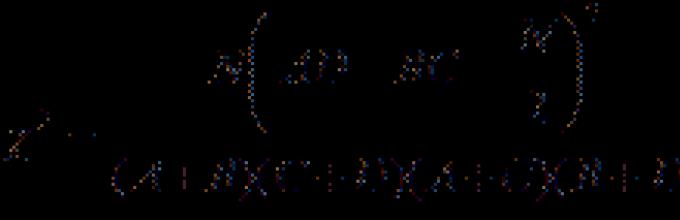
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна
где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Распределение вероятных значений случайной величины χ2 непрерывно и ассиметрично. Оно зависит от числа степеней свободы (n) и приближается к нормальному распределению по мере увеличения числа наблюдений. Поэтому применение критерия χ2 к оценке дискретных распределений сопряжено с некоторыми погрешностями, которые сказываются на его величине, особенно на малочисленных выборках. Для получения более точных оценок выборка, распределяемая в вариационный ряд, должна иметь не менее 50 вариантов. Правильное применение критерия χ2 требует также, чтобы частоты вариантов в крайних классах не были бы меньше 5; если их меньше 5, то они объединяются с частотами соседних классов, чтобы в сумме составляли величину большую или равную 5. Соответственно объединению частот уменьшается и число классов (N). Число степеней свободы устанавливается по вторичному числу классов с учетом числа ограничений свободы вариации.
Так как точность определения критерия χ2 в значительной степени зависит от точности расчета теоретических частот (Т), для получения разности между эмпирическими и вычисленными частотами следует использовать неокругленные теоретические частоты.
В качестве примера возьмем исследование, опубликованное на сайте, который посвящен применению статистических методов в гуманитарных науках.
Критерий "Хи-квадрат" позволяет сравнивать распределения частот вне зависимости от того, распределены они нормально или нет.
Под частотой понимается количество появлений какого-либо события. Обычно, с частотой появления события имеют дело, когда переменные измерены в шкале наименований и другой их характеристики, кроме частоты подобрать невозможно или проблематично. Другими словами, когда переменная имеет качественные характеристики. Так же многие исследователи склонны переводить баллы теста в уровни (высокий, средний, низкий) и строить таблицы распределений баллов, чтобы узнать количество человек по этим уровням. Чтобы доказать, что в одном из уровней (в одной из категорий) количество человек действительно больше (меньше) так же используется коэффициент Хи-квадрат.
Разберем самый простой пример.
Среди младших подростков был проведён тест для выявления самооценки. Баллы теста были переведены в три уровня: высокий, средний, низкий. Частоты распределились следующим образом:
Высокий (В) 27 чел.
Средний (С) 12 чел.
Низкий (Н) 11 чел.
Очевидно, что детей с высокой самооценкой большинство, однако это нужно доказать статистически. Для этого используем критерий Хи-квадрат.
Наша задача проверить, отличаются ли полученные эмпирические данные от теоретически равновероятных. Для этого необходимо найти теоретические частоты. В нашем случае, теоретические частоты – это равновероятные частоты, которые находятся путём сложения всех частот и деления на количество категорий.
В нашем случае:
(В + С + Н)/3 = (27+12+11)/3 = 16,6
Формула для расчета критерия хи-квадрат:
χ2 = ∑(Э - Т)І / Т
Строим таблицу:
Находим сумму последнего столбца:
Теперь нужно найти критическое значение критерия по таблице критических значений (Таблица 1 в приложении). Для этого нам понадобится число степеней свободы (n).
n = (R - 1) * (C - 1)
где R – количество строк в таблице, C – количество столбцов.
В нашем случае только один столбец (имеются в виду исходные эмпирические частоты) и три строки (категории), поэтому формула изменяется – исключаем столбцы.
n = (R - 1) = 3-1 = 2
Для вероятности ошибки p≤0,05 и n = 2 критическое значение χ2 = 5,99.
