Назначение множественной регрессии – анализ связи между одной зависимой и несколькими независимыми переменными.
Пример: Имеются данные о стоимости одного рабочего места (при покупке 50 рабочих мест) для различных PDM-систем. Требуется: оценить зависимость между ценой рабочего места PDM-системы от количества реализованных в ней характеристик, приведенных в таблице 2.
Таблица 2 - Характеристики PDM-систем
| Номер п/п | PDM-система | Стоимость | Управление конфигурацией изделия | Модели изделий | Коллективная работа | Управление изменениями изделий | Документооборот | Архивы | Поиск документов | Планирование проекта | Управление изготовлением изделий |
| iMAN | Да | Да | |||||||||
| PartY Plus | Да | Да | |||||||||
| PDM STEP Suite | Да | Да | |||||||||
| Search | Да | Да | |||||||||
| Windchill | Да | Да | |||||||||
| Компас-Менеджер | Да | Да | |||||||||
| T-Flex Docs | Да | Да | |||||||||
| ТехноПро | Нет | Нет |
Численное значение характеристик (кроме «Стоимость», «Модели изделий» и «Коллективная работа») означает количество реализованных требований каждой характеристики.
Создадим и заполним электронную таблицу с исходными данными (Рисунок 27).
Значение «1» переменных «Мод. изд.» и «Коллект. р-та.» соответствует значению «Да» исходных данных, а значение «0» значению «Нет» исходных данных.
Построим регрессию между зависимой переменной «Стоимость» и независимыми переменными «Упр. конф.», «Мод. изд.», «Коллект. р-та», «Упр. изм.», «Док.», «Архивы», «Поиск», «План-е», «Упр. изгот.».
Для начала статистического анализа исходных данных вызвать модуль «Multiple Regression» (рисунок 22).
В появившемся диалоговом окне (рисунок 23) указать переменные по которым будет производиться статистический анализ.
Рисунок 27 - Исходные данные
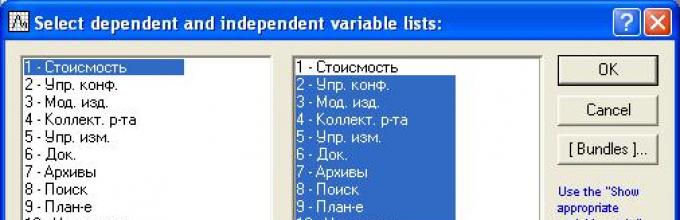
Для этого нажать кнопку Variables и в появившемся диалоговом окне (рисунок 28) в части соответствующей зависимым переменным (Dependent var.) выбрать «1-Стоимость», а в части соответствующей независимым переменным (Independent variable list) выбрать все остальные переменные. Выбор нескольких переменных из списка осуществляется с использованием клавиш «Ctrl» или «Shift», либо указанием номеров (диапазона номеров) переменных в соответствующем поле.

Рисунок 28 - Диалоговое окно задания переменных для статистического анализа
После того как переменные выбраны нажать кнопку «OK» в диалоговом окне задания параметров модуля «Multiple Regression». В появившемся окне с надписью «No of indep. vars. >=(N-1); cannot invert corr. matrix.» (рисунок 29) нажать кнопку «OK».
Данное сообщение появляется в случае когда система не может построить регрессию по всем заявленным независимым переменным, т.к. число переменных больше или равно числу случаев минус 1.
В появившемся окне (рисунок 30) на закладке «Advanced» можно изменить метод построения уравнения регрессии.

Рисунок 29 - Сообщение об ошибке
Для этого в поле «Method» (метод) выбрать «Forward stepwise» (пошаговый с включением).

Рисунок 30 - Окно выбора метода и задания параметров построения уравнения регрессии
Метод пошаговой регрессии состоит в том, что на каждом шаге в модель включается, либо исключается какая-то независимая переменная. Таким образом, выделяется множество наиболее "значимых" переменных. Это позволяет сократить число переменных, которые описывают зависимость.
Пошаговый анализ с исключением («Backward stepwise»). В этом случае все переменные будут сначала включены в модель, а затем на каждом шаге будут устраняться переменные, вносящие малый вклад в предсказания. Тогда в качестве результата успешного анализа можно сохранить только "важные" переменные в модели, то есть те переменные, чей вклад в дискриминацию больше остальных.
Пошаговый анализ с включением («Forward stepwise»). При использовании этого метода в регрессионное уравнение последовательно включаются независимые переменные, пока уравнение не станет удовлетворительно описывать исходные данные. Включение переменных определяется при помощи F - критерия. На каждом шаге просматриваются все переменные и находится та из них, которая вносит наибольший вклад в различие между совокупностями. Эта переменная должна быть включена в модель на данном шаге, и происходит переход к следующему шагу.
В поле «Intercept» (свободный член регрессии) можно выбрать включать ли его в уравнение («Include in model») либо не учитывать и считать равным нулю («Set to zero»).
Параметр «Tolerance» это толерантность переменных. Определяется как 1 минус квадрат коэффициента множественной корреляции этой переменной со всеми другими независимыми переменными в уравнении регрессии. Поэтому, чем меньший толерантность переменной, тем более избыточный - ее вклад в уравнение регрессии. Если толерантность любой из переменных в уравнении регрессии равна или близка к нулю, то уравнение регресса не может быть оценено. Поэтому параметр толерантность желательно задать равным 0,05 или 0,1.
Параметр «Ridge regression; lambda:» используется, когда независимые переменные высоко межкоррелированые, и устойчивые оценки для коэффициентов уравнения регрессии, не могут быть получен через метод наименьших квадратов. Указанная постоянная (лямбда) будет добавлена к диагонали матрицы корреляций, которая тогда заново будет приведена к стандартизированному виду (так чтобы все диагональные элементы были равны 1.0). Другими словами, данный параметр искусственно уменьшает коэффициенты корреляции так, чтобы можно было вычислить более устойчивые (все же смещенный) оценки параметров регрессии. В наше случае данный параметр не используется.
Параметр «Batch processing/printing» (обработка, печать отчетов) используется, когда необходимо сразу подготовить для отчета несколько таблиц, отражающих результаты и процесс регрессионного анализа. Эта опция весьма полезна, когда необходимо напечатать или проанализировать результаты пошагового регрессионного анализа на каждом шаге.
На закладке «Stepwise» (рисунок 31) можно задать параметры условия включения («F to enter») или исключения («F to remove») переменных при построении уравнения регрессии, а также количество шагов построения уравнения («Number of steps»).

Рисунок 31 – Закладка «Stepwise» окна выбора метода и задания параметров построения регрессионного уравнения
F это величина значения F-критерия.
Если при пошаговом анализе с включением необходимо, чтобы все или почти все переменные вошли в уравнение регрессии то необходимо значение «F to enter» установить минимальным (0,0001), и значение «F to remove» также установить минимальным.
Если при пошаговом анализе с исключением необходимо, удалять все переменные (по одной) из уравнения регрессии то необходимо значение «F to enter» установить очень большим, например 999, и значение «F to remove» установить близким к «F to enter».
Следует помнить, что значение параметра «F to remove» всегда должно быть меньше чем «F to enter».
Опция «Display results» (отображение результатов) имеет два варианта:
2) At each step – отображать результаты анализа на каждом шаге.
После нажатия кнопки «OK» в окне выбора методов регрессионного анализа появится окно результатов анализа (рисунок 32).

