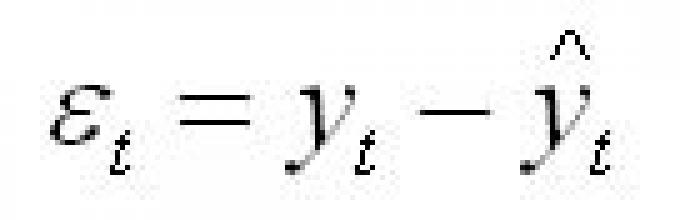
Рассматриваем уравнение регрессии вида:
где k - число независимых переменных модели регрессии.
Для каждого момента времени t = 1: n значение определяется по формуле
![]()
Изучая последовательность остатков как временной ряд в , можно построить график их зависимости от времени. В соответствии с предпосылками метода наименьших квадратов остатки должны быть случайными (а). Однако при моделировании временных рядов иногда встречается ситуация, когда остатки содержат тенденцию (б и в) или циклические колебания (г). Это говорит о том, что каждое следующее значение остатков зависит от предыдущих. В этом случае имеется автокорреляция остатков.
.jpg)
Причины автокорреляции остатков
Автокорреляция остатков может возникать по несколькими причинами:
Во-первых, иногда автокорреляция связана с исходными данными и вызвана наличием ошибок измерения в значениях Y.
Во-вторых, иногда причину следует искать в формулировке модели. В модель может быть не включен фактор, оказывающий существенное воздействие на результат, но влияние которого отражается в остатках, вследствие чего последние могут оказаться автокоррелированными . Зачастую этим фактором является фактор времени t.
Иногда, в качестве существенных факторов могут выступать лаговые значения переменных , включенных в модель. Либо в модели не учтено несколько второстепенных факторов, совместное влияние которых на результат существенно ввиду совпадения тенденций их изменения или циклических колебаний.
Методы определения автокорреляции остатков
Первый метод - это построение графика зависимостей остатков от времени и визуальное определение наличия автокорреляции остатков.
Второй метод — расчет критерия Дарбина — Уотсона

Т.е. Критерий Дарбина — Уотсона определяется как отношение суммы квадратов разностей последовательных значений остатков к сумме квадратов остатков. Практически во всех задачах по эконометрике значение критерия Дарбина - Уотсона указывается наряду с коэффициентом корреляции, значениями критериев Фишера и Стьюдента
Коэффициент автокорреляции первого порядка определяется по формуле

Соотношение между критерием Дарбина - Уотсона и коэффициентом автокорреляции остатков (r1) первого порядка определяется зависимостью

Т.е. если в остатках существует полная положительная автокорреляция r1 = 1, а d = 0, Если в остатках полная отрицательная автокорреляция, то r1 = - 1, d = 4. Если автокорреляция остатков отсутствует, то r1 = 0, d = 2. Следовательно,
![]()
Алгоритм выявления автокорреляции остатков по критерию Дарбина - Уотсона
Выдвигается гипотеза об отсутствии автокорреляции остатков . Альтернативные гипотеэы о наличии положительной или отрицательной автокорреляции в остатках. Затем по таблицам определяются критические значения критерия Дарбина - Уотсона dL и du для заданного числа наблюдений и числа независимых переменных модели при уровня значимости а (обычно 0,95). По этим значениям промежуток разбивают на пять отрезков.

Если расчетное значение критерия Дарбина — Уотсона попадает в зону неопределенности , то подтверждается существование автокорреляции остатков и гипотезу отклоняют
Таблица П.А.1. Значения статистик d L и d U критерия Дарбина –Уотсона при уровне значимости a= 0,05
(n-число наблюдений, p- число объясняющих переменных).