Полученное эмпирическое значение больше критического – различия частот достоверны (χ2= 9,64; p≤0,05).
Как видим, расчет критерия очень прост и не занимает много времени. Практическая ценность критерия хи-квадрат огромна. Этот метод оказывается наиболее ценным при анализе ответов на вопросы анкет.
Разберем более сложный пример.
К примеру, психолог хочет узнать, действительно ли то, что учителя более предвзято относятся к мальчикам, чем к девочкам. Т.е. более склонны хвалить девочек. Для этого психологом были проанализированы характеристики учеников, написанные учителями, на предмет частоты встречаемости трех слов: "активный", "старательный", "дисциплинированный", синонимы слов так же подсчитывались. Данные о частоте встречаемости слов были занесены в таблицу:
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)І / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Заключение.
К. Пирсон внёс значительный вклад в развитие математической статистики (большое количество фундаментальных понятий). Основная философская позиция Пирсона формулируется следующим образом: понятия науки - искусственные конструкции, средства описания и упорядочивания чувственного опыта; правила связи их в научные предложения вычленяются грамматикой науки, которая и является, философией науки. Связать же разнородные понятия и явления позволяет универсальная дисциплина - прикладная статистика, хотя и она по Пирсону субъективна.
Многие построения К. Пирсона напрямую связаны или разрабатывались с использованием антропологических материалов. Им разработаны многочисленные способы нумерической классификации и статистические критерии, применяемые во всех областях науки.
Литература.
1. Боголюбов А. Н. Математики. Механики. Биографический справочник. - Киев: Наукова думка, 1983.
2. Колмогоров А. Н., Юшкевич А. П. (ред.). Математика XIX века. - М.: Наука. - Т. I.
3. 3. Боровков А.А. Математическая статистика. М.: Наука, 1994.
4. 8. Феллер В. Введение в теорию вероятностей и ее приложения. - М.: Мир, Т.2, 1984.
5. 9. Харман Г., Современный факторный анализ. - М.: Статистика, 1972.
Критерий хи-квадрат.
Критерий хи-квадрат в отличие от критерия z применяется для сравнения любого количества групп.
Исходные данные: таблица сопряжённости.
Пример таблицы сопряженности минимальной размерности 2*2, приведен ниже. A,B,C,D – так называемые, реальные частоты.
| Признак 1 | Признак 2 | Всего | |
| Группа 1 | A | B | A+B |
| Группа 2 | C | D | C+D |
| Всего | A+C | B+D | A+B+C+D |
Расчёт критерия основан на сравнении реальных частот и ожидаемых частот, которые вычисляются в предположении отсутствия взаимного влияния сравниваемых признаков друг на друга. Таким образом, если реальные и ожидаемые частоты достаточно близки друг к другу, то влияния нет и значит признаки будут распределены примерно одинаково по группам.
Исходные данные для применения этого метода должны быть занесены в таблицу сопряженности, по столбцам и по строчкам которой указываются варианты значений изучаемых признаков. Числа в этой таблице будут называться реальными или экспериментальными частотами. Далее необходимо рассчитать ожидаемые частоты исходя из предположения, что сравниваемые группы абсолютно равны по распределению признаков. В этом случае пропорции по итоговой строчке или столбцу «всего» должны сохраняться в любой строчке и столбце. Исходя из этого, определяются ожидаемые частоты (см. пример).
Затем рассчитывают значение критерия как сумму по всем ячейкам таблицы сопряженности отношения квадрата разности между реальной частотой и ожидаемой частотой к ожидаемой частоте:
где - реальная частота в ячейке; - ожидаемая частота в ячейке.
 , где N = A+ B + C + D
.
, где N = A+ B + C + D
.
При расчёте по основной формуле для таблицы 2*2 (только для такой таблицы ), также необходимо применить поправку Йейтса на непрерывность:
 .
.
