
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F (x ) и эмпирическим распределением F * п (x ) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i - й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F (x ) и F * п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k = M – S –1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k ; a ) , где χ 2 (k ; a ) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0 (x ),
H 1: f (x ) ¹ f 0 (x ),
где f 0 (x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где  частота
попадания вi
-тый интервал;
частота
попадания вi
-тый интервал;
p i - теоретическая вероятность попадания случайной величины вi - тый интервал при условии, что гипотезаH 0 верна.
Формулы для расчета p i в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
 . (3.8)
. (3.8)
При этом A 1 = 0, B m = +¥.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -¥, B M = +¥.
Замечания . После вычисления всех вероятностей p i проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+¥) = 1.
4.
Из таблицы " Хи-квадрат" Приложения
выбирается значение
 ,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0 закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5.
Если
 ,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
Пример3 . 1. С помощью критерия c 2 выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости a равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m , s);
H 1: f (x ) ¹ N (m , s).
Значение критерия вычисляем по формуле:
 (3.11)
(3.11)
Как отмечалось выше, при проверке гипотезы предпочтительнее использовать равновероятностную гистограмму. В этом случае

Теоретические вероятности p i рассчитываем по формуле (3.10). При этом полагаем, что

p 1 = 0,5(Ф((-4,5245+1,7)/1,98)-Ф((-¥+1,7)/1,98)) = 0,5(Ф(-1,427)-Ф(-¥)) =
0,5(-0,845+1) = 0,078.
p 2 = 0,5(Ф((-3,8865+1,7)/1,98)-Ф((-4,5245+1,7)/1,98)) =
0,5(Ф(-1,104)+0,845) = 0,5(-0,729+0,845) = 0,058.
p 3 = 0,094; p 4 = 0,135; p 5 = 0,118; p 6 = 0,097; p 7 = 0,073; p 8 = 0,059; p 9 = 0,174;
p 10 = 0,5(Ф((+¥+1,7)/1,98)-Ф((0,6932+1,7)/1,98)) = 0,114.
После этого проверяем выполнение контрольного соотношения

