качеств дзюдоистов групп начальной подготовки. С целью апробации и определения эффективности экспериментальных методик ППВ при воспитании физических качеств дзюдоистов был проведен сравнительный педагогический эксперимент, в котором приняли участие четыре группы – три экспериментальных и одна контрольная. В первой экспериментальной группе (ЭГ) использовалась методика ППВ М1, во второй - методика ППВ М2, в третьей - методика ППВ М3. В контрольной группе (КГ) методики ППВ не применялись. Для определения эффективности педагогического воздействия методик ППВ в процессе воспитания у дзюдоистов физических качеств был проведен однофакторный дисперсионный анализ. Степень влияния методики ППВ M1 в процессе воспитания: Выносливости: а) после третьего месяца составила 11,1%; Скоростных способностей: а) после первого месяца - 16,4%; б) после второго - 26,5%; в) после третьего - 34,8%; а) после второго месяца - 26, 7%; б) после третьего - 35,3%; Гибкости: а) после третьего месяца - 20,8%; а) после второго месяца основного педагогического эксперимента степень влияния методики составила 6,4%; б) после третьего - 10,2%. Следовательно, существенные изменения в показателях уровня развития физических качеств с использованием методики ППВ М1 обнаружены в скоростных способностях и силе, степень влияния методики в данном случае наибольшая. Наименьшая степень влияния методики обнаружена в процессе воспитания выносливости, гибкости, координационных способностей, что дает основание говорить о недостаточной эффективности использования методики ППВ М1 при воспитании указанных качеств. Степень влияния методики ППВ M2 в процессе воспитания: Выносливости а) после первого месяца эксперимента - 12,6%; б) после второго - 17,8%; в) после третьего - 20,3%. Скоростных способностей: а) после третьего месяца тренировочных занятий - 28%. а) после второго месяца - 27,9%; б) после третьего - 35,9%. Гибкости: а) после третьего месяца тренировочных занятий - 14,9%; Координационных способностей - 13,1%. Полученный результат однофакторного дисперсионного анализа данной ЭГ позволяет сделать вывод о том, что методика ППВ М2 наиболее результативна при воспитании выносливости и силы. Менее эффективна она в процессе воспитания гибкости, скоростных и координационных способностей. Степень влияния методики ППВ М3 в процессе воспитания: Выносливости: а) после первого месяца эксперимента 16,8%; б) после второго - 29,5%; в) после третьего - 37,6%. Скоростных способностей: а) после первого месяца - 26,3%; б) после второго - 31,3%; в) после третьего - 40,9%. а) после первого месяца - 18,7%; б) после второго - 26,7%; в) после третьего - 32,3%. Гибкости: а) после первого - изменений нет; б) после второго - 16,9%; в) после третьего - 23,5%. Координационных способностей: а) после первого месяца изменений нет; б) после второго - 23,8%; в) после третьего - 91% . Таким образом, однофакторный дисперсионный анализ показал, что использование методики ППВ М3 в подготовительном периоде наиболее эффективно в процессе воспитания физических качеств, так как наблюдается увеличение степени ее влияния после каждого месяца педагогического эксперимента /9/. 2.7 Купирование острой психотической симптоматики у больных шизофренией атипичным нейролептиком
Цель исследования сводилась к изучению возможности применения рисполепта для купирования острых психозов у больных с диагнозом шизофрении (параноидный тип по МКБ-10) и шизоаффективного расстройства. При этом в качестве основного изучаемого критерия использовался показатель длительности сохранения психотической симптоматики в условиях фармакотерапии рисполептом (основная группа) и классическими нейролептиками. Основные задачи исследования сводились к определению показателя длительности психоза (так называемый нетто-психоз), под которым понималось сохранение продуктивной психотической симптоматики с момента начала применения нейролептиков, выраженное в днях. Данный показатель был рассчитан отдельно для группы, принимавшей рисперидон, и отдельно для группы, принимавшей классические нейролептики. Наряду с этим была поставлена задача по определению доли редукции продуктивной симптоматики под влиянием рисперидона в сравнении с классическими нейролептиками в разные сроки терапии. В общей сложности изучены 89 больных (42 мужчины и 47 женщин) с острой психотической симптоматикой в рамках параноидной формы шизофрении (49 больных) и шизоаффективного расстройства (40 больных). Первый эпизод и длительность заболевания до 1 года были зарегистрированы у 43 больных, тогда как в остальных случаях на момент исследования отмечались последующие эпизоды шизофрении при длительности заболевания свыше 1 года. Терапию рисполептом получали 29 человек, среди которых с так называемым первым эпизодом было 15 больных. Терапию классическими нейролептиками получали 60 человек, среди которых с первым эпизодом было 28 человек. Доза рисполепта варьировала в диапазоне от 1 до 6 мг в сутки и в среднем составляла 4±0,4 мг/сут. Рисперидон принимали исключительно внутрь после еды один раз в сутки в вечернее время. Терапия классическими нейролептиками включала применение трифлуоперазина (трифтазина) в суточной дозе до 30 мг внутримышечно, галоперидола в суточной дозе до 20 мг внутримышечно, триперидола в суточной дозе до 10 мг внутрь. Подавляющее большинство больных принимало классические нейролептики в виде монотерапии в течение первых двух недель, после чего переходили в случае необходимости (при сохранении бредовой, галлюцинаторной или другой продуктивной симптоматики) к сочетанию нескольких классических нейролептиков. При этом в качестве основного препарата оставался нейролептик с выраженным элективным антибредовым и антигаллюцинаторным аффектом (например, галоперидол или трифтазин), к нему присоединяли в вечернее время препарат с отчетливым гипноседативным эффектом (аминазин, тизерцин, хлорпротиксен в дозах до 50-100 мг/сут). В группе, принимавшей классические нейролептики, был предусмотрен прием корректоров холинолитического ряда (паркопан, циклодол) в дозах до 10-12 мг/сут. Корректоры назначались в случае появления отчетливых побочных экстрапирамидных эффектов в виде острых дистоний, лекарственного паркинсонизма и акатизии. В таблице 2.1 представлены данные по длительности психоза при лечении рисполептом и классическими нейролептиками. Таблица 2.1 – Длительность психоза ("нетто-психоз") при лечении рисполептом и классическими нейролептиками Как следует из данных таблицы, при сравнении длительности психоза при терапии классическими нейролептиками и рисперидоном наблюдается практически двукратное сокращение продолжительности психотической симптоматики под влиянием рисполепта. Существенно, что на данную величину продолжительности психоза не влияли ни факторы порядкового номера приступов, ни характер картины ведущего синдрома. Иначе говоря, длительность психоза определялась исключительно фактором терапии, т.