Критическое значение критерия определяется по таблице (см. приложение) с учетом числа степеней свободы и уровня значимости. Уровень значимости принимают стандартным: 0,05; 0,01 или 0,001. Число степеней свободы определяется как произведение числа строк и столбцов таблицы сопряженности уменьшенных каждое на единицу:
![]() ,
,
где r – число строк (число градаций одного признака), с – число столбцов (число градаций другого признака). Это критическое значение можно определить в электронной таблице Microsoft Excel используя функцию =хи2обр(a, f ), где вместо a надо ввести уровень значимости, а вместо f – число степеней свободы.
Если значение критерия хи-квадрат больше критического, то гипотезу о независимости признаков отвергают и их можно считать зависимыми на выбранном уровне значимости.
У этого метода есть ограничение по применимости: ожидаемые частоты должны быть 5 или более (для таблицы 2*2). Для произвольной таблицы это ограничение менее строгое: все ожидаемые частоты должны быть 1 или больше, а доля ячеек с ожидаемыми частотами меньше 5 не должна превышать 20%.
Из таблицы сопряженности большой размерности можно «вычленить» таблицы меньшей размерности и для них рассчитать значение критерия c 2 . Это фактически будут множественные сравнения, аналогичные описанным для критерия Стьюдента. В этом случае также надо применять поправку на множественные сравнения в зависимости от их количества.
Для проверки гипотезы с помощью критерия c 2 в электронных таблицах Microsoft Excel можно применить следующую функцию:
ХИ2ТЕСТ(фактический_интервал; ожидаемый_интервал).
Здесь фактический_интервал – исходная таблица сопряженности с реальными частотами (указываются только ячейки с самими частотами без заголовков и «всего»); ожидаемый_интервал – массив ожидаемых частот. Следовательно, ожидаемые частоты должны быть вычислены самостоятельно.
Пример:
В некотором городе произошла вспышка инфекционного заболевания. Есть предположение, что источником заражения явилась питьевая вода. Проверить это предположение решили с помощью выборочного опроса городского населения, по которому необходимо установить влияет ли количество выпиваемой воды на количество заболевших.
Исходные данные приведены в следующей таблице:
Рассчитаем ожидаемые частоты. Пропорция по всего должна сохраниться и внутри таблицы. Поэтому вычислим, например, какую долю составляют всего по строчкам в общей численности, получим для каждой строчки коэффициент. Такая же доля должна оказаться в каждой ячейке соответствующей строчки, поэтому для вычисления ожидаемой частоты в ячейке умножаем коэффициент на всего по соответствующему столбцу.

Число степеней свободы равно (3-1)*(2-1)=2. Критическое значение критерия ![]() .
.
Экспериментальное значение больше критического (61,5>13,816), т.е. гипотеза об отсутствия влияния количества выпиваемой воды на заболеваемость отвергается с вероятностью ошибки менее 0,001. Таким образом, можно утверждать, что именно вода стала источником заболевания.
У обоих описанных критериев существуют ограничения, которые обычно не выполняются, если число наблюдений невелико или отдельные градации признаков редко встречаются. В этом случае используют точный критерий Фишера . Он основан на переборе всех возможных вариантов заполнения таблицы сопряженности при данной численности групп. Поэтому ручной расчет его довольно сложен. Для его расчёта можно воспользоваться статистическими пакетами прикладных программ.
Критерий z является аналогом критерия Стьюдента, но применяется для сравнения качественных признаков. Экспериментальное значение критерия рассчитывается как отношение разности долей к средней ошибке разности долей.
Критические значение критерия z равны соответствующим точкам нормированного нормального распределения: ![]() ,
, ![]() ,
, ![]() .
.
Критерий хи-квадрат применяется для сравнения любого количества групп по значениям качественных признаков. Исходные данные должны быть представлены в виде таблицы сопряжённости. Экспериментальное значение критерия рассчитывают как сумму по всем ячейкам таблицы сопряженности отношения квадрата разности между реальной частотой и ожидаемой частотой к ожидаемой частоте. Ожидаемые частоты вычисляются в предположении равенства сравниваемых признаков во всех группах. Критические значения определяются по таблицам распределения хи-квадрат.