Рисунок 32 - Окно результатов анализа

Рисунок 33 - Краткие результаты регрессионного анализа
Согласно результатам анализа коэффициент детерминации . Это означает, что построенная регрессия объясняет 99,987% разброса значений относительно среднего, т.е. объясняет практически всю изменчивость переменных.
Большое значение и его уровень значимости показывают, что построенная регрессия высоко значима.
Для просмотра кратких результатов регрессии нажать кнопку «Summary: Regression result». На экране появится электронная таблица с результатами анализа (рисунок 33).
В третьем столбце («B») отображены оценки неизвестных параметров модели, т.е. коэффициенты уравнения регрессии.
Таким образом, искомая регрессия имеет вид:
Качественно построенное уравнение регрессии можно интерпретировать следующим образом:
1) Стоимость PDM-системы увеличивается с возрастанием количества реализованных функций по управлению изменениями, документообороту и планированию, а также, если в систему включена функция поддержки модели изделия;
2) Стоимость PDM-системы снижается с увеличением реализованных функций управления конфигурацией и с увеличением возможностей поиска.
Добрый день, уважаемые читатели.В прошлых статьях, на практических примерах, мной были показаны способы решения задач классификации (задача кредитного скоринга) и основ анализа текстовой информации (задача о паспортах). Сегодня же мне бы хотелось коснуться другого класса задач, а именно восстановления регрессии . Задачи данного класса, как правило, используются при прогнозировании .
Для примера решения задачи прогнозирования, я взял набор данных Energy efficiency из крупнейшего репозитория UCI . В качестве инструментов по традиции будем использовать Python c аналитическими пакетами pandas и scikit-learn .
Описание набора данных и постановка задачи
Дан набор данных , котором описаны следующие атрибуты помещения:В нем - характеристики помещения на основании которых будет проводиться анализ, а - значения нагрузки, которые надо спрогнозировать.
Предварительный анализ данных
Для начала загрузим наши данные и посмотрим на них:From pandas import read_csv, DataFrame
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.cross_validation import train_test_split
dataset = read_csv("EnergyEfficiency/ENB2012_data.csv",";")
dataset.head()
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | Y1 | Y2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.98 | 514.5 | 294.0 | 110.25 | 7 | 2 | 0 | 0 | 15.55 | 21.33 |
| 1 | 0.98 | 514.5 | 294.0 | 110.25 | 7 | 3 | 0 | 0 | 15.55 | 21.33 |
| 2 | 0.98 | 514.5 | 294.0 | 110.25 | 7 | 4 | 0 | 0 | 15.55 | 21.33 |
| 3 | 0.98 | 514.5 | 294.0 | 110.25 | 7 | 5 | 0 | 0 | 15.55 | 21.33 |
| 4 | 0.90 | 563.5 | 318.5 | 122.50 | 7 | 2 | 0 | 0 | 20.84 | 28.28 |
Теперь давайте посмотрим не связаны ли между собой какие-либо атрибуты. Сделать это можно рассчитав коэффициенты корреляции для всех столбцов. Как это сделать было описано в предыдущей статье :
Dataset.corr()
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | Y1 | Y2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| X1 | 1.000000e+00 | -9.919015e-01 | -2.037817e-01 | -8.688234e-01 | 8.277473e-01 | 0.000000 | 1.283986e-17 | 1.764620e-17 | 0.622272 | 0.634339 |
| X2 | -9.919015e-01 | 1.000000e+00 | 1.955016e-01 | 8.807195e-01 | -8.581477e-01 | 0.000000 | 1.318356e-16 | -3.558613e-16 | -0.658120 | -0.672999 |
| X3 | -2.037817e-01 | 1.955016e-01 | 1.000000e+00 | -2.923165e-01 | 2.809757e-01 | 0.000000 | -7.969726e-19 | 0.000000e+00 | 0.455671 | 0.427117 |
| X4 | -8.688234e-01 | 8.807195e-01 | -2.923165e-01 | 1.000000e+00 | -9.725122e-01 | 0.000000 | -1.381805e-16 | -1.079129e-16 | -0.861828 | -0.862547 |
| X5 | 8.277473e-01 | -8.581477e-01 | 2.809757e-01 | -9.725122e-01 | 1.000000e+00 | 0.000000 | 1.861418e-18 | 0.000000e+00 | 0.889431 | 0.895785 |
| X6 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 1.000000 | 0.000000e+00 | 0.000000e+00 | -0.002587 | 0.014290 |
| X7 | 1.283986e-17 | 1.318356e-16 | -7.969726e-19 | -1.381805e-16 | 1.861418e-18 | 0.000000 | 1.000000e+00 | 2.129642e-01 | 0.269841 | 0.207505 |
| X8 | 1.764620e-17 | -3.558613e-16 | 0.000000e+00 | -1.079129e-16 | 0.000000e+00 | 0.000000 | 2.129642e-01 | 1.000000e+00 | 0.087368 | 0.050525 |
| Y1 | 6.222722e-01 | -6.581202e-01 | 4.556712e-01 | -8.618283e-01 | 8.894307e-01 | -0.002587 | 2.698410e-01 | 8.736759e-02 | 1.000000 | 0.975862 |
| Y2 | 6.343391e-01 | -6.729989e-01 | 4.271170e-01 | -8.625466e-01 | 8.957852e-01 | 0.014290 | 2.075050e-01 | 5.052512e-02 | 0.975862 | 1.000000 |
Как можно заметить из нашей матрицы, коррелируют между собой следующие столбы (Значение коэффициента корреляции больше 95%):
- y1 --> y2
- x1 --> x2
- x4 --> x5
Как можно заметить и матрицы с коэффициентами корреляции на y1 ,y2 больше значения оказывают X2 и X5 , нежели X1 и X4, таким образом мы можем последние столбцы мы можем удалить.
Dataset = dataset.drop(["X1","X4"], axis=1)
dataset.head()
Помимо этого, можно заметить, что поля Y1
и Y2
очень тесно коррелируют между собой. Но, т. к. нам надо спрогнозировать оба значения мы их оставляем «как есть».
Выбор модели
Отделим от нашей выборки прогнозные значения:Trg = dataset[["Y1","Y2"]]
trn = dataset.drop(["Y1","Y2"], axis=1)
После обработки данных можно перейти к построению модели. Для построения модели будем использовать следующие методы:
Теорию о данным методам можно почитать в курсе лекций К.В.Воронцова по машинному обучению .
Оценку будем производить с помощью коэффициента детерминации (R-квадрат
). Данный коэффициент определяется следующим образом:
![]()
Где - условная дисперсия зависимой величины у
по фактору х
.
Коэффициент принимает значение на промежутке и чем он ближе к 1 тем сильнее зависимость.
Ну что же теперь можно перейти непосредственно к построению модели и выбору модели. Давайте поместим все наши модели в один список для удобства дальнейшего анализа:
Models =
Итак модели готовы, теперь мы разобьем наши исходные данные на 2 подвыборки: тестовую
и обучающую
. Кто читал мои предыдущие статьи знает, что сделать это можно с помощью функции train_test_split() из пакета scikit-learn:
Xtrn, Xtest, Ytrn, Ytest = train_test_split(trn, trg, test_size=0.4)
Теперь, т. к. нам надо спрогнозировать 2 параметра , надо построить регрессию для каждого из них. Кроме этого, для дальнейшего анализа, можно записать полученные результаты во временный DataFrame
. Сделать это можно так:
#создаем временные структуры
TestModels = DataFrame()
tmp = {}
#для каждой модели из списка
for model in models:
#получаем имя модели
m = str(model)
tmp["Model"] = m[:m.index("(")]
#для каждого столбцам результирующего набора
for i in xrange(Ytrn.shape):
#обучаем модель
model.fit(Xtrn, Ytrn[:,i])
#вычисляем коэффициент детерминации
tmp["R2_Y%s"%str(i+1)] = r2_score(Ytest[:,0], model.predict(Xtest))
#записываем данные и итоговый DataFrame
TestModels = TestModels.append()
#делаем индекс по названию модели
TestModels.set_index("Model", inplace=True)
Как можно заметить из кода выше, для расчета коэффициента используется функция r2_score().
Итак, данные для анализа получены. Давайте теперь построим графики и посмотрим какая модель показала лучший результат:
Fig, axes = plt.subplots(ncols=2, figsize=(10,4))
TestModels.R2_Y1.plot(ax=axes, kind="bar", title="R2_Y1")
TestModels.R2_Y2.plot(ax=axes, kind="bar", color="green", title="R2_Y2")