е. зависела от типа применяемого препарата безотносительно порядкового номера приступа, продолжительности заболевания и характера ведущего психопатологического синдрома. С целью подтверждения полученных закономерностей был проведен двухфакторный дисперсионный анализ. При этом поочередно учитывалось взаимодействие фактора терапии и порядкового номера приступа (1-й этап) и взаимодействие фактора терапии и характера ведущего синдрома (2-й этап). Результаты дисперсионного анализа подтвердили влияние фактора терапии на величину длительности психоза (F=18,8) при отсутствии влияния фактора номера приступа (F=2,5) и фактора типа психопатологического синдрома (F=1,7). Немаловажно, что совместное влияние фактора терапии и номера приступа на величину длительности психоза также отсутствовало, равно как и совместное влияние фактора терапии и фактора психопатологического синдрома. Таким образом, результаты дисперсионного анализа подтвердили влияние только фактора применяемого нейролептика. Рисполепт однозначно приводил к сокращению длительности психотической симптоматики по сравнению с традиционными нейролептиками примерно в 2 раза. Принципиально, что этот эффект был достигнут, несмотря на пероральный прием рисполепта, тогда как классические нейролептики применялись у большей части больных парентерально /10/. 2.8 Снование фасонной пряжи с ровничным эффектом
В Костромском Государственном технологическом университете разработана новая структура фасонной нити с переменными геометрическими параметрами. В связи с этим возникает проблема переработки фасонной пряжи в приготовительном производстве. Данное исследование посвящалось процессу снования по вопросам: выбор типа натяжного устройства, дающего минимальный разброс натяжения и выравнивание натяжения, нитей различной линейной плотности по ширине сновального вала. Объект исследования – льняная фасонная нить четырех вариантов линейной плотности от 140 до 205 текса. Исследовалась работа натяжных приборов трех типов: фарфорового шайбового, двухзонного НС-1П и однозонного НС-1П. Экспериментальное исследование натяжения снующихся нитей производилось на сновальной машине СП-140-3Л. Скорость снования, масса тормозных шайб соответствовали технологическим параметрам снования пряжи. Для исследования зависимости натяжения фасонной нити от геометрических параметров при сновании проведен анализ для двух факторов: X 1
- диаметр эффекта, X 2
- длина эффекта. Выходными параметрами являются натяжение Y 1
и колебание натяжения Y 2
. Полученные уравнения регрессии адекватны экспериментальным данным при уровне значимости 0,95, так как расчетный критерий Фишера для всех уравнений меньше табличного. Для определения степени влияния факторов Х 1
и Х 2
на параметры Y 1
и Y 2
проведен дисперсионный анализ, который показал, что большее влияние на уровень и колебание натяжения оказывает диаметр эффекта. Сравнительный анализ полученных тензограмм показал, что минимальный разброс натяжения при сновании данной пряжи обеспечивает двухзонный натяжной прибор НС-1П. Установлено, что с ростом линейной плотности от 105 до 205 текс прибор НС-1П дает приращение уровня натяжения лишь на 23%, в то время как фарфоровый шайбовый - на 37 %, однозонный НС-1П на 53 %. При формировании сновальных валов, включающих в себя фасонные и "гладкие" нити, необходима индивидуальная настройка натяжного прибора традиционным методом /11/. 2.9 Сопутствующая патология при полной утрате зубов у лиц пожилого и старческого возраста
Изучены эпидемиологически полная утрата зубов и сопутствующая патология пожилого населения, проживающего в домах престарелых на территории Чувашии. Обследование проводилось путем стоматологического осмотра и заполнения статистических карт 784 человек. Результаты анализа показали высокий процент полной утраты зубов, усугубляющейся общей патологией организма. Это характеризует осмотренную категорию населения как группу повышенного стоматологического риска и требует пересмотра всей системы стоматологического обслуживания их. У пожилых людей уровень заболеваемости в два раза, а в старческом возрасте в шесть раз выше в сравнении с уровнем заболеваемости лиц более молодых возрастов. Основными заболеваниями лиц пожилого и старческого возраста являются болезни органов кровообращения, нервной системы и органов чувств, органов дыхания, органов пищеварения, костей и органов движения, новообразования и травмы. Цель исследования – разработка и получение информации о сопутствующих заболеваниях, эффективности зубопротезирования и нуждаемости в ортопедическом лечении лиц пожилого и старческого возраста с полной потерей зубов. Всего было обследовано 784 человека в возрасте от 45 до 90 лет. Соотношение женщин и мужчин 2,8:1. Оценка статистической связи с помощью коэффициента корреляции рангов Пирсона позволила установить взаимное влияние отсутствия зубов на сопутствующую заболеваемость с уровнем надежности р=0,0005. Пожилые пациенты с полной потерей зубов страдают болезнями, свойственными старости, а именно, атеросклерозом сосудов головного мозга и гипертонической болезнью. Дисперсионный анализ показал, что в изучаемых условиях определяющую роль играет специфика болезни. Роль нозологических форм в различных возрастных периодах колеблется в пределах 52-60 %. Наибольшее статистически достоверное влияние на отсутствие зубов оказывают болезни органов пищеварения и сахарный диабет. В целом группа больных в возрасте 75-89 лет характеризовалась большим числом патологических заболеваний. В этом исследовании было проведено сравнительное изучение частоты распространения сопутствующей патологии среди пациентов с полной утратой зубов пожилого и старческого возраста, проживающих в домах престарелых. Выявлен высокий процент отсутствия зубов среди лиц этой возрастной категории. У пациентов с полной адентией наблюдается характерная для этого возраста сопутствующая патология. Наиболее часто среди обследованных лиц встречались атеросклероз и гипертония. Статистически достоверно влияние на состояние полости рта таких заболеваний, как болезни желудочно-кишечного тракта и сахарный диабет, доля остальных нозоологических форм оказалась в пределах 52-60 %. Применение дисперсионного анализа не подтвердили значимой роли пола и местожительства на показатели состояния полости рта. Таким образом, в заключении следует отметить, что анализ распределения сопутствующих заболеваний у лиц с полным отсутствием зубов в пожилом и старческом возрасте показал, что эта категория граждан относится к особой группе населения, которая должна получать адекватную стоматологическую помощь в рамках существующих стоматологических систем /12/. 3 Дисперсионный анализ в контексте статистических методов