ЛИТЕРАТУРА.
Гланц С. – Глава 5.
Реброва О.Ю. – Глава 10,11.
Лакин Г.Ф. – с. 120-123
Вопросы для самопроверки студентов.
1. В каких случаях можно применять критерий z?
2. На чём основано вычисление экспериментального значения критерия z?
3. Как найти критическое значение критерия z?
4. В каких случаях можно применять критерий c 2 ?
5. На чём основано вычисление экспериментального значения критерия c 2 ?
6. Как найти критическое значение критерия c 2 ?
7. Что ещё можно применить для сравнения качественных признаков, если нельзя применить по ограничениям критерии z и c 2 ?
Задачи.
В практике биологических исследований часто бывает необходимо проверить ту или иную гипотезу, т. е. выяснить, насколько полученный экспериментатором фактический материал подтверждает теоретическое предположение, насколько анализируемые данные совпадают с теоретически ожидаемыми. Возникает задача статистической оценки разницы между фактическими данными и теоретическим ожиданием, установления того, в каких случаях и с какой степенью вероятности можно считать эту разницу достоверной и, наоборот, когда ее следует считать несущественной, незначимой, находящейся в пределах случайности. В последнем случае сохраняется гипотеза, на основе которой рассчитаны теоретически ожидаемые данные или показатели. Таким вариационно-статистическим приемом проверки гипотезы служит метод хи-квадрат (χ 2). Этот показатель часто называют «критерием соответствия» или «критерием согласия» Пирсона. С его помощью можно с той или иной вероятностью судить о степени соответствия эмпирически полученных данных теоретически ожидаемым.
С формальных позиций сравниваются два вариационных ряда, две совокупности: одна – эмпирическое распределение, другая представляет собой выборку с теми же параметрами (n , M , S и др.), что и эмпирическая, но ее частотное распределение построено в точном соответствии с выбранным теоретическим законом (нормальным, Пуассона, биномиальным и др.), которому предположительно подчиняется поведение изучаемой случайной величины.
В общем виде формула критерия соответствия может быть записана следующим образом:
где a – фактическая частота наблюдений,
A – теоретически ожидаемая частота для данного класса.
Нулевая гипотеза предполагает, что достоверных различий между сравниваемыми распределениями нет. Для оценки существенности этих различий следует обратиться к специальной таблице критических значений хи-квадрат (табл. 9П ) и, сравнив вычисленную величину χ 2 с табличной, решить, достоверно или не достоверно отклоняется эмпирическое распределение от теоретического. Тем самым гипотеза об отсутствии этих различий будет либо опровергнута, либо оставлена в силе. Если вычисленная величина χ 2 равна или превышает табличную χ ² (α , df ) , решают, что эмпирическое распределение от теоретического отличается достоверно. Тем самым гипотеза об отсутствии этих различий будет опровергнута. Если же χ ² < χ ² (α , df ) , нулевая гипотеза остается в силе. Обычно принято считать допустимым уровень значимости α = 0.05, т. к. в этом случае остается только 5% шансов, что нулевая гипотеза правильна и, следовательно, есть достаточно оснований (95%), чтобы от нее отказаться.
Определенную проблему составляет правильное определение числа степеней свободы (df ), для которых из таблицы берут значения критерия. Для определения числа степеней свободы из общего числа классов k нужно вычесть число ограничений (т. е. число параметров, использованных для расчета теоретических частот).