Анализ результатов и выводы
Из графиков, приведенных выше, можно сделать вывод, что лучше других с задачей справился метод RandomForest (случайный лес). Его коэффициенты детерминации выше остальных по обоим переменным:ля дальнейшего анализа давайте заново обучим нашу модель:
Model = models
model.fit(Xtrn, Ytrn)
При внимательном рассмотрении, может возникнуть вопрос, почему в предыдущий раз и делили зависимую выборку Ytrn
на переменные(по столбцам), а теперь мы этого не делаем.
Дело в том, что некоторые методы, такие как RandomForestRegressor
, может работать с несколькими прогнозируемыми переменными, а другие (например SVR
) могут работать только с одной переменной. Поэтому на при предыдущем обучении мы использовали разбиение по столбцам, чтобы избежать ошибки в процессе построения некоторых моделей.
Выбрать модель это, конечно же, хорошо, но еще неплохо бы обладать информацией, как каждый фактор влиет на прогнозное значение. Для этого у модели есть свойство feature_importances_
.
С помощью него, можно посмотреть вес каждого фактора в итоговой моделей:
Model.feature_importances_
array([ 0.40717901, 0.11394948, 0.34984766, 0.00751686, 0.09158358,
0.02992342])
В нашем случае видно, что больше всего на нагрузку при обогреве и охлаждении влияют общая высота и площадь. Их общий вклад в прогнозной модели около 72%.
Также необходимо отметить, что по вышеуказанной схеме можно посмотреть влияние каждого фактора отдельно на обогрев и отдельно на охлаждение, но т. к. эти факторы у нас очень тесно коррелируют между собой (), мы сделали общий вывод по ним обоим который и был написан выше.
Заключение
В статье я постарался показать основные этапы при регрессионном анализе данных с помощью Python и аналитческих пакетов pandas и scikit-learn .Необходимо отметить, что набор данных специально выбирался таким образом чтобы быть максимально формализованым и первичная обработка входных данных была бы минимальна. На мой взгляд статья будет полезна тем, кто только начинает свой путь в анализе данных, а также тем кто имеет хорошую теоретическую базу, но выбирает инструментарий для работы.
Предположим, что необходимо дать среднестатистический прогноз путевого расхода топлива автомобиля. Для этого имеется возможность воспользоваться множественным регрессионным анализом (на основе анализа параметров большого числа автомобилей) для оценки расхода топлива Q [л/100 км], с использованием следующих переменных (параметров):
m 1
– Объем двигателя автомобиля [см 3 ];
m 2
– Масса автомобиля [кГ];
m 3
– Тип привода, определяемый числом ведущих колес ;
m 4
– Мощность двигателя [л.с.].
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (m 1 , m 2 , m 3 и m 4 ) и зависимой переменной (Q ), то есть расходом топлива. Исходные данные показаны на рисунке.
Настройки для решения поставленной задачи показаны на рисунке окна "Регрессия". Результаты расчетов размещены на отдельном листе в таблице 6 .
В итоге получена следующая математическая модель:
Q = -0,002159246·x 1 + 0,001581937·x 2 + 1,987200675·x 3 + 0,078512695·x 4 - 4,428016498
Теперь можно определить примерный расход топлива у легкового автомобиля с бензиновым двигателем и колесной формулой 4 × 4, если известно, что двигатель автомобиля имеет объем 2700 см 3 , его масса составляет 1950 кг, автомобиль имеет полный привод на колеса – 4 ведущих колеса, мощность двигателя составляет 163 л.с., используя следующую формулу:
Q = -0,002159246·2700 - 0,001581937·1950 + 1,987200675·4 + 0,078512695·163 - 4,428016498
Решив это уравнение, получаем расход топлива у данного автомобиля: Q = 13,57 л/100 км.
В регрессионном анализе наиболее важными результатами являются:
· коэффициенты при переменных и Y-пересечение, являющиеся искомыми параметрами модели;
· множественный коэффициент R, характеризующий точность
модели для имеющихся исходных данных;
· F-критерий Фишера (в рассмотренном примере он значительно превосходит критическое значение, равное 3,54868E-09);
· t-статистика – величины, характеризующие степень значимости отдельных коэффициентов модели.
На t-статистике следует остановиться особо. Очень часто при построении регрессионной модели неизвестно, влияет ли тот или иной фактор Х на Y. Включение в модель факторов, которые не влияют на выходную величину, ухудшает качество модели. Вычисление t-статистики помогает обнаружить такие факторы. Приближенную оценку можно сделать так: если при n>>k величина t-статистики по абсолютному значению существенно больше трех, соответствующий коэффициент следует считать значимым, а фактор включить в модель. В противном случае его необходимо исключить из модели. Таким образом, можно предложить технологию построения регрессионной модели, состоящую из двух этапов:
1) обработать пакетом "Регрессия" все имеющиеся данные, проанализировать значения t-статистики;
2) удалить из таблицы исходных данных столбцы с теми факторами, для которых коэффициенты незначимы, и обработать пакетом "Регрессия" новую таблицу.
Для примера рассмотрим переменную m 4 . В справочнике по математической статистике t-критическое с (n-k-1) = 15-5-1=9 степенями свободы и доверительной вероятностью 0,95 равно 2,26. Поскольку абсолютная величина t, равная 4,17 больше, чем 2,26, мощность двигателя - это важная переменная для оценки расхода топлива. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных:
Из таблицы видно, что значения «Мощности двигателя – m 4 » и «Типа привода – m 3 » имеют абсолютную величину большую, чем 2,26 следовательно, эти переменные, использованные в уравнении регрессии, полезны для предсказания путевого расхода топлива автомобиля. А такие значения как «Масса автомобиля – m 2 » и «Объем двигателя – m 1 » имеют абсолютную величину меньшую чем 2,26. Следовательно, эти переменные, использованные в уравнении регрессии, необходимо исключить из модели. Это позволит повысить качество предсказания путевого расхода топлива автомобиля.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что называется научным исследованием;
2. Что является объектом научного исследования. Приведите примеры;
3. Что включает структура объекта научного исследования;
4. Формулирование цели и постановка задач научного исследования. Приведите примеры;
5. Какие виды научных исследований Вы знаете. Поясните их суть, достоинства и недостатки;
6. Структура экспериментального научного исследования;
7. Какие методики включает в себя экспериментальное научное исследование;
8. Поясните цель и содержание методики планирования экспериментального исследования;
9. Как определить объем выборки методом проверки статистических гипотез;
10. Устройство и тестовые возможности стендов с беговыми барабанами в процессе экспериментальных исследований на автомобильном транспорте;
11. Устройство и тестовые возможности стендов для исследования характеристик шин;
12. Устройство и тестовые возможности стендов для задания тестовых режимов при исследовании автомобильного двигателя;
13. Структура аналитического научного исследования на автомобильном транспорте;
14. Какое оборудование для задания тестовых режимов объектам исследования на автомобильном транспорте Вы знаете;
15. Как устанавливаются причинно-следственные связи на структурной схеме объекта исследования;
16. Как разрабатывается математическая модель исследуемого процесса;
17. Как осуществляется проверка адекватности и настройка математической модели;
18. Какие вопросы позволяет решать регрессионный анализ в процессе научных исследований на автомобильном транспорте;
19. Как построить модель множественной регрессии в среде MIKROSOFT EXCEL.
20. Начертите схему и поясните суть измерения сил тензометрическим методом;
21. Начертите схему и поясните суть измерения давления;
22. Начертите схему и поясните суть измерения моментов силы тензометрическим методом;
23. Как калибруется система измерения сил;
24. Начертите схему и поясните суть измерения интервалов времени цифровым методом;
25. Начертите схему и поясните суть измерения скорости вращения;
26. Начертите схему и поясните суть измерения угла поворота вала;
27. Начертите схему и поясните суть измерения угла поворота коленчатого вала двигателя;
28. Начертите схему и поясните суть измерения температуры при помощи сопротивления термопреобразователя;
29. Начертите схему и поясните суть измерения температуры при помощи термоэлектрического преобразователя (термопары);
30. Анализ температурных полей при помощи тепловизора;
31. Начертите схему и поясните суть стробоскопического метода измерения угла опережения зажигания;
32. Начертите схему и поясните суть гироскопического метода измерения углов;
33. Начертите схему и поясните работу расходомера топлива ротационного типа;
34. Начертите схему и поясните работу расходомера топлива объемного типа;
35. Начертите схему расходомера топлива объемного типа и поясните принцип его работы при измерении «мгновенного» и «путевого» расхода топлива;
36. Как осуществляется тарировка расходомера топлива;
37. Дайте определения понятию «абсолютная погрешность измерения». Как она определяется;
38. Дайте определения понятию «относительная погрешность измерения». Как она определяется;
39. Погрешности измерений. Как определяются абсолютная и относительная погрешности измерения силы тензометрическим методом;
40. Какое оборудование для визуализации результатов измерений Вы знаете;
41. Как устроен и как работает электронно-лучевой осциллограф;
42. Как осуществляется калибровка вертикальной шкалы электронно-лучевого осциллографа;
43. Как осуществляется калибровка горизонтальной шкалы электронно-лучевого осциллографа;
44. Аналого-цифровое преобразование. Приведите схему процесса и дайте пояснение;
45. Поясните метод кодирования чисел в виде сочетания нулей и единиц. Дайте определение понятию «логический ноль» и «логическая единица»;
46. Как строится гистограмма и кривая распределения случайной величины;
47. Как осуществляется обработка результатов измерений;
48. Как осуществляется анализ результатов экспериментального исследования;