Статистические методы анализа – это методология измерения результатов деятельности человека, то есть перевода качественных характеристик в количественные. Основные этапы при проведении статистического анализа: Составление плана сбора исходных данных - значений входных переменных (X 1
,...,X p), числа наблюдений n. Этот этап выполняется при активном планировании эксперимента. Получение исходных данных и ввод их в компьютер. На этом этапе формируются массивы чисел (x 1i
,..., x pi
; y 1i
,..., y qi), i=1,..., n, где n - объем выборки. Первичная статистическая обработка данных. На данном этапе формируется статистическое описание рассматриваемых параметров: а)
построение и анализ статистических зависимостей; б) корреляционный анализ предназначен для оценивания значимости влияния факторов (X 1
,...,X p) на отклик Y; в) дисперсионный анализ используется для оценивания влияния на отклик Y неколичественных факторов (X 1
,...,X p) с целью выбора среди них наиболее важных; г) регрессионный анализ предназначен для определения аналитической зависимости отклика Y от количественных факторов X; Интерпретация результатов в терминах поставленной задачи /13/. В таблице 3.1 приведены статистические методы, с помощью которых решаются аналитические задачи. В соответствующих ячейках таблицы находятся частоты применения статистических методов: Метка «-» - метод не применяется; Метка «+» - метод применяется; Метка «++» - метод широко применяется; Метка «+++» - применение метода представляет особый интерес /14/. Дисперсионный анализ подобно t-критерию Стьюдента, позволяет оценить различия между выборочными средними; однако, в отличие от t-критерия, в нем нет ограничений на количество сравниваемых средних. Таким образом, вместо того, чтобы поставить вопрос о различии двух выборочных средних, можно оценить, различаются ли два, три четыре, пять или k средних. Дисперсионный анализ позволяет иметь дело с двумя или более независимыми переменными (признаками, факторами) одновременно, оценивая не только эффект каждой из них по отдельности, но и эффекты взаимодействия между ними /15/. Таблица 3.1 – Применение статистических методов при решении аналитических задач Аналитические задачи, возникающие в сфере бизнеса, финансов и управления Методы описательной статистики Методы поверки статисти-ческих гипотез Методы регресси-онного анализа Методы дисперси-онного анализа Методы много-мерного анализа Методы дискриминантного анализа кластер-ного Методы анализа выжива-емости Методы анализа и прогноза временных рядов Задачи горизонталь-ного (временного) анализа Задачи вертикального (структурного) анализа Задачи трендового анализа и прогноза Задачи анализа относительных показателей Задачи сравнительного (пространствен-ного) анализа Задачи факторного анализа К большинству сложных систем применим принцип Парето, согласно которому 20 % факторов определяют свойства системы на 80 %. Поэтому первоочередной задачей исследователя имитационной модели является отсеивание несущественных факторов, позволяющее уменьшить размерность задачи оптимизации модели. Анализ дисперсии оценивает отклонение наблюдений от общего среднего. Затем вариация разбивается на части, каждая из которых имеет свою причину. Остаточная часть вариации, которую не удается связать с условиями эксперимента, считается его случайной ошибкой. Для подтверждения значимости используется специальный тест - F-статистика. Дисперсионный анализ определяет, есть ли эффект. Регрессионный анализ позволяет прогнозировать отклик (значение целевой функции) в некоторой точке пространства параметров. Непосредственной задачей регрессионного анализа является оценка коэффициентов регрессии /16/. Слишком большая размерность выборок затрудняет проведение статистических анализов, поэтому имеет смысл уменьшить размер выборки. Применив дисперсионный анализ можно выявить значимость влияния различных факторов на исследуемую переменную. Если влияние фактора окажется несущественным, то этот фактор можно исключить из дальнейшей обработки. Макроэконометристы должны уметь решать четыре логически отличающиеся задачи: Описание данных; Макроэкономический прогноз; Структурный вывод; Анализ политики. Описание данных означает описание свойств одного или нескольких временных рядов и сообщение этих свойств широкому кругу экономистов. Макроэкономический прогноз означает предсказание курса экономики, обычно на два-три года или меньше (главным образом потому, что прогнозировать на более длинные горизонты слишком трудно). Структурный вывод означает проверку того, соответствуют ли макроэкономические данные конкретной экономической теории. Макроэконометрический анализ политики происходит по нескольким направлениям: с одной стороны, оценивается влияние на экономику гипотетического изменения инструментов политики (например налоговой ставки или краткосрочной процентной ставки), с другой стороны, оценивается влияние изменения правил политики (например переход к новому режиму монетарной политики). Эмпирический макроэкономический исследовательский проект может включать одну или несколько из этих четырех задач. Каждая задача должна быть решена таким образом, чтобы были учтены корреляции между рядами по времени. В 1970-х годах эти задачи решались с использованием разнообразных методов, которые, если оценить их с современных позиций, были неадекватны по нескольким причинам. Чтобы описать динамику отдельного ряда, достаточно было просто использовать одномерные модели временных рядов, а чтобы описать совместную динамику двух рядов – спектральный анализ. Однако отсутствовал общепринятый язык, пригодный для систематического описания совместных динамических свойств нескольких временных рядов. Экономические прогнозы делались либо с использованием упрощенных моделей авторегрессии - скользящего среднего (ARMA), либо с использованием популярных в то время больших структурных эконометрических моделей. Структурный вывод основывался либо на малых моделях с одним уравнением, либо на больших моделях, идентификация в которых достигалась за счет плохо обоснованных исключающих ограничений, и которые обычно не включали ожидания. Анализ политики на основе структурных моделей зависел от этих идентифицирующих предположений. Наконец, рост цен в 1970-е годы рассматривался многими как серьезная неудача больших моделей, которые в то время использовались для выработки политических рекомендаций. То есть это было подходящее время для появления новой макроэконометрической конструкции, которая могла бы решить эти многочисленные проблемы. В 1980 году была создана такая конструкция – векторные авторегрессии (VAR). На первый взгляд, VAR – не более, чем обобщение одномерной авторегрессии на многомерный случай, и каждое уравнение в VAR – не более, чем обычная регрессия по методу наименьших квадратов одной переменной на запаздывающие значения себя и других переменных в VAR. Но этот вроде бы простой инструмент дал возможность систематически и внутренне согласованно уловить богатую динамику многомерных временных рядов, а статистический инструментарий, который сопутствует VAR, оказался удобным и, что очень важно, его было легко интерпретировать. Выделяют три различных VAR-модели: Приведенная форма VAR; Рекурсивная VAR; Структурная VAR. Все три являются динамическими линейными моделями, которые связывают текущие и прошлые значения вектора Y t