В зависимости от типа распределения изучаемого признака формула для расчета числа степеней свободы будет меняться. Для альтернативного распределения (k = 2) в расчетах участвует только один параметр (объем выборки), следовательно, число степеней свободы составляет df = k −1=2−1=1. Для полиномиального распределения формула аналогична: df = k −1. Для проверки соответствия вариационного ряда распределению Пуассона используются уже два параметра – объем выборки и среднее значение (численно совпадающее с дисперсией); число степеней свободы df = k −2. При проверке соответствия эмпирического распределения вариант нормальному или биномиальному закону число степеней свободы берется как число фактических классов минус три условия построения рядов – объем выборки, средняя и дисперсия, df = k −3. Сразу стоит отметить, что критерий χ² работает только для выборок объемом не менее 25 вариант , а частоты отдельных классов должны быть не ниже 4 .
Вначале проиллюстрируем применение критерия хи-квадрат на примере анализа альтернативной изменчивости . В одном из опытов по изучению наследственности у томатов было обнаружено 3629 красных и 1176 желтых плодов. Теоретическое соотношение частот при расщеплении признаков во втором гибридном поколении должно быть 3:1 (75% к 25%). Выполняется ли оно? Иными словами, взята ли данная выборка из той генеральной совокупности, в которой соотношение частот 3:1 или 0.75:0.25?
Сформируем таблицу (табл. 4), заполнив значениями эмпирических частот и результатами расчета теоретических частот по формуле:
А = n∙p,
где p – теоретические частости (доли вариант данного типа),
n – объем выборки.
Например, A 2 = n∙p 2 = 4805∙0.25 = 1201.25 ≈ 1201.
Количественное изучение биологических явлений обязательно требует создания гипотез, с помощью которых можно объяснить эти явления. Чтобы проверить ту или иную гипотезу ставят серию специальных опытов и полученные фактические данные сопоставляют с теоретически ожидаемыми согласно данной гипотезе. Если есть совпадениеэто может быть достаточным основанием для принятия гипотезы. Если же опытные данные плохо согласуются с теоретически ожидаемыми, возникает большое сомнение в правильности предложенной гипотезы.
Степень соответствия фактических данных ожидаемым (гипотетическим) измеряется критерием соответствия хи-квадрат:
фактически наблюдаемое значение признака вi- той;теоретически ожидаемое число или признак (показатель) для данной группы,k число групп данных.
Критерий был предложен К.Пирсоном в 1900 г. и иногда его называют критерием Пирсона.
Задача. Среди 164 детей, наследовавших от одного из родителей фактор, а от другогофактор, оказалось 46 детей с фактором, 50с фактором, 68с тем и другим,. Рассчитать ожидаемые частоты при отношении 1:2:1 между группами и определить степень соответствия эмпирических данных с помощью критерия Пирсона.
Решение: Отношение наблюдаемых частот 46:68:50, теоретически ожидаемых 41:82:41.
Зададимся уровнем значимости равным 0,05. Табличное значение критерия Пирсона для этого уровня значимости при числе степеней свободы, равном оказалось равным 5,99. Следовательно гипотезу о соответствии экспериментальных данных теоретическим можно принять, так как, .
Отметим, что при вычислении критерия хи-квадрат мы уже не ставим условия о непременной нормальности распределения. Критерий хи-квадрат может использоваться для любых распределений, которые мы вольны сами выбирать в своих предположениях. В этом есть некоторая универсальность этого критерия.
Еще одно приложение критерия Пирсона это сравнение эмпирического распределения с нормальным распределением Гаусса. При этом он может быть отнесен к группе критериев проверки нормальности распределения. Единственным ограничением является тот факт, что общее число значений (вариант) при пользовании этим критерием должно быть достаточно велико (не менее 40), и число значений в отдельных классах (интервалах) должно быть не менее 5. В противном случае следует объединять соседние интервалы. Число степенй свободы при проверке нормальности распределения должно вычисляться как:.
Критерий Фишера.
Этот параметрический критерий служит для проверки нулевой гипотезы о равенстве дисперсий нормально распределенных генеральных совокупностей.
![]() Или.
Или.
При малых объемах выборок применение критерия Стьюдента может быть корректным только при условии равенства дисперсий. Поэтому прежде чем проводить проверку равенства выборочных средних значений, необходимо убедиться в правомочности использования критерия Стьюдента.