| n | p =1 d L d U | P =2 d L d U | p =3 d L d U | p =4 d L d U |
| 1.08 1.36 | 0.95 1.54 | 0.82 1.75 | 0.69 1.97 | |
| 1.10 1.37 | 0.98 1.54 | 0.86 1.73 | 0.74 1.93 | |
| 1.13 1.38 | 1.02 1.54 | 0.90 1.71 | 1.78 1.90 | |
| 1.16 1.39 | 1.05 1.53 | 0.93 1.69 | 1.82 1.87 | |
| 1.18 1.40 | 1.08 1.53 | 0.97 1.68 | 0.85 1.85 | |
| 1.20 1.41 | 1.10 1.54 | 1.00 1.68 | 0.90 1.83 | |
| 1.22 1.42 | 1.13 1.54 | 1.03 1.67 | 0.93 1.81 | |
| 1.24 1.43 | 1.15 1.54 | 1.05 1.66 | 0.96 1.80 | |
| 1.26 1.44 | 1.17 1.54 | 1.08 1.66 | 0.99 1.79 | |
| 1.27 1.45 | 1.19 1.55 | 1.10 1.66 | 1.01 1.78 | |
| 1.29 1.45 | 1.21 1.55 | 1.12 1.66 | 1.04 1.77 | |
| 1.30 1.46 | 1.22 1.55 | 1.14 1.65 | 1.06 1.76 | |
| 1.32 1.47 | 1.24 1.56 | 1.16 1.65 | 1.08 1.76 | |
| 1.33 1.48 | 1.26 1.56 | 1.18 1.65 | 1.10 1.75 | |
| 1.34 1.48 | 1.27 1.56 | 1.20 1.65 | 1.12 1.74 | |
| 1.35 1.49 | 1.28 1.57 | 1.21 1.65 | 1.14 1.74 | |
| 1.36 1.50 | 1.30 1.57 | 1.23 1.65 | 1.16 1.74 | |
| 1.37 1.50 | 1.31 1.57 | 1.34 1.65 | 1.18 1.73 | |
| 1.38 1.51 | 1.32 1.58 | 1.26 1.65 | 1.19 1.73 | |
| 1.39 1.51 | 1.33 1.58 | 1.27 1.65 | 1.21 1.73 | |
| 1.40 1.52 | 1.34 1.58 | 1.28 1.65 | 1.22 1.73 | |
| 1.41 1.52 | 1.35 1.59 | 1.29 1.65 | 1.24 1.73 |
Таблица П.А.2 Значения статистик d L и d U критерия Дарбина –Уотсона
при уровне значимости a= 0,01
(n-число наблюдений, p- число объясняющих переменных)
| n | p =1 d L d U | p =2 d L d U | p =3 d L d U | p =4 d L d U |
| 0,81 1,07 | 0,70 1,25 | 0,59 1,46 | 0,49 1,70 | |
| 0,84 1,09 | 0,74 1,25 | 0,63 1,44 | 0,534 1,66 | |
| 0,87 1,10 | 0,77 1,25 | 0,67 1,43 | 0,57 1,63 | |
| 0,90 1,12 | 0,80 1,26 | 0,71 1,42 | 0,61 1,60 | |
| 0,93 1,13 | 0,83 1,26 | 0,74 1,41 | 0,65 1,58 | |
| 0,95 1,15 | 0,86 1,27 | 0,77 1,41 | 0,68 1,57 | |
| 0,97 1,16 | 0,89 1,27 | 0,80 1,41 | 0,72 1,55 | |
| 1,00 1,17 | 0,91 1,28 | 0,83 1,40 | 0,75 1,54 | |
| 1,02 1,19 | 0,94 1,29 | 0,86 1,40 | 0,77 1,53 | |
| 1,04 1,20 | 0,96 1,30 | 0,88 1,41 | 0,80 1,53 | |
| 1,05 1,21 | 0,98 1,30 | 0,90 1,41 | 0,83 1,52 | |
| 1,07 1,22 | 1,00 1,31 | 0,93 1,41 | 0,85 1,52 | |
| 1,09 1,23 | 1,02 1,32 | 0,95 1,41 | 0,88 1,51 | |
| 1,10 1,24 | 1,04 1,32 | 0,95 1,41 | 0,90 1,51 | |
| 1,12 1,25 | 1,05 1,33 | 0,99 1,42 | 0,92 1,51 | |
| 1,13 1,26 | 1,07 1,34 | 1,01 1,42 | 0,94 1,51 | |
| 1,15 1,27 | 1,08 1,34 | 1,02 1,42 | 0,96 1,51 | |
| 1,16 1,28 | 1,10 1,35 | 1,04 1,43 | 0,98 1,51 | |
| 1,17 1,29 | 1,11 1,36 | 1,05 1,43 | 1,00 1,51 | |
| 1,18 1,30 | 1,13 1,36 | 1,07 1,43 | 1,01 1,51 | |
| 1,19 1,31 | 1,14 1,37 | 1,08 1,44 | 1,03 1,51 | |
| 1,21 1,32 | 1,15 1,38 | 1,10 1,44 | 1,04 1,51 |
Приложение Б. Исследование уравнений регрессии
С помощью пакетов прикладных программ Excel
Общие сведения
Исследование линейного уравнение регрессии с помощью ППП Excel возможно с использованием встроенной статистической функции ЛИНЕЙН, либо с помощью инструмента анализа данных РЕГРЕССИЯ. Рассмотрим каждый из этих вариантов.