n-мерного временного ряда. Приведенная форма и рекурсивные VAR – это статистические модели, которые не используют никакие экономические соображения за исключением выбора переменных. Эти VAR используются для описания данных и прогноза. Структурная VAR включает ограничения, полученные из макроэкономической теории, и эта VAR используется для структурного вывода и анализа политики. Приведенная форма VAR выражает Y t
в виде распределенного лага прошлых значений плюс серийно некоррелированный член ошибки, то есть обобщает одномерную авторегрессию на случай векторов. Математически приведенная форма модели VAR – это система n уравнений, которые можно записать в матричной форме следующим образом: где - это n l вектор констант; A 1
, A 2
, ..., A p
– это n n матрицы коэффициентов; t
, - это nl вектор серийно некоррелированных ошибок, о которых предполагается, что они имеют среднее ноль и матрицу ковариаций . Ошибки t
, в (17) – это неожиданная динамика в Y t
, остающаяся после учета линейного распределенного лага прошлых значений. Оценить параметры приведенной формы VAR легко. Каждое из уравнений содержит одни и те же регрессоры (Y t–1
,...,Y t–p), и нет взаимных ограничений между уравнениями. Таким образом, эффективная оценка (метод максимального правдоподобия с полной информацией) упрощается до обычного МНК, примененного к каждому из уравнений. Матрицу ковариаций ошибок можно состоятельно оценить выборочной ковариационной матрицей полученных из МНК остатков. Единственная тонкость – определить длину лага p, но это можно сделать, используя информационный критерий, такой как AIC или BIC. На уровне матричных уравнений рекурсивная и структурная VAR выглядят одинаково. Эти две модели VAR учитывают в явном виде одновременные взаимодействия между элементами Y t
, что сводится к добавлению одновременного члена к правой части уравнения (17). Соответственно, рекурсивная и структурная VAR обе представляются в следующем общем виде: где - вектор констант; B 0
,..., B p
- матрицы; t
- ошибки. Наличие в уравнении матрицы B 0
означает возможность одновременного взаимодействия между n переменными; то есть B 0
позволяет сделать так, чтобы эти переменные, относящиеся к одному моменту времени, определялись совместно. Рекурсивную VAR можно оценить двумя способами. Рекурсивная структура дает набор рекурсивных уравнений, которые можно оценить с помощью МНК. Эквивалентный способ оценивания заключается в том, что уравнения приведенной формы (17), рассматриваемые как система, умножаются слева на нижнюю треугольную матрицу. Метод оценивания структурной VAR зависит от того, как именно идентифицирована B 0
. Подход с частичной информацией влечет использование методов оценивания для отдельного уравнения, таких как двухшаговый метод наименьших квадратов. Подход с полной информацией влечет использование методов оценивания для нескольких уравнений, таких как трехшаговый метод наименьших квадратов. Необходимо помнить о множественности различных типов VAR. Приведенная форма VAR единственна. Данному порядку переменных в Y t
соответствует единственная рекурсивная VAR, но всего имеется n! таких порядков, т.е. n! различных рекурсивных VAR. Количество структурных VAR – то есть наборов предположений, которые идентифицируют одновременные взаимосвязи между переменными, - ограничено только изобретательностью исследователя. Поскольку матрицы оцененных коэффициентов VAR затруднительно интерпретировать непосредственно, результаты оценивания VAR обычно представляют некоторыми функциями этих матриц. К таким статистикам разложения ошибки прогноза. Разложения дисперсии ошибки прогноза вычисляются в основном для рекурсивных или структурных систем. Такое разложение дисперсии показывает, насколько ошибка в j-м уравнении важна для объяснения неожиданных изменений i-й переменной. Когда ошибки VAR некоррелированы по уравнениям, дисперсию ошибки прогноза на h периодов вперед можно записать как сумму компонентов, являющихся результатом каждой из этих ошибок /17/. 3.2 Факторный анализ
В современной статистике под факторным анализом понимают совокупность методов, которые на основе реально существующих связей признаков (или объектов) позволяют выявлять латентные обобщающие характеристики организационной структуры и механизма развития изучаемых явлений и процессов. Понятие латентности в определении ключевое. Оно означает неявность характеристик, раскрываемых при помощи методов факторного анализа. Вначале имеется дело с набором элементарных признаков X j
, их взаимодействие предполагает наличие определенных причин, особенных условий, т.е. существование некоторых скрытых факторов. Последние устанавливаются в результате обобщения элементарных признаков и выступают как интегрированные характеристики, или признаки, но более высокого уровня. Естественно, что коррелировать могут не только тривиальные признаки X j
, но и сами наблюдаемые объекты N i
поэтому поиск латентных факторов теоретически возможен как по признаковым, так и по объектным данным. Если объекты характеризуются достаточно большим числом элементарных признаков (m > 3), то логично и другое предположение - о существовании плотных скоплений точек (признаков) в пространстве n объектов. При этом новые оси обобщают уже не признаки X j
, а объекты n i
, соответственно и латентные факторы F r
будут распознаны по составу наблюдаемых объектов: F r
= c 1
n 1
+ c 2
n 2 + ... +
c N
n N
, где c i
- вес объекта n i
в факторе F r
. В зависимости от того, какой из рассмотренных выше тип корреляционной связи - элементарных признаков или наблюдаемых объектов - исследуется в факторном анализе, различают R и Q - технические приемы обработки данных. Название R-техники носит объемный анализ данных по m признакам, в результате него получают r линейных комбинаций (групп) признаков: F r