где N 1 , N 2 объемы выборок, 1 , 2 числа степеней свободы для этих выборок.
При пользовании таблицами следует обратить внимание, что число степеней свободы для выборки с большей по величине дисперсией выбирается как номер столбца таблицы, а для меньшей по величине дисперсии как номер строки таблицы.
Для уровня значимости по таблицам математической статистики находим табличное значение. Если, то гипотеза о равенстве дисперсий отклоняется для выбранного уровня значимости.
Пример. Изучали влияние кобальта на массу тела кроликов. Опыт проводился на двух группах животных: опытной и контрольной. Опытные получали добавку к рациону в виде водного раствора хлористого кобальта. За время опыта прибавки в весе составили в граммах:
|
Контроль |
|

Хи-квадрат Пирсона - это наиболее простой критерий проверки значимости связи между двумя категоризованными переменными. Критерий Пирсона основывается на том, что в двувходовой таблице ожидаемые частоты при гипотезе "между переменными нет зависимости" можно вычислить непосредственно. Представьте, что 20 мужчин и 20 женщин опрошены относительно выбора газированной воды (марка A или марка B ). Если между предпочтением и полом нет связи, то естественно ожидать равного выбора марки A и марки B для каждого пола.
Значение статистики хи-квадрат и ее уровень значимости зависит от общего числа наблюдений и количества ячеек в таблице. В соответствии с принципами, обсуждаемыми в разделе , относительно малые отклонения наблюдаемых частот от ожидаемых будет доказывать значимость, если число наблюдений велико.
Имеется только одно существенное ограничение использования критерия хи-квадрат (кроме очевидного предположения о случайном выборе наблюдений), которое состоит в том, что ожидаемые частоты не должны быть очень малы. Это связано с тем, что критерий хи-квадрат по своей природе проверяет вероятности в каждой ячейке; и если ожидаемые частоты в ячейках, становятся, маленькими, например, меньше 5, то эти вероятности нельзя оценить с достаточной точностью с помощью имеющихся частот. Дальнейшие обсуждения см. в работах Everitt (1977), Hays (1988) или Kendall and Stuart (1979).
Критерий хи-квадрат (метод максимального правдоподобия). Максимум правдоподобия хи-квадрат предназначен для проверки той же самой гипотезы относительно связей в таблицах сопряженности, что и критерий хи-квадрат Пирсона. Однако его вычисление основано на методе максимального правдоподобия. На практике статистика МП хи-квадрат очень близка по величине к обычной статистике Пирсона хи-квадрат . Подробнее об этой статистике можно прочитать в работах Bishop, Fienberg, and Holland (1975) или Fienberg (1977). В разделе Логлинейный анализ эта статистика обсуждается подробнее.
Поправка Йетса. Аппроксимация статистики хи-квадрат для таблиц 2x2 с малыми числом наблюдений в ячейках может быть улучшена уменьшением абсолютного значения разностей между ожидаемыми и наблюдаемыми частотами на величину 0.5 перед возведением в квадрат (так называемая поправка Йетса ). Поправка Йетса, делающая оценку более умеренной, обычно применяется в тех случаях, когда таблицы содержат только малые частоты, например, когда некоторые ожидаемые частоты становятся меньше 10 (дальнейшее обсуждение см. в Conover, 1974; Everitt, 1977; Hays, 1988; Kendall and Stuart, 1979 и Mantel, 1974).
Точный критерий Фишера. Этот критерий применим только для таблиц 2x2. Критерий основан на следующем рассуждении. Даны маргинальные частоты в таблице, предположим, что обе табулированные переменные независимы. Зададимся вопросом: какова вероятность получения наблюдаемых в таблице частот, исходя из заданных маргинальных? Оказывается, эта вероятность вычисляется точно подсчетом всех таблиц, которые можно построить, исходя из маргинальных. Таким образом, критерий Фишера вычисляет точную вероятность появления наблюдаемых частот при нулевой гипотезе (отсутствие связи между табулированными переменными). В таблице результатов приводятся как односторонние, так и двусторонние уровни.