49. Как выполняется аппроксимация данных функции с использованием метода наименьших квадратов;
50. Как аппроксимировать результаты экспериментального исследования в среде MIKROSOFT EXCEL. Дайте определение понятию «аппроксимация»;
51. Поясните суть коэффициента достоверности аппроксимации R 2 ;
52. Перечислите статистические характеристики случайной величины.
Список основной литературы:
1. Диагностика автомобиля: Учебник для вузов. // Федотов А.И., Изд-во ИрГТУ, Иркутск. 2012. 463 с. Ил. 273. Табл. 22. Библиограф.: 64 назв.
2. Электрические измерения физических величин: Методы измерения: Учебное пособие для вузов // С.А.Спектор., : Л. Энергоатомиздат. Ленинградское отделение,1987.- 320 с.
3. Основы технологии полигонных испытаний и сертификация автомобилей // Безверхий С.Ф., Яценко Н.Н., М.: ИПК Издательство стандартов, 1996. – 600
4. Прочность и долговечность автомобиля // Под общей ред. Б.В. Гольда, М., Машиностроение, 1974. 328 с., ил.
5. Статистическое оценивание и проверка гипотез на ЭВМ // Петрович М.Л., Давидович М.И. - М.: Финансы и статистика,1989. -191 с.: ил. (Мат. обеспечение прикладной статистики).
6. Методы оптимизации. Вводный курс // Банди Б.: Пер. с англ. – М.: Радио и связь, 1988. – 128 с.: ил.
7. Методы оптимизации в технической диагностике машин // Харазов А.М., Цвид С.Ф. М.: Машиностроение, 1983. – 132 с., ил.
8. Планирование эксперимента и анализ данных // Монтгомери Д., Пер. с англ. – Л.: Судостроение, 1980. – 384 с., ил.
9. Методы обработки экспериментальных данных при измерениях // Грановский В.А., Сирая Т.Н., Энергоатомиздат. Ленингр. отд-ние, 1990. – 288 с.: ил.
10. Шор. Я. Б. Статистические методы анализа и контроля качества и надежности. М.: Госэнергоиздат, 1962, с. 552, С. 92-98.
Список дополнительной литературы:
11. Диагностическое обеспечение технического обслуживания и ремонта автомобилей: Справ. пособие. – М.: Высш. шк., 1990. – 208 с.: ил.
12. Испытание автомобилей // Учебник для машиностроительных техникумов по специальности «Автомобилестроение» / Балабин И.В., Куров Б.А., Лаптев С.А. – 2-е изд., перераб. и доп. – М.: Машиностроение, 1988. – 192 с.: ил.
13. Технологическое оборудование для технического обслуживания и ремонта легковых автомобилей: Справочник/ Р.А. Попржедзинский, А.М. Харазов и др. – М.: Транспорт, 1988. – 176 с., ил., табл.
14. Измерения в электро- и радиотехнике: Учеб. Пособие. для средн. проф.-техн. училищ. – М.: Выс. шк., 1984. – 207 с., ил.
| Тема 1. Методологические основы научного познания и творчества ………… | |
| Формулирование цели и постановка задач исследования….……………………… | |
| Тема 2. Теоретические и эмпирические методы исследования………………………… | |
| Тема 3.Методика планирования экспериментального исследования ………………….. | |
| Тема 4.Оборудование для задания тестовых режимов………………………………….. | |
| Тема 5.Измерительные приборы и системы, используемые при проведении научных исследований ………………………………………………..………………………………. | |
| Измерение сил с помощью тензорезисторного моста ………………………………… | |
| Измерение крутящего момента ………………………………………………………………. | |
| Тарировка тензометрических измерителей силовых параметров ………………………. | |
| Тарировка тензометрических измерителей крутящего момента ……………….…… | |
| Измерение давления …………………………………………………………….…………………… | |
| Измерение интервалов времени …………….…………………………….…………………… | |
| Измерение скорости вращения ……………………………………….……………………. | |
| Измерение угла поворота вала …………………………………………………………………. | |
| Измерение скорости вращения коленчатого вала…………………………………………. | |
| Измерение температуры………………………………………………….……………………. . | |
| Термопреобразователи сопротивления………………………………………………….…… | |
| Термоэлектрические преобразователи………………………………………………….……… | |
| Анализ температурных полей………………………………………………….………………… | |
| Стробоскопический метод измерения угла опережения зажигания………….……… | |
| Гироскопический метод измерения углов………………………………….…………………. | |
| Измерение расхода топлива расходомером ротационного типа……………….……... | |
| Измерение расхода топлива расходомером поршневого типа ………………….……. | |
| Измерение мгновенного расхода топлива.………………………………….……………… | |
| Измерение путевого расхода топлива.……………………………… ….…………………… | |
| Тарировка расходомеров топлива.……………………………………………………………… | |
| Тема 6.Оборудование для визуализации результатов измерений ………………………. | |
| Тема 7.Аналого-цифровое преобразование измеряемых сигналов ……………………. | |
| Метрологические характеристики аналого-цифрового преобразования …………... | |
| ТЕМА 8. Теория и методология научно-технического творчества ………………….. | |
| Прикладные методы математической обработки экспериментальных данных ……. | |
| ТЕМА 9. Аналитические научные исследования на автомобильном транспорте ……. | |
| Проверка адекватности математической модели …………………….……………….…. | |
| Тема10. Аппроксимация данных с использованием метода наименьших квадратов | |
| Построение трендовых моделей при помощи диаграмм ……………………………….. | |
| Коэффициент достоверности аппроксимации R 2 …………………………………………….. | |
| Тема11. Регрессионный анализ ……………………………………………………………….. | |
| Контрольные вопросы ………………………………………………………………………………. | |
| Список литературы…………………………………………………………………………………… | |
| Оглавление |
Федотов Александр Иванович
ОСНОВЫ НАУЧНЫХ ИССЛЕДОВАНИЙ
Учебно-методическое пособие
для студентов вузов, обучающихся по профилю «Эксплуатация транспортно-технологических машин и комплексов», направления подготовки 190600.62 эксплуатация транспортно-технологических машин и комплексов, квалификации – «магистр», а также 190600.68 степени - «магистр»
Подписано в печать 2015. Формат 60х84 1/16
Бумага типографская. Печать офсетная. Усл. печ. л. 6,25
Уч.- изд. л. 5,9 Тираж 200 экз. Зак
ИД № 06506 от 26.12.2001
Материал будет проиллюстрирован сквозным примером: прогнозирование объемов продаж компании OmniPower. Представьте себе, что вы - менеджер по маркетингу в крупной национальной сети бакалейных магазинов. В последние годы на рынке появились питательные батончики, содержащие большое количество жиров, углеводов и калорий. Они позволяют быстро восстановить запасы энергии, потраченной бегунами, альпинистами и другими спортсменами на изнурительных тренировках и соревнованиях. За последние годы объем продаж питательных батончиков резко вырос, и руководство компании OmniPower пришло к выводу, что этот сегмент рынка весьма перспективен. Прежде чем предлагать новый вид батончика на общенациональном рынке, компания хотела бы оценить влияние его стоимости и рекламных затрат на объем продаж. Для маркетингового исследования были отобраны 34 магазина. Вам необходимо создать регрессионную модель, позволяющую проанализировать данные, полученные в ходе исследования. Можно ли применить для этого модель простой линейной регрессии, рассмотренную в предыдущей заметке? Как ее следует изменить?
Модель множественной регрессии
Для маркетингового исследования в компании OmniPower была создана выборка, состоящая из 34 магазинов с приблизительно одинаковыми объемами продаж. Рассмотрим две независимые переменные - цена батончика OmniPower в центах (Х 1 ) и месячный бюджет рекламной кампании, проводимой в магазине, выраженный в долларах (Х 2 ). В этот бюджет входят расходы на оформление вывесок и витрин, а также на раздачу купонов и бесплатных образцов. Зависимая переменная Y представляет собой количество батончиков OmniPower, проданных за месяц (рис. 1).
Рис. 1. Месячный объем продажа батончиков OmniPower, их цена и расходы на рекламу
Скачать заметку в формате или , примеры в формате
Интерпретация регрессионных коэффициентов. Если в задаче исследуются несколько объясняющих переменных, модель простой линейной регрессии можно расширить, предполагая, что между откликом и каждой из независимых переменных существует линейная зависимость. Например, при наличии k объясняющих переменных модель множественной линейной регрессии принимает вид:
(1) Y i = β 0 + β 1 X 1i + β 2 X 2i + … + β k X ki + ε i
где β 0 - сдвиг, β 1 - наклон прямой Y , зависящей от переменной Х 1 , если переменные Х 2 , Х 3 , … , Х k являются константами, β 2 - наклон прямой Y , зависящей от переменной Х 2 , если переменные Х 1 , Х 3 , … , Х k являются константами, β k - наклон прямой Y , зависящей от переменной Х k , если переменные Х 1 , Х 2 , … , Х k-1 являются константами, ε i Y в i -м наблюдении.
В частности, модель множественной регрессии с двумя объясняющими переменными:
(2) Y i = β 0 + β 1 X 1 i + β 2 X 2 i + ε i
где β 0 - сдвиг, β 1 - наклон прямой Y , зависящей от переменной Х 1 , если переменная Х 2 является константой, β 2 - наклон прямой Y , зависящей от переменной Х 2 , если переменная Х 1 является константой, ε i - случайная ошибка переменной Y в i -м наблюдении.
Сравним эту модель множественной линейной регрессии и модель простой линейной регрессии: Y i = β 0 + β 1 X i + ε i . В модели простой линейной регрессии наклон β 1 Y при изменении значения переменной X на единицу и не учитывает влияние других факторов. В модели множественной регрессии с двумя независимыми переменными (2) наклон β 1 представляет собой изменение среднего значения переменной Y при изменении значения переменной X 1 на единицу с учетом влияния переменной Х 2 . Эта величина называется коэффициентом чистой регрессии (или частной регрессии).
Как и в модели простой линейной регрессии, выборочные регрессионные коэффициенты b 0 , b 1 , и b 2 представляют собой оценки параметров соответствующей генеральной совокупности β 0 , β 1 и β 2 .
Уравнение множественной регрессии с двумя независимыми переменными:
(3) = b 0 + b 1 X 1 i + b 2 X 2 i
Для вычисления коэффициентов регрессии используется метод наименьших квадратов. В Excel можно воспользоваться Пакетом анализа , опцией Регрессия . В отличие от построения линейной регрессии, просто задайте в качестве Входного интервала Х область, включающую все независимые переменные (рис. 2). В нашем примере это $C$1:$D$35.