1. Встроенная статистическая функция ЛИНЕЙН определяет параметры a ,b линейного уравнения регрессии y=a+b∙x . Порядок вычислений следующий:
1.1. Введите исходные данные или откройте существующий файл, содержащий анализируемые данные.
1.2. Выделите область пустых ячеек 5×2 (5 строк и 2 столбца) для вывода результатов регрессионной статистики (или область 1×2 –для получения только оценок коэффициентов регрессии).
1.3. Активизируйте Мастер функций, в окне Категория выберите Статистические , в окне Функция – Линейн .
1.4. Заполните аргументы функции:
Известные значения y- диапазон, содержащий данные зависимой переменной Y ;
Известные значения x- диапазон, содержащий данные независимой переменной X ;
Константа – логическое значение, которое указывает на наличие или отсутствие свободного члена в уравнении регрессии. Если Константа =1, то свободный член a в уравнении регрессии рассчитывается обычным образом; если Константа =0, то свободный член равен нулю, a =0.
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика= 1, то выводится дополнительная информация; если Статистика =0, то выводятся только оценки параметров уравнения.
1.5. После заполнения аргументов в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нужно нажать на клавишу «F 2», а затем на комбинацию клавиш «CTRL »+«SHIFT »+«ENTER ». Дополнительная регрессионная статистика будет выводиться в следующем порядке:
2. С помощью инструмента анализа данных Регрессия, помимо результатов регрессионной статистики, можно выполнить дисперсионный анализ, построить доверительные интервалы для параметров уравнения регрессии, можно получить остатки, графики остатков и графики подбора линии регрессии. Последовательность подключения и работы с инструментом анализа данных следующая:
2.1. Для подключения пакета анализа данных в главном меню последовательно выберите Сервис/Надстройки . Установите флажок у надстройки Пакет анализа .
2.2 В главном меню выберите Сервис/Анализ данных/Регрессия .
2.3. Заполните диалоговое окно ввода данных и параметров вывода.
Выходной интервал Y - здесь требуется задать состоящий из одного столбца диапазон анализируемых зависимых данных.
Входной интервал Х - здесь требуется задать диапазон значений независимой переменной (или нескольких независимых переменных).
Метки - здесь требуется установка флажка, если первая строка или первый столбец входного интервала содержит заголовки. Если заголовков нет, то флажок надо снять. Для удобства последующего анализа полученных результатов рекомендуется всегда иметь заголовочную строку (или столбец) в поле исходных данных и поэтому всегда включать метки во входной интервал (не забывать щелкать по флажку "метки"). Если мы забудем включить этот флажок при наличии меток, то вместо расчета получим прерывание и сообщение "Входной интервал содержит нечисловые данные ".
Уровень надежности - по умолчанию, применяется уровень 95%. Установить флажок, если нужно включить в выходной диапазон дополнительный уровень, а в поле (рядом) ввести уровень надежности, который будет использован дополнительно к применяемому.
Константа – ноль – этот флажок необходимо пометить только в том случае, если нужно получить уравнение без свободного члена, чтобы линия регрессии прошла через начало координат.В целях исключения ошибок спецификациимодели линейной регрессиирекомендуется не активизировать этот флажок и всегда рассчитывать значение константы; в дальнейшем, если это значение окажется незначимым, им можно пренебречь.