Хи-квадрат Макнемара. Этот критерий применяется, когда частоты в таблице 2x2 представляют зависимые выборки. Например, наблюдения одних и тех же индивидуумов до и после эксперимента. В частности, вы можете подсчитывать число студентов, имеющих минимальные успехи по математике в начале и в конце семестра или предпочтение одних и тех же респондентов до и после рекламы. Вычисляются два значения хи-квадрат : A/D и B/C . A/D хи-квадрат проверяет гипотезу о том, что частоты в ячейках A и D (верхняя левая, нижняя правая) одинаковы. B/C хи-квадрат проверяет гипотезу о равенстве частот в ячейках B и C (верхняя правая, нижняя левая).
Коэффициент Фи. Фи-квадрат представляет собой меру связи между двумя переменными в таблице 2x2. Его значения изменяются от 0 (нет зависимости между переменными; хи-квадрат = 0.0 ) до 1 (абсолютная зависимость между двумя факторами в таблице). Подробности см. в Castellan and Siegel (1988, стр. 232).
Тетрахорическая корреляция. Эта статистика вычисляется (и применяется) только для таблиц сопряженности 2x2. Если таблица 2x2 может рассматриваться как результат (искусственного) разбиения значений двух непрерывных переменных на два класса, то коэффициент тетрахорической корреляции позволяет оценить зависимость между двумя этими переменными.
Коэффициент сопряженности. Коэффициент сопряженности представляет собой основанную на статистике хи-квадрат меру связи признаков в таблице сопряженности (предложенную Пирсоном). Преимущество этого коэффициента перед обычной статистикой хи-квадрат в том, что он легче интерпретируется, т.к. диапазон его изменения находится в интервале от 0 до 1 (где 0 соответствует случаю независимости признаков в таблице, а увеличение коэффициента показывает увеличение степени связи). Недостаток коэффициента сопряженности в том, что его максимальное значение "зависит" от размера таблицы. Этот коэффициент может достигать значения 1 только, если число классов не ограничено (см. Siegel, 1956, стр. 201).
Интерпретация мер связи. Существенный недостаток мер связи (рассмотренных выше) связан с трудностью их интерпретации в обычных терминах вероятности или "доли объясненной вариации", как в случае коэффициента корреляции r Пирсона (см. Корреляции). Поэтому не существует одной общепринятой меры или коэффициента связи.
Статистики, основанные на рангах. Во многих задачах, возникающих на практике, мы имеем измерения лишь в порядковой шкале (см. Элементарные понятия статистики ). Особенно это относится к измерениям в области психологии, социологии и других дисциплинах, связанных с изучением человека. Предположим, вы опросили некоторое множество респондентов с целью выяснения их отношение к некоторым видам спорта. Вы представляете измерения в шкале со следующими позициями: (1) всегда , (2) обычно , (3) иногда и (4) никогда . Очевидно, что ответ иногда интересуюсь показывает меньший интерес респондента, чем ответ обычно интересуюсь и т.д. Таким образом, можно упорядочить (ранжировать) степень интереса респондентов. Это типичный пример порядковой шкалы. Для переменных, измеренных в порядковой шкале, имеются свои типы корреляции, позволяющие оценить зависимости.
R Спирмена. Статистику R Спирмена можно интерпретировать так же, как и корреляцию Пирсона (r Пирсона) в терминах объясненной доли дисперсии (имея, однако, в виду, что статистика Спирмена вычислена по рангам). Предполагается, что переменные измерены как минимум в порядковой шкале. Всестороннее обсуждение ранговой корреляции Спирмена, ее мощности и эффективности можно найти, например, в книгах Gibbons (1985), Hays (1981), McNemar (1969), Siegel (1956), Siegel and Castellan (1988), Kendall (1948), Olds (1949) и Hotelling and Pabst (1936).