Рис. 2. Окно Регрессия Пакета анализа Excel
Результаты работы Пакета анализа представлены на рис. 3. Как видим, b 0 = 5 837,52, b 1 = –53,217 и b 2 = 3,163. Следовательно, = 5 837,52 –53,217 X 1 i + 3,163 X 2 i , где Ŷ i - предсказанный объем продаж питательных батончиков OmniPower в i -м магазине (штук), Х 1 i - цена батончика (в центах) в i -м магазине, Х 2i - ежемесячные затраты на рекламу в i -м магазине (в долларах).

Рис. 3. Множественная регрессия исследования объем продажа батончиков OmniPower
Выборочный наклон b 0 равен 5 837,52 и является оценкой среднего количества батончиков OmniPower, проданных за месяц при нулевой цене и отсутствии затрат на рекламу. Поскольку эти условия лишены смысла, в данной ситуации величина наклона b 0 не имеет разумной интерпретации.
Выборочный наклон b 1 равен –53,217. Это значит, что при заданном ежемесячном объеме затрат на рекламу увеличение цены батончика на один цент приведет к снижению ожидаемого объема продаж на 53,217 штук. Аналогично выборочный наклон b 2 , равный 3,613, означает, что при фиксированной цене увеличение ежемесячных рекламных затрат на один доллар сопровождается увеличением ожидаемого объема продаж батончиков на 3,613 шт. Эти оценки позволяют лучше понять влияние цены и рекламы на объем продаж. Например, при фиксированном объеме затрат на рекламу уменьшение цены батончика на 10 центов увеличит объем продаж на 532,173 шт., а при фиксированной цене батончика увеличение рекламных затрат на 100 долл. увеличит объем продаж на 361,31 шт.
Интерпретация наклонов в модели множественной регрессии. Коэффициенты в модели множественной регрессии называются коэффициентами чистой регрессии. Они оценивают среднее изменение отклика Y при изменении величины X на единицу, если все остальные объясняющие переменные «заморожены». Например, в задаче о батончиках OmniPower магазин с фиксированным объемом рекламных затрат за месяц продаст на 53,217 батончика меньше, если увеличит их стоимость на один цент. Возможна еще одна интерпретация этих коэффициентов. Представьте себе одинаковые магазины с одинаковым объемом затрат на рекламу. При уменьшении цены батончика на один цент объем продаж в этих магазинах увеличится на 53,217 батончика. Рассмотрим теперь два магазина, в которых батончики стоят одинаково, но затраты на рекламу отличаются. При увеличении этих затрат на один доллар объем продаж в этих магазинах увеличится на 3,613 штук. Как видим, разумная интерпретация наклонов возможна лишь при определенных ограничениях, наложенных на объясняющие переменные.
Предсказание значений зависимой переменной Y. Выяснив, что накопленные данные позволяют использовать модель множественной регрессии, мы можем прогнозировать ежемесячный объем продаж батончиков OmniPower и построить доверительные интервалы для среднего и предсказанного объемов продаж. Для того чтобы предсказать средний ежемесячный объем продаж батончиков OmniPower по цене 79 центов в магазине, расходующем на рекламу 400 долл. в месяц, следует применить уравнение множественной регрессии: Y = 5 837,53 – 53,2173*79 + 3,6131*400 = 3 079. Следовательно, ожидаемый объем продаж в магазинах, торгующих батончиками OmniPower по цене 79 центов и расходующих на рекламу 400 долл. в месяц, равен 3 079 шт.
Вычислив величину Y и оценив остатки, можно построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика. мы рассмотрели эту процедуру в рамках модели простой линейной регрессии. Однако построение аналогичных оценок для модели множественной регрессии сопряжено с большими вычислительными трудностями и здесь не приводится.
Коэффициент множественной смешанной корреляции. Напомним, что модель регрессии позволяет вычислить коэффициент смешанной корреляции r 2 . Поскольку в модели множественной регрессии существуют по крайней мере две объясняющие переменные, коэффициент множественной смешанной корреляции представляет собой долю вариации переменной Y , объясняемой заданным набором объясняющих переменных:
![]()
где SSR – сумма квадратов регрессии, SST – полная сумма квадратов.
Например, в задаче о продажах батончика OmniPower SSR = 39 472 731, SST = 52 093 677 и k = 2. Таким образом,
Это означает, что 75,8% вариации объемов продаж объясняется изменениями цен и колебаниями объемов затрат на рекламу.
Анализ остатков для модели множественной регрессии
Анализ остатков позволяет определить, можно ли применять модель множественной регрессии с двумя (или более) объясняющими переменными. Как правило, проводят следующие виды анализа остатков:
Первый график (рис. 4а) позволяет проанализировать распределение остатков в зависимости от предсказанных значений . Если величина остатков не зависит от предсказанных значений и принимает как положительные так и отрицательные значения (как в нашем пример), условие линейной зависимости переменной Y от обеих объясняющих переменных выполняется. К сожалению, в Пакете анализа этот график почему-то не создается. Можно в окне Регрессия (см. рис. 2) включить Остатки . Это позволит вывести таблицу с остатками, а уже по ней построить точечный график (рис. 4).

Рис. 4. Зависимость остатков от предсказанного значения
Второй и третий график демонстрируют зависимость остатков от объясняющих переменных. Эти графики могут выявить квадратичный эффект. В этой ситуации необходимо добавить в модель множественной регрессии квадрат объясняющей переменной. Эти графики выводятся Пакетом анализа (см. рис. 2), если включить опцию График остатков (рис. 5).