=f(X j), (r=1..m). Анализ по данным о близости (связи) n наблюдаемых объектов называется Q-техникой и позволяет определять r линейных комбинаций (групп) объектов: F=f(n i), (i = l .. N). В настоящее время на практике более 90% задач решается при помощи R-техники. Набор методов факторного анализа в настоящее время достаточно велик, насчитывает десятки различных подходов и приемов обработки данных. Чтобы в исследованиях ориентироваться на правильный выбор методов, необходимо представлять их особенности. Разделим все методы факторного анализа на несколько классификационных групп: Метод главных компонент. Строго говоря, его не относят к факторному анализу, хотя он имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу элементарных признаков. Во-вторых, постулируется возможность полного разложения дисперсии элементарных признаков, другими словами, ее полное объяснение через латентные факторы (обобщенные признаки). Методы факторного анализа. Дисперсия элементарных признаков здесь объясняется не в полном объеме, признается, что часть дисперсии остается нераспознанной как характерность. Факторы обычно выделяются последовательно: первый, объясняющий наибольшую долю вариации элементарных признаков, затем второй, объясняющий меньшую, вторую после первого латентного фактора часть дисперсии, третий и т.д. Процесс выделения факторов может быть прерван на любом шаге, если принято решение о достаточности доли объясненной дисперсии элементарных признаков или с учетом интерпретируемости латентных факторов. Методы факторного анализа целесообразно разделить дополнительно на два класса: упрощенные и современные аппроксимирующие методы. Простые методы факторного анализа в основном связаны с начальными теоретическими разработками. Они имеют ограниченные возможности в выделении латентных факторов и аппроксимации факторных решений. К ним относятся: Однофакторная модель. Она позволяет выделить только один генеральный латентный и один характерный факторы. Для возможно существующих других латентных факторов делается предположение об их незначимости; Бифакторная модель. Допускает влияние на вариацию элементарных признаков не одного, а нескольких латентных факторов (обычно двух) и одного характерного фактора; Центроидный метод. В нем корреляции между переменными рассматриваются как пучок векторов, а латентный фактор геометрически представляется как уравновешивающий вектор, проходящий через центр этого пучка. : Метод позволяет выделять несколько латентных и характерные факторы, впервые появляется возможность соотносить факторное решение с исходными данными, т.е. в простейшем виде решать задачу аппроксимации. Современные аппроксимирующие методы часто предполагают, что первое, приближенное решение уже найдено каким либо из способов, последующими шагами это решение оптимизируется. Методы отличаются сложностью вычислений. К этим методам относятся: Групповой метод. Решение базируется на предварительно отобранных каким-либо образом группах элементарных признаков; Метод главных факторов. Наиболее близок методу главных компонент, отличие заключается в предположении о существовании характерностей; Метод максимального правдоподобия, минимальных остатков, а-факторного анализа канонического факторного анализа, все оптимизирующие. Эти методы позволяют последовательно улучшить предварительно найденные решения на основе использования статистических приемов оценивания случайной величины или статистических критериев, предполагают большой объем трудоемких вычислений. Наиболее перспективным и удобным для работы в этой группе признается метод максимального правдоподобия. Основной задачей, которую решают разнообразными методами факторного анализа, включая и метод главных компонент, является сжатие информации, переход от множества значений по m элементарным признакам с объемом информации n х m к ограниченному множеству элементов матрицы факторного отображения (m х r) или матрицы значений латентных факторов для каждого наблюдаемого объекта размерностью n х r, причем обычно r < m. Методы факторного анализа позволяют также визуализировать структуру изучаемых явлений и процессов, а это значит определять их состояние и прогнозировать развитие. Наконец, данные факторного анализа дают основания для идентификации объекта, т.е. решения задачи распознавания образа. Методы факторного анализа обладают свойствами, весьма привлекательными для их использования в составе других статистических методов, наиболее часто в корреляционно-регрессионном анализе, кластерном анализе, многомерном шкалировании и др. /18/. 3.3 Парная регрессия. Вероятностная природа регрессионных моделей.
Если рассмотреть задачу анализа расходов на питание в группах с одинаковыми доходами, например в $10.000(x), то это детерминированная величина. А вот Y - доля этих денег, затрачиваемая на питание - случайна и может меняться от года к году. Поэтому для каждого i-го индивида: где ε i
- случайная ошибка; α и β - константы (теоретически), хотя могут меняться от модели к модели. Предпосылки для парной регрессии: X и Y связаны линейно; Х - неслучайная переменная с фиксированными значениями; - ε - ошибки нормально распределены N(0,σ 2); - На рисунке 3.1 представлена модель парной регрессии. Рисунок 3.1 – Модель парной регрессии Эти предпосылки описывают классическую линейную регрессионную модель. Если ошибка имеет ненулевое среднее, исходная модель будет эквивалентна новой модели и другим свободным членом, но с нулевым средним для ошибки. Если выполняются предпосылки, то МНК оценки и являются эффективными линейными несмещенными оценками Если обозначить: то что математическое ожидание и дисперсии коэффициентов и будут следующие: Ковариация коэффициентов: Если Отсюда следует, что: Вариация β полностью определяется вариацией ε; Чем выше дисперсия X - тем лучше оценка β. Полная дисперсия определяется по формуле: Дисперсия отклонений в таком виде - несмещенная оценка и называется стандартной ошибкой регрессии. N-2 - может быть интерпретировано как число степеней свободы. Анализ отклонений от линии регрессии может представить полезную меру того, насколько оцененная регрессия отражает реальные данные. Хорошая регрессия та, которая объясняет значительную долю дисперсии Y и наоборот плохая регрессия не отслеживает большую часть колебаний исходных данных. Интуитивно ясно, что всякая дополнительная информация позволит улучшить модель, то есть уменьшить необъясненную долю вариации Y. Для анализа регрессионной модели проводят разложение дисперсии на составляющие, определяют коэффициент детерминации R 2
. Отношение двух дисперсий распределено по F-распределению, т. е. если проверить на статистическую значимость отличия дисперсии модели от дисперсии остатков, можно сделать вывод о значимости R 2
. Проверка гипотезы о равенстве дисперсий этих двух выборок: Если гипотеза Н 0
(о равенстве дисперсий нескольких выборок) верна, t имеет F-распределение с (m 1
,m 2)=(n 1
-1,n 2