Тау Кендалла. Статистика тау Кендалла эквивалентна R Спирмена при выполнении некоторых основных предположений. Также эквивалентны их мощности. Однако обычно значения R Спирмена и тау Кендалла различны, потому что они отличаются как своей внутренней логикой, так и способом вычисления. В работе Siegel and Castellan (1988) авторы выразили соотношение между этими двумя статистиками следующим неравенством:
1 < = 3 * Тау Кендалла - 2 * R Спирмена < = 1
Более важно то, что статистики Кендалла тау и Спирмена R имеют различную интерпретацию: в то время как статистика R Спирмена может рассматриваться как прямой аналог статистики r Пирсона, вычисленный по рангам, статистика Кендалла тау скорее основана на вероятности . Более точно, проверяется, что имеется различие между вероятностью того, что наблюдаемые данные расположены в том же самом порядке для двух величин и вероятностью того, что они расположены в другом порядке. Kendall (1948, 1975), Everitt (1977), и Siegel and Castellan (1988) очень подробно обсуждают тау Кендалла. Обычно вычисляется два варианта статистики тау Кендалла: tau b и tau c . Эти меры различаются только способом обработки совпадающих рангов. В большинстве случаев их значения довольно похожи. Если возникают различия, то, по-видимому, самый безопасный способ - рассматривать наименьшее из двух значений.
Коэффициент d Соммера: d(X|Y), d(Y|X). Статистика d Соммера представляет собой несимметричную меру связи между двумя переменными. Эта статистика близка к tau b (см. Siegel and Castellan, 1988, стр. 303-310).
Гамма-статистика. Если в данных имеется много совпадающих значений, статистика гамма предпочтительнее R Спирмена или тау Кендалла. С точки зрения основных предположений, статистика гамма эквивалентна статистике R Спирмена или тау Кендалла. Ее интерпретация и вычисления более похожи на статистику тау Кендалла, чем на статистику R Спирмена. Говоря кратко, гамма представляет собой также вероятность ; точнее, разность между вероятностью того, что ранговый порядок двух переменных совпадает, минус вероятность того, что он не совпадает, деленную на единицу минус вероятность совпадений. Таким образом, статистика гамма в основном эквивалентна тау Кендалла, за исключением того, что совпадения явно учитываются в нормировке. Подробное обсуждение статистики гамма можно найти у Goodman and Kruskal (1954, 1959, 1963, 1972), Siegel (1956) и Siegel and Castellan (1988).
Коэффициенты неопределенности. Эти коэффициенты измеряют информационную связь между факторами (строками и столбцами таблицы). Понятие информационной зависимости берет начало в теоретико-информационном подходе к анализу таблиц частот, можно обратиться к соответствующим руководствам для разъяснения этого вопроса (см. Kullback, 1959; Ku and Kullback, 1968; Ku, Varner, and Kullback, 1971; см. также Bishop, Fienberg, and Holland, 1975, стр. 344-348). Статистика S (Y,X ) является симметричной и измеряет количество информации в переменной Y относительно переменной X или в переменной X относительно переменной Y . Статистики S(X|Y) и S(Y|X) выражают направленную зависимость.
Многомерные отклики и дихотомии. Переменные типа многомерных откликов и многомерных дихотомий возникают в ситуациях, когда исследователя интересуют не только "простые" частоты событий, но также некоторые (часто неструктурированные) качественные свойства этих событий. Природу многомерных переменных (факторов) лучше всего понять на примерах.
- · Многомерные отклики
- · Многомерные дихотомии
- · Кросстабуляция многомерных откликов и дихотомий
- · Парная кросстабуляция переменных с многомерными откликами
- · Заключительный комментарий
Многомерные отклики. Представьте, что в процессе большого маркетингового исследования, вы попросили покупателей назвать 3 лучших, с их точки зрения, безалкогольных напитка. Обычный вопрос может выглядеть следующим образом.