100 × (0,0062 + 0,0304 + 0,0004 + 0,0091 + 0,0028 + 0,0001 + 0,0100 +
0,0285 + 0,0315 + 0,0017) = 100 × 0,1207 = 12,07.
После этого из таблицы "Хи - квадрат" выбираем критическое значение
 .
.
Так
как
 то гипотезаH
0
принимается (нет основания ее отклонить).
то гипотезаH
0
принимается (нет основания ее отклонить).
). Конкретная формулировка проверяемой гипотезы от случая к случаю будет варьировать.
В этом сообщении я опишу принцип работы критерия \(\chi^2\) на (гипотетическом) примере из иммунологии . Представим, что мы выполнили эксперимент по установлению эффективности подавления развития микробного заболевания при введении в организм соответствующих антител . Всего в эксперименте было задействовано 111 мышей, которых мы разделили на две группы, включающие 57 и 54 животных соответственно. Первой группе мышей сделали инъекции патогенных бактерий с последующим введением сыворотки крови, содержащей антитела против этих бактерий. Животные из второй группы служили контролем – им сделали только бактериальные инъекции. После некоторого времени инкубации оказалось, что 38 мышей погибли, а 73 выжили. Из погибших 13 принадлежали первой группе, а 25 – ко второй (контрольной). Проверяемую в этом эксперименте нулевую гипотезу можно сформулировать так: введение сыворотки с антителами не оказывает никакого влияния на выживаемость мышей. Иными словами, мы утверждаем, что наблюдаемые различия в выживаемости мышей (77.2% в первой группе против 53.7% во второй группе) совершенно случайны и не связаны с действием антител.
Полученные в эксперименте данные можно представить в виде таблицы:
Всего |
|||
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Таблицы, подобные приведенной, называют таблицами сопряженности . В рассматриваемом примере таблица имеет размерность 2х2: есть два класса объектов («Бактерии + сыворотка» и «Только бактерии»), которые исследуются по двум признакам ("Погибло" и "Выжило"). Это простейший случай таблицы сопряженности: безусловно, и количество исследуемых классов, и количество признаков может быть бóльшим.
Для проверки сформулированной выше нулевой гипотезы нам необходимо знать, какова была бы ситуация, если бы антитела действительно не оказывали никакого действия на выживаемость мышей. Другими словами, нужно рассчитать ожидаемые частоты для соответствующих ячеек таблицы сопряженности. Как это сделать? В эксперименте всего погибло 38 мышей, что составляет 34.2% от общего числа задействованных животных. Если введение антител не влияет на выживаемость мышей, в обеих экспериментальных группах должен наблюдаться одинаковый процент смертности, а именно 34.2%. Рассчитав, сколько составляет 34.2% от 57 и 54, получим 19.5 и 18.5. Это и есть ожидаемые величины смертности в наших экспериментальных группах. Аналогичным образом рассчитываются и ожидаемые величины выживаемости: поскольку всего выжили 73 мыши, или 65.8% от общего их числа, то ожидаемые частоты выживаемости составят 37.5 и 35.5. Составим новую таблицу сопряженности, теперь уже с ожидаемыми частотами:
Погибшие |
Выжившие |
Всего |
|
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Как видим, ожидаемые частоты довольно сильно отличаются от наблюдаемых, т.е. введение антител, похоже, все-таки оказывает влияние на выживаемость мышей, зараженных патогенным микроорганизмом. Это впечатление мы можем выразить количественно при помощи критерия согласия Пирсона \(\chi^2\):
\[\chi^2 = \sum_{}\frac{(f_o - f_e)^2}{f_e},\]
где \(f_o\) и \(f_e\) - наблюдаемые и ожидаемые частоты соответственно. Суммирование производится по всем ячейкам таблицы. Так, для рассматриваемого примера имеем
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
Достаточно ли велико полученное значение \(\chi^2\), чтобы отклонить нулевую гипотезу? Для ответа на этот вопрос необходимо найти соответствующее критическое значение критерия. Число степеней свободы для \(\chi^2\) рассчитывается как \(df = (R - 1)(C - 1)\), где \(R\) и \(C\) - количество строк и столбцов в таблице сопряженности. В нашем случае \(df = (2 -1)(2 - 1) = 1\). Зная число степеней свободы, мы теперь легко можем узнать критическое значение \(\chi^2\) при помощи стандартной R-функции qchisq() :
Таким образом, при одной степени свободы только в 5% случаев величина критерия \(\chi^2\) превышает 3.841. Полученное нами значение 6.79 значительно превышает это критического значение, что дает нам право отвергнуть нулевую гипотезу об отсутствии связи между введением антител и выживаемостью зараженных мышей. Отвергая эту гипотезу, мы рискуем ошибиться с вероятностью менее 5%.
Следует отметить, что приведенная выше формула для критерия \(\chi^2\) дает несколько завышенные значения при работе с таблицами сопряженности размером 2х2. Причина заключается в том, что распределение самого критерия \(\chi^2\) является непрерывным, тогда как частоты бинарных признаков ("погибло" / "выжило") по определению дискретны. В связи с этим при расчете критерия принято вводить т.н. поправку на непрерывность , или поправку Йетса :
\[\chi^2_Y = \sum_{}\frac{(|f_o - f_e| - 0.5)^2}{f_e}.\]
"s Chi-squared test with Yates" continuity correction data : mice X-squared = 5.7923 , df = 1 , p-value = 0.0161
Как видим, R автоматически применяет поправку Йетса на непрерывность (Pearson"s Chi-squared test with Yates" continuity correction ). Рассчитанное программой значение \(\chi^2\) составило 5.79213. Мы можем отклонить нулевую гипотезу об отсутствии эффекта антител, рискуя ошибиться с вероятностью чуть более 1% (p-value = 0.0161 ).
Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
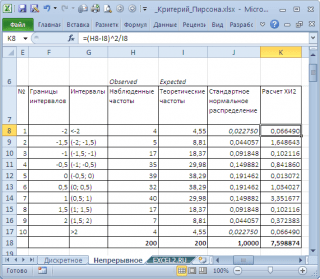
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением F* п (x) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i- й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F(x ) и F* п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k=M –S–1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k;a) , где χ 2 (k;a) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0(x ),
H 1: f (x ) f 0(x ),
где f 0(x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где частота попадания в i -тый интервал;
pi - теоретическая вероятность попадания случайной величины в i - тый интервал при условии, что гипотеза H 0верна.
Формулы для расчета pi в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
![]() . (3.8)
. (3.8)
При этом A 1 = 0, Bm = +.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -, B M = +.
Замечания . После вычисления всех вероятностей pi проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+) = 1.
4. Из таблицы " Хи-квадрат" Приложения выбирается значение , где - заданный уровень значимости (= 0,05 или = 0,01), а k - число степеней свободы, определяемое по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5. Если , то гипотеза H 0отклоняется. В противном случае нет оснований ее отклонить: с вероятностью 1 - она верна, а с вероятностью - неверна, но величина неизвестна.
Пример3 . 1. С помощью критерия 2выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m ,);
H 1: f (x ) N (m ,).
Значение критерия вычисляем по формуле.
Критерий независимости хи-квадрат используется для определения связи между двумя категориальными переменными. Примерами пар категориальных переменных являются: Семейное положение vs. Уровень занятости респондента; Порода собак vs. Профессия хозяина, Уровень з/п vs. Специализация инженера и др. При вычислении критерия независимости проверяется гипотеза о том, что между переменными связи нет. Вычисления будем производить с помощью функции MS EXCEL 2010 ХИ2.ТЕСТ() и обычными формулами.
Предположим у нас есть выборка данных, представляющая результат опроса 500 человек. Людям задавалось 2 вопроса: про их семейное положение (женаты, гражданский брак, не состоят в отношениях) и их уровень занятости (полный рабочий день, частичная занятость, временно не работает, на домохозяйстве, на пенсии, учеба). Все ответы поместили в таблицу:
Данная таблица называется таблицей сопряжённости признаков (или факторной таблицей, англ. Contingency table). Элементы на пересечении строк и столбцов таблицы обычно обозначают O ij (от англ. Observed, т.е. наблюденные, фактические частоты).
Нас интересует вопрос «Влияет ли Семейное положение на Занятость?», т.е. существует ли зависимость между двумя методами классификации выборки ?
При проверке гипотез такого вида обычно принимают, что нулевая гипотеза утверждает об отсутствии зависимости способов классификации.
Рассмотрим предельные случаи. Примером полной зависимости двух категориальных переменных является вот такой результат опроса:

В этом случае семейное положение однозначно определяет занятость (см. файл примера лист Пояснение ). И наоборот, примером полной независимости является другой результат опроса:

Обратите внимание, что процент занятости в этом случае не зависит от семейного положения (одинаков для женатых и не женатых). Это как раз совпадает с формулировкой нулевой гипотезы . Если нулевая гипотеза справедлива, то результаты опроса должны были бы так распределиться в таблице, что процент занятых был бы одинаковым независимо от семейного положения. Используя это, вычислим результаты опроса, которые соответствуют нулевой гипотезе (см. файл примера лист Пример ).
Сначала вычислим оценку вероятности, того, что элемент выборки будет иметь определенную занятость (см. столбец u i):

где с – количество столбцов (columns), равное количеству уровней переменной «Семейное положение».
Затем вычислим оценку вероятности, того, что элемент выборки будет иметь определенное семейное положение (см. строку v j).

где r – количество строк (rows), равное количеству уровней переменной «Занятость».
Теоретическая частота для каждой ячейки E ij (от англ. Expected, т.е. ожидаемая частота) в случае независимости переменных вычисляется по формуле:
E ij =n* u i * v j

Известно, что статистика Х 2 0 при больших n имеет приблизительно с (r-1)(c-1) степенями свободы (df – degrees of freedom):

Если вычисленное на основе выборки значение этой статистики «слишком большое» (больше порогового), то нулевая гипотеза отвергается. Пороговое значение вычисляется на основании , например с помощью формулы =ХИ2.ОБР.ПХ(0,05; df) .
Примечание : Уровень значимости обычно принимается равным 0,1; 0,05; 0,01.
При проверке гипотезы также удобно вычислять , которое мы сравниваем с уровнем значимости . p -значение рассчитывается с использованием с (r-1)*(c-1)=df степеней свободы.
Если вероятность, того что случайная величина имеющая с (r-1)(c-1) степенями свободы примет значение больше вычисленной статистики Х 2 0 , т.е. P{Х 2 (r-1)*(c-1) >Х 2 0 }, меньше уровня значимости , то нулевая гипотеза отклоняется.
В MS EXCEL p-значение можно вычислить с помощью формулы =ХИ2.РАСП.ПХ(Х 2 0 ;df) , конечно, вычислив непосредственно перед этим значение статистики Х 2 0 (это сделано в файле примера ). Однако, удобнее всего воспользоваться функцией ХИ2.ТЕСТ() . В качестве аргументов этой функции указываются ссылки на диапазоны содержащие фактические (Observed) и вычисленные теоретические частоты (Expected).
Если уровень значимости > p -значения , то означает это фактические и теоретические частоты, вычисленные из предположения справедливости нулевой гипотезы , серьезно отличаются. Поэтому, нулевую гипотезу нужно отклонить.
Использование функции ХИ2.ТЕСТ() позволяет ускорить процедуру проверки гипотез , т.к. не нужно вычислять значение статистики . Теперь достаточно сравнить результат функции ХИ2.ТЕСТ() с заданным уровнем значимости .
Примечание : Функция ХИ2.ТЕСТ() , английское название CHISQ.TEST, появилась в MS EXCEL 2010. Ее более ранняя версия ХИ2ТЕСТ() , доступная в MS EXCEL 2007 имеет тот же функционал. Но, как и для ХИ2.ТЕСТ() , теоретические частоты нужно вычислить самостоятельно.