-1) степенями свободы. Посчитав F – отношение как отношение двух дисперсий и сравнив его с табличным значением, можно сделать вывод о статистической значимости R 2
/2/, /19/. Заключение
Современные приложения дисперсионного анализа охватывают широкий круг задач экономики, биологии и техники и трактуются обычно в терминах статистической теории выявления систематических различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях. Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования с применение ЭВМ, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как: В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных. Дисперсионный анализ является мощным современным статистическим методом обработки и анализа экспериментальных данных в психологии, биологии, медицине и других науках. Он очень тесно связан с конкретной методологией планирования и проведения экспериментальных исследований. Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную. Список литературы
1 Кремер Н.Ш. Теория вероятности и математическая статистика. М.: Юнити – Дана, 2002.-343с. 2 Гмурман В.Е. Теория вероятностей и математическая статистика. – М.: Высшая школа, 2003.-523с. 4 www.conf.mitme.ru 5 www.pedklin.ru 6 www.webcenter.ru 7 www.infections.ru 8 www.encycl.yandex.ru 9 www.infosport.ru 10 www.medtrust.ru 11 www.flax.net.ru 12 www.jdc.org.il 13 www.big.spb.ru 14 www.bizcom.ru 15 Гусев А.Н. Дисперсионный анализ в экспериментальной психологии. – М.: Учебно-методический коллектор «Психология», 2000.-136с. 17 www.econometrics.exponenta.ru 18 www.optimizer.by.ru Дисперсионный анализ есть совокупность статистических методов, предназначенных для проверки гипотез о связи между определенными признаками и исследуемыми факторами, которые не имеют количественного описания, а также для установления степени влияния факторов и их взаимодействия. В специальной литературе его часто называют ANOVA (от англоязычного названия Analysis of Variations). Впервые этот метод был разработан Р. Фишером в 1925 г. Этот метод используется для исследования связи между качественными (номинальными) признаками и количественной (непрерывной) переменной. По сути, он осуществляет тестирование гипотезы о равенстве средних арифметических нескольких выборок. Таким образом, его можно рассматривать как параметрический критерий для сравнения центров сразу нескольких выборок. Если использовать этот метод для двух выборок, то результаты дисперсионного анализа будут идентичны результатам t-критерия Стьюдента. Однако, в отличие от других критериев, это исследование позволяет изучить проблему более детально. Дисперсионный анализ в статистике базируется на законе: сумма квадратов отклонений объединенной выборки равна сумме квадратов внутригрупповых отклонений и сумме квадратов межгрупповых отклонений. Для исследования используется критерий Фишера для установления значимости различия межгрупповых дисперсий от внутригрупповых. Однако для этого необходимыми предпосылками являются нормальность распределения и гомоскедастичность (равенство дисперсий) выборок. Различают одномерный (однофакторный) дисперсионный анализ и многомерный (многофакторный). Первый рассматривает зависимость исследуемой величины от одного признака, второй - сразу от многих, а также позволяет выявить связь между ними. Факторами называют контролируемые обстоятельства, что влияют на конечный результат. Его уровнем или способом обработки называют значение, которое характеризует конкретное проявление этого условия. Эти цифры обычно подают в номинальной или порядковой шкале измерений. Часто выходные значения измеряют в количественных или порядковых шкалах. Тогда возникает проблема группировки выходных данных в ряде наблюдений, что соответствуют примерно одинаковым числовым значениям. Если количество групп взять чрезмерно большим, то количество наблюдений в них может оказаться недостаточным для получения надежных результатов. Если брать число чрезмерно малым, это может привести к потере существенных особенностей влияния на систему. Конкретный способ группировки данных зависит от объема и характера варьирования значений. Количество и размеры интервалов при однофакторном анализе чаще всего определяют по принципу равных промежутков или по принципу равных частот. Итак, существуют случаи, когда нужно сравнить две или больше выборок. Именно тогда и целесообразно применение дисперсионного анализа. Название метода указывает на то, что выводы делают на основе исследования составляющих дисперсии. Суть изучения состоит в том, что общее изменение показателя разбивают на составляющие части, которые соответствуют действию каждого отдельно взятого фактора. Рассмотрим ряд задач, которые решает типичный дисперсионный анализ. Пример 1
В цехе есть ряд станков - автоматов, которые изготавливают определенную деталь. Размер каждой детали - это случайная величина, которая зависит от настройки каждого станка и случайных отклонений, возникающих в процессе изготовления деталей. Нужно по данным измерений размеров деталей определить, одинаково ли настроены станки. Пример 2
Во время изготовления электрического аппарата используют различные типы изоляционной бумаги: конденсаторную, электротехническую и др. Аппарат можно пропитать различными веществами: эпоксидной смолой, лаком, смолой МЛ-2 и др. Утечки можно устранять под вакуумом при повышенном давлении, при нагреве. Пропитывать можно методом погружения в лак, под непрерывной струей лака и т. п. Электрический аппарат в целом заливают определенным компаундом, вариантов которого есть несколько. Показателями качества являются электрическая прочность изоляции, температура перегрева обмотки в рабочем режиме и ряд других. Во время отработки технологического процесса изготовления аппаратов надо определить, как влияет каждый из перечисленных факторов на показатели аппарата. Пример 3