Выходной диапазон - здесь требуется определить левую верхнюю ячейку выходного диапазона. Необходимо минимум семь столбцов для итогового диапазона, который будет включать в себя: результаты дисперсионного анализа, коэффициенты регрессии, стандартную погрешность вычисления Y , среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов. В случае сложной задачи, где требуется получить большое число результатов исследования уравнений, лучше воспользоваться возможностью размещения каждого из них на новом рабочем листе.
Новый лист - здесь требуется установить переключатель для открытия нового листа в книге под результаты анализа, начиная с ячейки А 1. Можно ввести имя нового листа в поле напротив переключателя.
Остатки- установкой этого флажка заказывается включение остатков в выходной диапазон. Для получения максимума информации в ходе исследования рекомендуется активизировать этот и все описанные ниже флажки диалогового окна.
График остатков - чтобы построить диаграмму остатков для каждой независимой переменной, нужно установить этот флажок.
График подбора - это важнейший график, а точнее серия графиков, показывающих насколько хорошо теоретическая линия регрессии (т.е. предсказания) подобрана к наблюдаемым данным.
Истинные значения отклонений Et,t = 1,2, ...,T неизвестны. Поэтому выводы об их независимости осуществляются на основе оценок et,t = 1,2, ...,T, полученных из эмпирического уравнениярегрессии. Рассмотрим возможные методы определения автокорреляции.
Обычно проверяется некоррелированность отклонений et,t = 1, 2, ... , T, являющаяся необходимым, но недостаточным условием независимости. Причем проверяется некоррелированность соседних величин et. Соседними обычно считаются соседние во времени (при рассмотрении временных рядов) или по возрастанию объясняющей переменной X (в случае перекрестной выборки) значения et. Для них несложно рассчитать коэффициент корреляции, называемый в этом случае коэффициентом автокорреляции первого порядка:
При этом учитывается, что математическое ожидание остатков M (et) = 0.
На практике для анализа коррелированности отклонений вместо коэффициента корреляции используют тесно связанную с ним
статистику Ларбина-Уотсона (DW) рассчитываемую по формуле1

Очевидно, что при больших T

Нетрудно заметить, что если et=et-1, то rete- 1=1 и DW=0 (положительная автокорреляция). Если et=-et-1, то re^t 1=-1 и DW=4 (отрицательная автокорреляция). Во всех других случаях 0 lt; DW lt; 4 . При случайном поведении отклонений rete- 1=0 и DW=2. Таким
образом, необходимым условием независимости случайных отклонений является близость к двойке значения статистики Дарбина- Уотсона. Тогда, если DW ~ 2, мы считаем отклонения от регрессии случайными (хотя они в действительности могут и не быть таковыми). Это означает, что построенная линейная регрессия, вероятно, отражает реальную зависимость. Скорее всего, не осталось неучтенных существенных факторов, влияющих на зависимую переменную. Какая-либо другая нелинейная формула не превосходит по статистическим характеристикам предложенную линейную модель. В этом случае, даже когда R2 невелико, вполне вероятно, что необъясненная дисперсия вызвана влиянием на зависимую переменную большого числа различных факторов, индивидуально слабо влияющих на исследуемую переменную, и может быть описана как случайная нормальная ошибка.
Возникает вопрос, какие значения DW можно считать статистически близкими к 2? Для ответа на этот вопрос разработаны специальные таблицы критических точек статистики Дарбина-Уотсона, позволяющие при данном числе наблюдений T (или в прежних обозначениях n), количестве объясняющих переменных m и заданном уровне значимости а определять границы приемлемости (критические точки) наблюдаемой статистики DW. Для заданных а,Т, m в таблице указываются два числа: di - нижняя граница и du - верхняя граница.
Общая схема критерия Дарбина-Уотсона следующая:
- По построенному эмпирическому уравнению регрессии
определяются значения отклонений et = У, - У, для каждого наблюдения t, t = 1,..., Т.
- По формуле (4.4) рассчитывается статистика DW.