Рис. 5. Зависимость остатков от цены и затрат на рекламу
Проверка значимости модели множественной регрессии.
Убедившись с помощью анализа остатков, что модель линейной множественной регрессии является адекватной, можно определить, существует ли статистически значимая взаимосвязь между зависимой переменной и набором объясняющих переменных. Поскольку в модель входит несколько объясняющих переменных, нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = β 2 = … = β k = 0 (между откликом и объясняющими переменными нет линейной зависимости), Н 1: существует по крайней мере одно значение β j ≠ 0 (мжду откликом и хотя бы одной объясняющей переменной существует линейная зависимость).
Для проверки нулевой гипотезы применяется F -критерий – тестовая F -статистика равна среднему квадрату, обусловленному регрессией (MSR), деленному на дисперсию ошибок (MSE):
![]()
где F F -распределение с k и n – k – 1 степенями свободы, k – количество независимых переменных в регрессионной модели.
Решающее правило выглядит следующим образом: при уровне значимости α нулевая гипотеза Н 0 отклоняется, если F > F U(k,n – k – 1) , в противном случае гипотеза Н 0 не отклоняется (рис. 6).

Рис. 6. Сводная таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициентов множественной регрессии
Сводная таблица дисперсионного анализа, заполненная с использованием Пакета анализа Excel при решении задачи о продажах батончиков OmniPower, показана на рис. 3 (см. область А10:F14). Если уровень значимости равен 0,05, критическое значение F -распределения с двумя и 31 степенями свободы F U(2,31) = F.ОБР(1-0,05;2;31) = равно 3,305 (рис. 7).

Рис. 7. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости α = 0,05, с 2 и 31 степенями свободы
Как показано на рис. 3, F-статистика равна 48,477 > F U(2,31) = 3,305, а p -значение близко к 0,000 < 0,05. Следовательно, нулевая гипотеза Н 0 отклоняется, и объем продаж линейно связан хотя бы с одной из объясняющих переменных (ценой и/или затратами на рекламу).
Статистические выводы о генеральной совокупности коэффициентов регрессии
Чтобы выявить статистически значимую зависимость между переменными X и Y в модели простой линейной регрессии, была выполнена проверка гипотезы о наклоне. Кроме того, для оценки наклона генеральной совокупности был построен доверительный интервал (см. ).
Проверка гипотез. Для проверки гипотезы, утверждающей, что наклон генеральной совокупности β 1 , в модели простой линейной регрессии равен нулю, используется формула t = (b 1 – β 1)/S b 1 . Ее можно распространить на модель множественной регрессии:

где t – тестовая статистика, имеющая t -распределение с n – k – 1 степенями свободы, b j - наклон переменной х j по отношению к переменной Y , если все остальные объясняющие переменные являются константами, S bj – среднеквадратичная ошибка регрессионного коэффициента b j , k - количество объясняющих переменных в уравнении регрессии, β j - гипотетический наклон генеральной совокупности откликов j -й относительно переменной, когда все остальные переменные фиксированы.
На рис. 3 (нижняя таблица) показаны результаты применения t -критерия (полученные с помощью Пакета анализа ) для каждой из независимых переменных, включенных в регрессионную модель. Таким образом, если необходимо определить, оказывает ли переменная Х 2 (затраты на рекламу) существенное влияние на объем продаж при фиксированной цене батончика OmniPower, формулируются нулевая и альтернативная гипотезы: Н 0: β2 = 0, Н 1: β2 ≠ 0. В соответствии с формулой (6) получаем:
![]()
Если уровень значимости равен 0,05, критическими значениями t -распределения с 31 степенями свободы являются t L = СТЬЮДЕНТ.ОБР(0,025;31) = –2,0395 и t U = СТЬЮДЕНТ.ОБР(0,975;31) = 2,0395 (рис. 8). р -значение =1-СТЬЮДЕНТ.РАСП(5,27;31;ИСТИНА) и близко к 0,0000. На основании одного из неравенств t = 5,27 > 2,0395 или р = 0,0000 < 0,05 нулевая гипотеза Н 0 отклоняется. Следовательно, при фиксированной цене батончика между переменной Х 2 (затраты на рекламу) и объемом продаж существует статистически значимая зависимость. Таким образом, существует чрезвычайно малая вероятность отвергнуть нулевую гипотезу, если между затратами на рекламу и объемами продаж нет линейной зависимости.

Рис. 8. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости α = 0,05, с 31 степенью свободы
Проверка значимости конкретных коэффициентов регрессии фактически представляет собой проверку гипотезы о значимости конкретной переменной, включенной в регрессионную модель наряду с другими. Следовательно, t -критерий для проверки гипотезы о значимости регрессионного коэффициента эквивалентен проверке гипотезы о влиянии каждой из объясняющих переменных.
Доверительные интервалы. Вместо проверки гипотезы о наклоне генеральной совокупности можно оценить значение этого наклона. В модели множественной регрессии для построения доверительного интервала используется формула:
(7) b j ± t n – k –1 S bj
Воспользуемся этой формулой для того, чтобы построить 95%-ный доверительный интервал, содержащий наклон генеральной совокупности β 1 (влияние цены X 1 на объем продаж Y при фиксированном объеме затрат на рекламу Х 2 ). По формуле (7) получаем: b 1 ± t n – k –1 S b 1 . Поскольку b 1 = –53,2173 (см. рис. 3), S b 1 = 6,8522, критическое значение t -статистики при 95%-ном доверительном уровне и 31 степени свободы t n – k –1 =СТЬЮДЕНТ.ОБР(0,975;31) = 2,0395, получаем:
–53,2173 ± 2,0395*6,8522
–53,2173 ± 13,9752
–67,1925 ≤ β 1 ≤ –39,2421
Таким образом, учитывая эффект затрат на рекламу, можно утверждать, что при увеличении цены батончика на один цент объем продаж уменьшается на величину, которая колеблется от 39,2 до 67,2 шт. Существует 95%-ная вероятность, что этот интервал правильно оценивает зависимость между двумя переменными. Поскольку данный доверительный интервал не содержит нуля, можно утверждать, что регрессионный коэффициент β 1 имеет статистически значимое влияние на объем продаж.
Оценка значимости поясняющих переменных в модели множественной регрессии
В модель множественной регрессии следует включать только те объясняющие переменные, которые позволяют точно предсказать значение зависимой переменной. Если какая-либо из объясняющих переменных не соответствует этому требованию, ее нужно удалить из модели. В качестве альтернативного метода, позволяющего оценить вклад объясняющей переменной, как правило, применяется частный F -критерий. Он заключается в оценке изменения суммы квадратов регрессии после включения в модель очередной переменной. Новая переменная включается в модель лишь тогда, когда это приводит к значительному увеличению точности предсказания.
Для того чтобы применить частный F-критерий для решения задачи о продажах батончика OmniPower, необходимо оценить вклад переменной Х 2 (затраты на рекламу) после включения в модель переменной X 1 (цена батончика). Если в модель входят несколько поясняющих переменных, вклад объясняющей переменной х j можно определить, исключив ее из модели и оценив сумму квадратов регрессии (SSR), вычисленную по оставшимся переменным. Если в модель входят две переменные, вклад каждой из них определяется по формулам:
Оценка вклада переменной Х 1 Х 2 :
(8а) SSR(X 1 |Х 2) = SSR(X 1 и Х 2) – SSR(X 2)
Оценка вклада переменной Х 2 при условии, что в модель включена переменная Х 1 :
(8б) SSR(X 2 |Х 1) = SSR(X 1 и Х 2) – SSR(X 1)
Величины SSR(X 2) и SSR(X 1 ) соответственно представляют собой суммы квадратов регрессии, вычисленных только по одной из объясняемых переменных (рис. 9).