Троллейбусное депо обслуживает несколько троллейбусных маршрутов. На них работают троллейбусы различных типов, и оплату за проезд собирают 125 контролеров. Руководство депо интересует вопрос: как сравнить экономические показатели работы каждого контролера (выручку) учитывая различные маршруты, различные типы троллейбусов? Как определить экономическую целесообразность выпуска троллейбусов определенного типа на тот или другой маршрут? Как установить обоснованные требования к величине выручки, которую приносит кондуктор, на каждом маршруте в различных типах троллейбусов? Задача по выбору метода состоит в том, как получить максимум информации относительно влияния на конечный результат каждого фактора, определить числовые характеристики такого влияния, их надежность при минимальных затратах и за максимально короткое время. Решить такие задачи позволяют методы дисперсионного анализа. Исследование своей целью ставит оценку величины влияния конкретного случая на анализируемый отзыв. Другой задачей однофакторного анализа может быть сравнение двух или нескольких обстоятельств друг с другом с целью определения разницы их влияния на отзыв. Если нулевую гипотезу отвергают, то следующим этапом будет количественное оценивание и построение доверительных интервалов для полученных характеристик. В случае, когда нулевая гипотеза не может быть отброшенной, обычно ее принимают и делают вывод о сущности влияния. Однофакторный дисперсионный анализ может стать непараметрическим аналогом рангового метода Краскела-Уоллиса. Он разработан американскими математиком Уильямом Краскелом и экономистом Вильсоном Уоллисом в 1952 г. Этот критерий назначен для проверки нулевой гипотезы о равенстве эффектов влияния на исследуемые выборки с неизвестными, но равными средними величинами. При этом количество выборок должно быть больше двух. Критерий Джонкхиера (Джонкхиера-Терпстра) был предложен независимо друг от друга нидерландским математиком Т. Дж. Терпстром в 1952 г. и британским психологом Е. Р. Джонкхиером в 1954 г. Его применяют тогда, когда заранее известно, что имеющиеся группы результатов упорядочены по росту влияния исследуемого фактора, который измеряют в порядковой шкале. М - критерий Бартлетта, предложенный британским статистиком Маурисом Стивенсоном Бартлеттом в 1937 г., применяют для проверки нулевой гипотезы о равенстве дисперсий нескольких нормальных генеральных совокупностей, с которых взяты исследуемые выборки, в общем случае имеющие различные объемы (число каждой выборки должно быть не меньше четырех). G - критерий Кохрена, который открыл американец Вильям Геммел Кохрен в 1941 г. Его используют для проверки нулевой гипотезы о равенстве дисперсий нормальных генеральных совокупностей по независимым выборкам равного объема. Непараметрический критерий Левене, предложенный американским математиком Ховардом Левене в 1960 г., является альтернативой критерия Бартлетта в условиях, когда нет уверенности в том, что исследуемые выборки подчиняются нормальному распределению. В 1974 г. американские статистики Мортон Б. Браун и Алан Б. Форсайт предложили тест (критерий Брауна-Форсайта), который несколько отличается от критерия Левене. Двухфакторный дисперсионный анализ применяют для связанных нормально распределенных выборок. На практике часто используют и сложные таблицы этого метода, в частности те, в которых каждая ячейка содержит набор данных (повторные измерения), соответствующих фиксированным значениям уровней. Если предположения, необходимые для применения двухфакторного дисперсионного анализа, не выполняются, то используют непараметрический ранговый критерий Фридмана (Фридмана, Кендалла и Смита), разработанный американским экономистом Милтоном Фридманом в конце 1930 г. Этот критерий не зависит от типа распределения. Предполагается только, что распределение величин является одинаковым и непрерывным, а сами они независимы одна от другой. При проверке нулевой гипотезы выходные данные подают в форме прямоугольной матрицы, в которой строки соответствуют уровням фактора В, а столбцы - уровням А. Каждая ячейка таблицы (блока) может быть результатом измерений параметров на одном объекте или на группе объектов при постоянных значениях уровней обоих факторов. В этом случае соответствующие данные подают как средние значения определенного параметра по всем измерениям или объектам исследуемой выборки. Для применения критерия выходных данных необходимо перейти от непосредственных результатов измерений к их рангу. Ранжирование осуществляют по каждой строке отдельно, то есть величины упорядочивают для каждого фиксированного значения. Критерий Пейджа (L-критерий), предложенный американским статистиком Е. Б. Пейджем в 1963 г., предназначен для проверки нулевой гипотезы. Для больших выборок применяют аппроксимацию Пейджа. Они при условии реальности соответствующих нулевых гипотез подчиняются стандартному нормальному распределению. В случае, когда в строках исходной таблицы есть одинаковые значения, необходимо использовать средние ранги. При этом точность выводов будет тем хуже, чем больше будет количеств таких совпадений. Q - критерий Кохрена, предложенный В. Кохреном в 1937 г. Его используют в случаях, когда группы однородных субъектов подвергаются воздействиям, количество которых превышает два и для которых возможны два варианта отзывов - условно-отрицательный (0) и условно-положительный (1). Нулевая гипотеза состоит из равенства эффектов влияния. Двухфакторный дисперсионный анализ дает возможность определить существование эффектов обработки, однако не дает возможности установить, для каких именно столбцов существует этот эффект. При решении данной проблемы применяют метод множественных уравнений Шеффе для связанных выборок. Задача многофакторного дисперсионного анализа возникает тогда, когда нужно определить влияние двух или большего количества условий на определенную случайную величину. Исследование предусматривает наличие одной зависимой случайной величины, измеренной в шкале разницы или отношений, и нескольких независимых величин, каждая из которых выражена в шкале наименований или в ранговой. Дисперсионный анализ данных является достаточно развитым разделом математической статистики, который имеет массу вариантов. Концепция исследования общая как для однофакторного, так и для многофакторного. Сущность ее состоит в том, что общую дисперсию разбивают на составляющие, что соответствует определенной группировке данных. Каждой группировке данных соответствует своя модель. Здесь мы рассмотрим только основные положения, нужные для понимания и практического использования наиболее применяемых его вариантов. Дисперсионный анализ факторов требует достаточно внимательного отношения к сбору и подаче входных данных, а особенно к интерпретации результатов. В отличие от однофакторного, результаты которого можно условно разместить в определенной последовательности, результаты двухфакторного требуют более сложного представления. Еще сложнее ситуация возникает, когда есть три, четыре или больше обстоятельств. Из-за этого в модель достаточно редко включают больше трех (четырех) условий. Примером может быть возникновение резонанса при определенной величине емкости и индуктивности электрического круга; проявление химической реакции при определенной совокупности элементов, из которых построена система; возникновение аномальных эффектов в сложных системах при определенном совпадении обстоятельств. Наличие взаимодействия может в корне изменить модель системы и иногда привести к переосмыслению природы явлений, с которыми имеет дело экспериментатор. Данные измерений достаточно часто можно группировать не по двум, а по большему количеству факторов. Так, если рассматривать дисперсионный анализ срока службы покрышек колес троллейбуса