- По таблице критических точек Дарбина-Уотсона определяются два числа di и du и осуществляют выводы по правилу:
(dі lt; DW lt; du) - вывод о наличии автокорреляции не определен, (ku lt; DW lt; 4 - du) - автокорреляция отсутствует, (4 - du lt; DW lt; 4 - di) - вывод о наличии автокорреляции не определен,
(4 - di lt; DW lt; 4) - существует отрицательная автокорреляция.
Не обращаясь к таблице критических точек Дарбина-Уотсона, можно пользоваться «грубым» правилом и считать, что автокорреляция остатков отсутствует, если 1,5lt; DW lt; 2,5. Для более надежного вывода целесообразно обращаться к табличным значениям. При наличии автокорреляции остатков полученное уравнение регрессии обычно считается неудовлетворительным.
Отметим, что при использовании критерия Дарбина-Уотсона необходимо учитывать следующие ограничения:
- Критерий DW применяется лишь для тех моделей, которые содержат свободный член.
- Предполагается, что случайные отклонения Et определяются по итерационной схеме: Et = PEt-1 + vt, называемой авторегрессионной схемой первого порядка HR(1). Здесь vt - случайный член, для которого условия Гаусса-Маркова выполняются.
- Статистические данные должны иметь одинаковую периодичность (не должно быть пропусков в наблюдениях).
- Критерий Дарбина-Уотсона не применим для регрессионных моделей, содержащих в составе объясняющих переменных зависимую переменную с временным лагом в один период, т. е. для так называемых авторегрессионных моделей вида:
В этом случае имеется систематическая связь между одной из объясняющих переменных и одним из компонентов случайного члена. Не выполняется одна из основных предпосылок МНК - объясняющие переменные не должны быть случайными (не иметь случайной составляющей). Значение любой объясняющей переменной должно быть экзогенным (заданным вне модели), полностью определенным. В противном случае оценки будут смещенными даже при больших объемах выборок.
Для авторегрессионных моделей разработаны специальные тесты обнаружения автокорреляции, в частности h-статистика Дарби- на, которая определяется по формуле:
где р - оценка коэффициента р авторегрессии первого порядка?t = PCt-1 + vt (vt - случайный член), D(g) - выборочная дисперсия коэффициента Y при лаговой переменной yt-1, п - число наблюдений.
При большом объеме выборки h распределяется как ф(0,1), т. е. как нормальная переменная со средним значением 0 и дисперсией, равной 1 по нулевой гипотезе отсутствия автокорреляции. Следовательно, гипотеза отсутствия автокорреляции может быть отклонена при уровне значимости 5%, если абсолютное значение h больше, чем 1,96, и при уровне значимости 1%, если оно больше, чем 2,58, при применении двухстороннего критерия и большой выборке. В противном случае она не отклоняется.
Отметим, что обычно значение р рассчитывается по формуле:
р = 1- 0,5DW, а D(g) равна квадрату стандартной ошибки Sg
оценки g коэффициента Y. Поэтому h легко вычисляется на основе данных оцененной регрессии.
Основная проблема при использовании этого теста заключается в невозможности вычисления h при nD (g) gt; 1.
Пример 4.1. Пусть имеются следующие условные данные (X - объясняющая переменная, Y - зависимая переменная, табл. 4.1).
Таблица 4.1
Исходные данные (условные, ден. ед.)
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Y | 3 | 8 | 6 | 12 | 11 | 17 | 15 | 20 | 16 | 24 | 22 | 28 | 26 | 34 | 31 |
Линейное уравнение регрессии имеет вид: Y = 2,09 + 2,014X .
Рассчитаем статистику Дарбина-Уотсона (табл. 4.2): Критерий Дарбина-Уотсона применяют для обнаружения автокорреляции , подчиняющейся авторегрессионному процессу 1-го порядка. Предполагается, что величина остатков е t в каждом t-м наблюдении не зависит от его значений во всех других наблюдениях. Если коэффициент автокорреляции ρ положительный, то автокорреляция положительна, если ρ отрицательный, то автокорреляция отрицательна. Если ρ = 0, то автокорреляция отсутствует (т.е. четвертая предпосылка нормальной линейной модели выполняется).