Рис. 9. Коэффициенты модели простой линейной регрессии, учитывающей: (а) объем продаж и цену батончика – SSR(X 1) ; (б) объем продаж и затраты на рекламу – SSR(X 2) (получены с помощью Пакета анализа Excel)
Нулевая и альтернативная гипотезы о вкладе переменной Х 1 формулируются следующим образом: Н 0 - включение переменной Х 1 не приводит к значительному увеличению точности модели, в которой учитывается переменная Х 2 ; Н 1 - включение переменной Х 1 приводит к значительному увеличению точности модели, в которой учтена переменная Х 2 . Статистика, положенная в основу частного F -критерия для двух переменных, вычисляется по формуле:

где MSE – дисперсия ошибки (остатка) для двух факторов одновременно. По определению F -статистика имеет F -распределение с одной и n –k–1 степенями свободы.
Итак, SSR(X 2) = 14 915 814 (рис. 9), SSR(X 1 и Х 2) = 39 472 731 (рис. 3, ячейка С12). Следовательно, по формуле (8а) получаем: SSR(X 1 |Х 2) = SSR(X 1 и Х 2) – SSR(X 2) = 39 472 731 – 14 915 814 = 24 556 917. Итак, для SSR(X 1 |Х 2) = 24 556 917 и MSE (X 1 и Х 2) = 407 127 (рис. 3, ячейка D13), используя формулу (9), получаем: F = 24 556 917 / 407 127 = 60,32. Если уровень значимости равен 0,05, то критическое значение F -распределения с одной и 31 степенями свободы =F.ОБР(0,95;1;31) = 4,16 (рис. 10).

Рис. 10. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости, равном 0,05, с одной и 31 степенями свободы
Поскольку вычисленное значение F -статистики больше критического (60,32 > 4,17), гипотеза Н 0 отклоняется, следовательно, учет переменной Х 1 (цены) значительно улучшает модель регрессии, в которую уже включена переменная Х 2 (затраты на рекламу).
Аналогично можно оценить влияние переменной Х 2 (затраты на рекламу) на модель, в которую уже включена переменная Х 1 (цена). Проведите вычисления самостоятельно. Решающее условие приводит к тому, что 27,8 > 4,17, и следовательно, включение переменной Х 2 также приводит к значительному увеличению точности модели, в которой учитывается переменная Х 1 . Итак, включение каждой из переменных повышает точность модели. Следовательно, в модель множественной регрессии необходимо включить обе переменные: и цену, и затраты на рекламу.
Любопытно, что значение t -статистики, вычисленное по формуле (6), и значение частной F -статистики, заданной формулой (9), однозначно взаимосвязаны:
![]()
где а - количество степеней свободы.
Регрессионные модели с фиктивной переменной и эффекты взаимодействия
Обсуждая модели множественной регрессии, мы предполагали, что каждая независимая переменная является числовой. Однако во многих ситуациях в модель необходимо включать категорийные переменные. Например, в задаче о продажах батончиков OmniPower для предсказания среднемесячного объема продаж использовались цена и затраты на рекламу. Кроме этих числовых переменных, можно попытаться учесть в модели расположение товара внутри магазина (например, на витрине или нет). Для того чтобы учесть в регрессионной модели категорийные переменные, следует включить в нее фиктивные переменные. Например, если некая категорийная объясняющая переменная имеет две категории, для их представления достаточно одной фиктивной переменной X d : X d = 0, если наблюдение принадлежит первой категории, X d = 1, если наблюдение принадлежит второй категории.
Для иллюстрации фиктивных переменных рассмотрим модель для предсказания средней оценочной стоимости недвижимости на основе выборки, состоящей из 15 домов. В качестве объясняющих переменных выберем жилую площадь дома (тыс. кв. футов) и наличие камина (рис. 11). Фиктивная переменная Х 2 (наличие камина) определена следующим образом: Х 2 = 0, если камина в доме нет, Х 2 = 1, если в доме есть камин.

Рис. 11. Оценочная стоимость, предсказанная по жилой площади и наличию камина
Предположим, что наклон оценочной стоимости, зависящей от жилой площади, одинаков у домов, имеющих камин и не имеющих его. Тогда модель множественной регрессии выглядит следующим образом:
Y i = β 0 + β 1 X 1i + β 2 X 2i + ε i
где Y i - оценочная стоимость i -гo дома, измеренная в тысячах долларов, β 0 - сдвиг отклика, X 1 i ,- жилая площадь i -гo дома, измеренная в тыс. кв. футов, β 1 - наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной, X 1 i ,- фиктивная переменная, означающая наличие или отсутствие камина, β 1 - наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной β 2 - эффект увеличения оценочной стоимости дома в зависимости от наличия камина при постоянной величине жилой площади, ε i – случайная ошибка оценочной стоимости i -гo дома. Результаты вычисления регрессионой модели представлены на рис. 12.

Рис. 12. Результаты вычисления регрессионой модели для оценочной стоимости домов; получены с помощью Пакета анализа в Excel; для расчета использована таблица, аналогичная рис. 11, с единственным изменением: «Да» заменены единицами, а «Нет» – нулями

В этой модели коэффициенты регрессии интерпретируются следующим образом:
- Если фиктивная переменная имеет постоянное значение, увеличение жилой площади на 1000 кв. футов приводит к увеличению предсказанной средней оценочной стоимости на 16,2 тыс. долл.
- Если жилая площадь постоянна, наличие камина увеличивает среднюю оценочную стоимость дома на 3,9 тыс. долл.
Обратите внимание (рис. 12), t -статистика, соответствующая жилой площади, равна 6,29, а р -значение почти равно нулю. В то же время t -статистика, соответствующая фиктивной переменной, равна 3,1, а p -значение – 0,009. Таким образом, каждая из этих двух переменных вносит существенный вклад в модель, если уровень значимости равен 0,01. Кроме того, коэффициент множественной смешанной корреляции означает, что 81,1% вариации оценочной стоимости объясняется изменчивостью жилой площади дома и наличием камина.
Эффект взаимодействия. Во всех регрессионных моделях, рассмотренных выше, считалось, что влияние отклика на объясняющую переменную является статистически независимым от влияния отклика на другие объясняющие переменные. Если это условие не выполняется, возникает взаимодействие между зависимыми переменными. Например, вполне вероятно, что реклама оказывает большое влияние на объем продаж товаров, имеющих низкую цену. Однако, если цена товара слишком высока, увеличение расходов на рекламу не может существенно повысить объем продаж. В этом случае наблюдается взаимодействие между ценой товара и затратами на его рекламу. Иначе говоря, нельзя делать общих утверждений о зависимости объема продаж от затрат на рекламу. Влияние рекламных расходов на объем продаж зависит от цены. Это влияние учитывается в модели множественной регрессии с помощью эффекта взаимодействия. Для иллюстрации этого понятия вернемся к задаче о стоимости домов.
В разработанной нами регрессионной модели предполагалось, что влияние размера дома на его стоимость не зависит от того, есть ли в доме камин. Иначе говоря, считалось, что наклон оценочной стоимости, зависящей от жилой площади дома, одинаков у домов, имеющих камин и не имеющих его. Если эти наклоны отличаются друг от друга, между размером дома и наличием камина существует взаимодействие.
Проверка гипотезы о равенстве наклонов сводится к оценке вклада, который вносит в модель регрессии произведение объясняющей переменной X 1 и фиктивной переменной Х 2 . Если этот вклад является статистически значимым, исходную модель регрессии применять нельзя. Результаты регрессионного анализа, включающего переменные Х 1 , Х 2 и Х 3 = Х 1 *Х 2 приведены на рис. 13.

Рис. 13. Результаты, полученные с помощью Пакета анализа Excel для регрессионной модели, учитывающей жилую площадь, наличие камина и их взаимодействие
Для того чтобы проверить нулевую гипотезу Н 0: β 3 = 0 и альтернативную гипотезу Н 1: β 3 ≠ 0, используя результаты, приведенные на рис. 13, обратим внимание на то, что t -статистика, соответствующая эффекту взаимодействия переменных, равна 1,48. Поскольку р -значение равно 0,166 > 0,05, нулевая гипотеза не отклоняется. Следовательно, взаимодействие переменных не имеет существенного влияния на модель регрессии, учитывающую жилую площадь и наличие камина.
Резюме. В заметке показано, как менеджер по маркетингу может применять множественный линейный анализ для предсказания объема продаж, зависящего от цены и затрат на рекламу. Рассмотрены различные модели множественной регрессии, включая квадратичные модели, модели с фиктивными переменными и модели с эффектами взаимодействия (рис. 14).