с учетом обстоятельств (завод-производитель и маршрут, на котором эксплуатируются покрышки), то можно выделить как отдельное условие сезон, во время которого эксплуатируются покрышки (а именно: зимняя и летняя эксплуатация). В результате будем иметь задачу трехфакторного метода. При наличии большего количества условий подход такой же, как и в двухфакторном анализе. Во всех случаях модель пытаются упростить. Явление взаимодействия двух факторов проявляется не так часто, а тройное взаимодействие бывает только в исключительных случаях. Включают то взаимодействие, для которого есть предыдущая информация и серьезные основания, чтобы ее учесть в модели. Процесс выделения отдельных факторов и их учета относительно простой. Поэтому часто возникает желание выделить больше обстоятельств. Этим не следует увлекаться. Чем больше условий, тем менее надежной становится модель и тем больше вероятность ошибки. Сама модель, в которую входит большое количество независимых переменных, становится достаточно сложной для интерпретации и неудобной для практического использования. Дисперсионный анализ в статистике - это метод получения результатов наблюдений, зависимых от различных одновременно действующих обстоятельств, и оценки их влияния. Управляемую переменную величину, которая соответствует способу воздействия на объект исследования и в некоторый период времени приобретает определенное значение, называют фактором. Они могут быть качественными и количественными. Уровни количественных условий приобретают определенное значение на числовой шкале. Примерами являются температура, давление прессования, количество вещества. Качественные факторы - это разные вещества, разные технологические способы, аппараты, наполнители. Их уровням соответствует шкала наименований. К качественным можно отнести также вид упаковочного материала, условия хранения лекарственной формы. Сюда же рационально отнести степень измельчения сырья, фракционный состав гранул, имеющих количественное значение, однако плохо поддающихся регулированию, если использовать количественную шкалу. Число качественных факторов зависит от вида лекарственной формы, а также физических и технологических свойств лекарственных веществ. Например, из кристаллических веществ можно получать таблетки прямым прессованием. В этом случае достаточно провести выбор скользящих и смазывающих веществ. Одним из важнейших критериев оценки состояния государства, по которым проводится оценка уровня его благосостояния и социально-экономического развития, является конкурентоспособность, то есть совокупность свойств, присущих национальной экономике, которые определяют способность государства конкурировать с другими странами. Определив место и роль государства на мировом рынке, можно установить четкую стратегию обеспечения экономической безопасности в международных масштабах, ведь она является залогом положительных взаимоотношений России со всеми игроками мирового рынка: инвесторами, кредиторами, правительствами государств. Для сравнения уровня конкурентоспособности государств проводится ранжирование стран с помощью комплексных индексов, которые включают различные взвешенные показатели. В основу этих индексов заложены ключевые факторы, влияющие на экономическое, политическое и т. п. положение. Комплекс моделей исследования конкурентоспособности государства предусматривает использование методов многомерного статистического анализа (в частности, это дисперсионный анализ (статистика), эконометрическое моделирование, принятие решений) и включает следующие основные этапы: А теперь рассмотрим содержание моделей каждого из этапов данного комплекса. На первом этапе
с помощью методов экспертного изучения формируется обоснованный комплекс экономических показателей-индикаторов оценки конкурентоспособности государства с учетом специфики ее развития на основе международных рейтингов и данных статистических отделов, отражающих состояние системы в целом и ее процессов. Выбор этих показателей обоснован необходимостью отобрать те из них, которые наиболее полно с точки зрения практики позволяют определить уровень государства, его инвестиционную привлекательность и возможности относительной локализации существующих потенциальных и реально действующих угроз. Основные показатели-индикаторы международных рейтинг-систем - это индексы: Второй этап
предусматривает оценку и прогнозирование индикаторов конкурентоспособности государства по международным рейтингам для исследуемых 139 государств мира. Третий этап
предусматривает сравнение условий конкурентоспособности государств при помощи методов корреляционно-регрессионного анализа. Используя результаты исследования можно определить характер протекания процессов в целом и по отдельным составляющим конкурентоспособности государства; проверить гипотезу о влиянии факторов и их взаимосвязи при соответствующем уровне значимости. Реализация предложенного комплекса моделей позволит не только оценить сложившуюся ситуацию уровня конкурентоспособности и инвестиционной привлекательности государств, но и проанализировать недостатки управления, предупредить ошибки неправильных решений, не допустить развития кризиса в государстве.![]() ,
,
![]()
![]() .
.
![]()



![]() то и распределены тоже нормально:
то и распределены тоже нормально:



![]()
Виды и критерии дисперсионного анализа
Факторы
Задачи дисперсионного анализа

Однофакторный анализ

Двухфакторный анализ

Многофакторный анализ

Многофакторный дисперсионный анализ с повторными опытами
Общая идея дисперсионного анализа

Примеры качественных факторов для различных видов лекарственных форм
Примеры качественных факторов и их уровней, изучаемых в процессе изготовления таблеток
Модели дисперсионного анализа в исследовании уровня конкурентоспособности государства


 Физика Земли
Скачать русский трафаретный шрифт Скачать набор трафаретов
Физика Земли
Скачать русский трафаретный шрифт Скачать набор трафаретов Природа в литературе
Оценка научной и научно-технической результативности нир Расчет и сопоставление
удельных капитальных вложений
Природа в литературе
Оценка научной и научно-технической результативности нир Расчет и сопоставление
удельных капитальных вложений Картины художников
Реферат когнитивный анализ, когнитивные модели Основные этапы разработки когнитивной модели проблемной ситуации
Картины художников
Реферат когнитивный анализ, когнитивные модели Основные этапы разработки когнитивной модели проблемной ситуации Россия
Гибель византии и возникновение османской империи кратко
Россия
Гибель византии и возникновение османской империи кратко Времена года
Прописи для исправления почерка взрослого Каллиграфия для детей прописи
Времена года
Прописи для исправления почерка взрослого Каллиграфия для детей прописи