Критерий Дарбина-Уотсона сводится к проверке гипотезы:
- Н 0 (основная гипотеза): ρ = 0
- Н 1 (альтернативная гипотеза): ρ > 0 или ρ
Для проверки основной гипотезы используется статистика критерия Дарбина-Уотсона – DW:Где e i = y - y(x)
Проводится с помощью трех калькуляторов:
- Уравнение тренда (линейная и нелинейная регрессия)
Рассмотрим третий вариант. Линейное уравнение тренда имеет вид y = at + b
1. Находим параметры уравнения методом наименьших квадратов через онлайн сервис Уравнение тренда .
Система уравнений
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.78, a 1 = 26763.32
Уравнение тренда
y = -12.78 t + 26763.32
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда
Средние значения
Дисперсия
Среднеквадратическое отклонениеИндекс детерминации
, т.е. в 97.01% случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая.t y t 2 y 2 t ∙ y y(t) (y-y cp) 2 (y-y(t)) 2 (t-t p) 2 (y-y(t)) : y 1990 1319 3960100 1739761 2624810 1340.26 18117.16 451.99 148.84 28041.86 1996 1288 3984016 1658944 2570848 1263.61 10732.96 594.99 38.44 31417.53 2001 1213 4004001 1471369 2427213 1199.73 817.96 176.08 1.44 16095.92 2002 1193 4008004 1423249 2388386 1186.96 73.96 36.54 0.04 7211.59 2003 1174 4012009 1378276 2351522 1174.18 108.16 0.03 0.64 210.94 2004 1159 4016016 1343281 2322636 1161.4 645.16 5.78 3.24 2786.55 2005 1145 4020025 1311025 2295725 1148.63 1552.36 13.17 7.84 4155.05 2006 1130 4024036 1276900 2266780 1135.85 2959.36 34.26 14.44 6614.41 2007 1117 4028049 1247689 2241819 1123.08 4542.76 36.94 23.04 6789.19 2008 1106 4032064 1223236 2220848 1110.3 6146.56 18.51 33.64 4758.73 20022 11844 40088320 14073730 23710587 11844 45696.4 1368.3 271.6 108081.77 Тест Дарбина-Уотсона на наличие автокорреляции остатков для временного ряда .
y y(x) e i = y-y(x) e 2 (e i - e i-1) 2 1319 1340.26 -21.26 451.99 0 1288 1263.61 24.39 594.99 2084.14 1213 1199.73 13.27 176.08 123.72 1193 1186.96 6.04 36.54 52.19 1174 1174.18 -0.18 0.03 38.75 1159 1161.4 -2.4 5.78 4.95 1145 1148.63 -3.63 13.17 1.5 1130 1135.85 -5.85 34.26 4.95 1117 1123.08 -6.08 36.94 0.05 1106 1110.3 -4.3 18.51 3.15 1368.3 2313.41
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости a, числа наблюдений n и количества объясняющих переменных m.
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Для более надежного вывода целесообразно обращаться к табличным значениям.
d 1 < DW и d 2 < DW < 4 - d 2 .Пример . По данным за 24 месяца построено уравнение регрессии зависимости прибыли сельскохозяйственной организации от производительности труда (x1): y = 300 + 5x .
Получены следующие промежуточные результаты:
∑ε 2 = 18500
∑(ε t - ε t-1) 2 = 41500
Рассчитайте критерий Дарбина-Уотсона (при n=24 и k=1 (число факторов) нижнее значение d = 1,27, верхнее d = 1,45. Сделайте выводы.Решение.
DW = 41500/18500 = 2,24
d 2 = 4- 1,45 =2,55
Поскольку DW > 2,55, то следовательно, имеются основания считать, что автокорреляция отсутствует. Это является одним из подтверждений высокого качества полученного уравнения регрессии y = 300 + 5x .
Критерий Дарбина - Уотсона
Одним из самых простых, а потому широко применяемых на практике критериев проверки на наличие (отсутствие) автокорреляции является критерий Дарбина - Уотсона
и }