Рис. 14. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 873–936
Задачей множественной линейной регрессии является построение линейной модели связи между набором непрерывных предикторов и непрерывной зависимой переменной. Часто используется следующее регрессионное уравнение:
Здесь а i - регрессионные коэффициенты, b 0 - свободный член(если он используется), е - член, содержащий ошибку - по поводу него делаются различные предположения, которые, однако, чаще сводятся к нормальности распределения с нулевым вектором мат. ожидания и корреляционной матрицей .
Такой линейной моделью хорошо описываются многие задачи в различных предметных областях, например, экономике, промышленности, медицине. Это происходит потому, что некоторые задачи линейны по своей природе.
Приведем простой пример. Пусть требуется предсказать стоимость прокладки дороги по известным ее параметрам. При этом у нас есть данные о уже проложенных дорогах с указанием протяженности, глубины обсыпки, количества рабочего материала, числе рабочих и так далее.
Ясно, что стоимость дороги в итоге станет равной сумме стоимостей всех этих факторов в отдельности. Потребуется некоторое количество, например, щебня, с известной стоимостью за тонну, некоторое количество асфальта также с известной стоимостью.
Возможно, для прокладки придется вырубать лес, что также приведет к дополнительным затратам. Все это вместе даст стоимость создания дороги.
При этом в модель войдет свободный член, который, например, будет отвечать за организационные расходы (которые примерно одинаковы для всех строительно-монтажных работ данного уровня) или налоговые отчисления.
Ошибка будет включать в себя факторы, которые мы не учли при построении модели (например, погоду при строительстве - ее вообще учесть невозможно).
Пример: множественный регрессионный анализ
Для этого примера будут анализироваться несколько возможных корреляций уровня бедности и степень, которая предсказывает процент семей, находящихся за чертой бедности. Следовательно мы будем считать переменную характерезующую процент семей, находящихся за чертой бедности, - зависимой переменной, а остальные переменные непрерывными предикторами.
Коэффициенты регрессии
Чтобы узнать, какая из независимых переменных делает больший вклад в предсказание уровня бедности, изучим стандартизованные коэффициенты (или Бета) регрессии.

Рис. 1. Оценки параметров коэффициентов регрессии.
Коэффициенты Бета это коэффициенты, которые вы бы получили, если бы привели все переменные к среднему 0 и стандартному отклонению 1. Следовательно величина этих Бета коэффициентов позволяет сравнивать относительный вклад каждой независимой переменной в зависимую переменную. Как видно из Таблицы, показанной выше, переменные изменения населения с 1960 года (POP_ CHING), процент населения, проживающего в деревне (PT_RURAL) и число людей, занятых в сельском хозяйстве (N_Empld) являются самыми главными предикторами уровня бедности, т.к. только они статистически значимы (их 95% доверительный интервал не включает в себя 0). Коэффициент регрессии изменения населения с 1960 года (Pop_Chng) отрицательный, следовательно, чем меньше возрастает численность населения, тем больше семей, которые живут за чертой бедности в соответствующем округе. Коэффициент регрессии для населения (%), проживающего в деревне (Pt_Rural) положительный, т.е., чем больше процент сельских жителей, тем больше уровень бедности.
Значимость эффектов предиктора
Просмотрим Таблицу с критериями значимости.

Рис. 2. Одновременные результаты для каждой заданной переменной.
Как показывает эта Таблица, статистически значимы только эффекты 2 переменных: изменение населения с 1960 года (Pop_Chng) и процент населения, проживающего в деревне (Pt_Rural), p < .05.
Анализ остатков. После подгонки уравнения регрессии, почти всегда нужно проверять предсказанные значения и остатки. Например, большие выбросы могут сильно исказить результаты и привести к ошибочным выводам.
Построчный график выбросов
Обычно необходимо проверять исходные или стандартизованные остатки на большие выбросы.

Рис. 3. Номера наблюдений и остатки.
Шкала вертикальной оси этого графика отложена по величине сигма, т.е., стандартного отклонения остатков. Если одно или несколько наблюдений не попадают в интервал ± 3 умноженное на сигма, то, возможно, стоит исключить эти наблюдения (это можно легко сделать через условия выбора наблюдений) и еще раз запустить анализ, чтобы убедится, что результаты не изменяются этими выбросами.
Расстояния Махаланобиса
Большинство статистических учебников уделяют много времени выбросам и остаткам относительно зависимой переменной. Тем не менее роль выбросов в предикторах часто остается не выявленной. На стороне переменной предиктора имеется список переменных, которые участвуют с различными весами (коэффициенты регрессии) в предсказании зависимой переменной. Можно считать независимые переменные многомерным пространством, в котором можно отложить любое наблюдение. Например, если у вас есть две независимых переменных с равными коэффициентами регрессии, то можно было бы построить диаграмму рассеяния этих двух переменных и поместить каждое наблюдение на этот график. Потом можно было отметить на этом графике среднее значение и вычислить расстояния от каждого наблюдения до этого среднего (так называемый центр тяжести) в двумерном пространстве. В этом и заключается основная идея вычисления расстояния Махаланобиса . Теперь посмотрим на гистограмму переменной изменения населения с 1960 года.

Рис. 4. Гистограмма распределения расстояний Махаланобиса.
Из графика следует, что есть один выброс на расстояниях Махаланобиса.

Рис. 5. Наблюдаемые, предсказанные и значения остатков.
Обратите внимание на то, что округ Shelby (в первой строке) выделяется на фоне остальных округов. Если посмотреть на исходные данные, то вы обнаружите, что в действительности округ Shelby имеет самое большое число людей, занятых в сельском хозяйстве (переменная N_Empld). Возможно, было бы разумным выразить в процентах, а не в абсолютных числах, и в этом случае расстояние Махаланобиса округа Shelby, вероятно, не будет таким большим на фоне других округов. Очевидно, что округ Shelby является выбросом .
Удаленные остатки
Другой очень важной статистикой, которая позволяет оценить серьезность проблемы выбросов, являются удаленные остатки . Это стандартизованные остатки для соответствующих наблюдений, которые получаются при удалении этого наблюдения из анализа. Помните, что процедура множественной регрессии подгоняет поверхность регрессии таким образом, чтобы показать взаимосвязь между зависимой и переменной и предиктором. Если одно наблюдение является выбросом (как округ Shelby), то существует тенденция к "оттягиванию" поверхности регрессии к этому выбросу. В результате, если соответствующее наблюдение удалить, будет получена другая поверхность (и Бета коэффициенты). Следовательно, если удаленные остатки очень сильно отличаются от стандартизованных остатков, то у вас будет повод считать, что регрессионный анализа серьезно искажен соответствующим наблюдением. В этом примере удаленные остатки для округа Shelby показывают, что это выброс, который серьезно искажает анализ. На диаграмме рассеяния явно виден выброс.

Рис. 6. Исходные остатки и Удаленные остатки переменной, означающей процент семей, проживающих ниже прожиточного минимума.
Большинство из них имеет более или менее ясные интерпретации, тем не менее обратимся к нормальным вероятностным графикам.
Как уже было упомянуто, множественная регрессия предполагает, что существует линейная взаимосвязь между переменными в уравнении и нормальное распределение остатков. Если эти предположения нарушены, то вывод может оказаться неточным. Нормальный вероятностный график остатков укажет вам, имеются ли серьезные нарушения этих предположений или нет.

Рис. 7. Нормальный вероятностный график; Исходные остатки.
Этот график был построен следующим образом. Вначале стандартизованные остатки ранжируюся по порядку. По этим рангам можно вычислить z значения (т.е. стандартные значения нормального распределения) на основе предположения, что данные подчиняются нормальному распределению. Эти z значения откладываются по оси y на графике.
Если наблюдаемые остатки (откладываемые по оси x) нормально распределены, то все значения легли бы на прямую линию на графике. На нашем графике все точки лежат очень близко относительно кривой. Если остатки не являются нормально распределенными, то они отклоняются от этой линии. Выбросы также становятся заметными на этом графике.
Если имеется потеря согласия и кажется, что данные образуют явную кривую (например, в форме буквы S) относительно линии, то зависимую переменную можно преобразовать некоторым способом (например, логарифмическое преобразование для "уменьшения" хвоста распределения и т.д.). Обсуждение этого метода находится за пределами этого примера (Neter, Wasserman, и Kutner, 1985, pp. 134-141, представлено обсуждение преобразований, убирающих ненормальность и нелинейность данных). Однако исследователи очень часто просто проводят анализ напрямую без проверки соответствующих предположений, что ведет к ошибочным выводам.







