Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна
где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Распределение вероятных значений случайной величины χ2 непрерывно и ассиметрично. Оно зависит от числа степеней свободы (n) и приближается к нормальному распределению по мере увеличения числа наблюдений. Поэтому применение критерия χ2 к оценке дискретных распределений сопряжено с некоторыми погрешностями, которые сказываются на его величине, особенно на малочисленных выборках. Для получения более точных оценок выборка, распределяемая в вариационный ряд, должна иметь не менее 50 вариантов. Правильное применение критерия χ2 требует также, чтобы частоты вариантов в крайних классах не были бы меньше 5; если их меньше 5, то они объединяются с частотами соседних классов, чтобы в сумме составляли величину большую или равную 5. Соответственно объединению частот уменьшается и число классов (N). Число степеней свободы устанавливается по вторичному числу классов с учетом числа ограничений свободы вариации.
Так как точность определения критерия χ2 в значительной степени зависит от точности расчета теоретических частот (Т), для получения разности между эмпирическими и вычисленными частотами следует использовать неокругленные теоретические частоты.
В качестве примера возьмем исследование, опубликованное на сайте, который посвящен применению статистических методов в гуманитарных науках.
Критерий "Хи-квадрат" позволяет сравнивать распределения частот вне зависимости от того, распределены они нормально или нет.
Под частотой понимается количество появлений какого-либо события. Обычно, с частотой появления события имеют дело, когда переменные измерены в шкале наименований и другой их характеристики, кроме частоты подобрать невозможно или проблематично. Другими словами, когда переменная имеет качественные характеристики. Так же многие исследователи склонны переводить баллы теста в уровни (высокий, средний, низкий) и строить таблицы распределений баллов, чтобы узнать количество человек по этим уровням. Чтобы доказать, что в одном из уровней (в одной из категорий) количество человек действительно больше (меньше) так же используется коэффициент Хи-квадрат.
Разберем самый простой пример.
Среди младших подростков был проведён тест для выявления самооценки. Баллы теста были переведены в три уровня: высокий, средний, низкий. Частоты распределились следующим образом:
Высокий (В) 27 чел.
Средний (С) 12 чел.
Низкий (Н) 11 чел.
Очевидно, что детей с высокой самооценкой большинство, однако это нужно доказать статистически. Для этого используем критерий Хи-квадрат.
Наша задача проверить, отличаются ли полученные эмпирические данные от теоретически равновероятных. Для этого необходимо найти теоретические частоты. В нашем случае, теоретические частоты – это равновероятные частоты, которые находятся путём сложения всех частот и деления на количество категорий.
В нашем случае:
(В + С + Н)/3 = (27+12+11)/3 = 16,6
Формула для расчета критерия хи-квадрат:
χ2 = ∑(Э - Т)І / Т
Строим таблицу:
Находим сумму последнего столбца:
Теперь нужно найти критическое значение критерия по таблице критических значений (Таблица 1 в приложении). Для этого нам понадобится число степеней свободы (n).
n = (R - 1) * (C - 1)
где R – количество строк в таблице, C – количество столбцов.
В нашем случае только один столбец (имеются в виду исходные эмпирические частоты) и три строки (категории), поэтому формула изменяется – исключаем столбцы.
n = (R - 1) = 3-1 = 2
Для вероятности ошибки p≤0,05 и n = 2 критическое значение χ2 = 5,99.
Полученное эмпирическое значение больше критического – различия частот достоверны (χ2= 9,64; p≤0,05).
Как видим, расчет критерия очень прост и не занимает много времени. Практическая ценность критерия хи-квадрат огромна. Этот метод оказывается наиболее ценным при анализе ответов на вопросы анкет.
Разберем более сложный пример.
К примеру, психолог хочет узнать, действительно ли то, что учителя более предвзято относятся к мальчикам, чем к девочкам. Т.е. более склонны хвалить девочек. Для этого психологом были проанализированы характеристики учеников, написанные учителями, на предмет частоты встречаемости трех слов: "активный", "старательный", "дисциплинированный", синонимы слов так же подсчитывались. Данные о частоте встречаемости слов были занесены в таблицу:
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)І / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Заключение.
К. Пирсон внёс значительный вклад в развитие математической статистики (большое количество фундаментальных понятий). Основная философская позиция Пирсона формулируется следующим образом: понятия науки - искусственные конструкции, средства описания и упорядочивания чувственного опыта; правила связи их в научные предложения вычленяются грамматикой науки, которая и является, философией науки. Связать же разнородные понятия и явления позволяет универсальная дисциплина - прикладная статистика, хотя и она по Пирсону субъективна.
Многие построения К. Пирсона напрямую связаны или разрабатывались с использованием антропологических материалов. Им разработаны многочисленные способы нумерической классификации и статистические критерии, применяемые во всех областях науки.
Литература.
1. Боголюбов А. Н. Математики. Механики. Биографический справочник. - Киев: Наукова думка, 1983.
2. Колмогоров А. Н., Юшкевич А. П. (ред.). Математика XIX века. - М.: Наука. - Т. I.
3. 3. Боровков А.А. Математическая статистика. М.: Наука, 1994.
4. 8. Феллер В. Введение в теорию вероятностей и ее приложения. - М.: Мир, Т.2, 1984.
5. 9. Харман Г., Современный факторный анализ. - М.: Статистика, 1972.
В этой статье речь будет идти о исследовании зависимости между признаками, или как больше нравится - случайными величинами, переменными. В частности, мы разберем как ввести меру зависимости между признаками, используя критерий Хи-квадрат и сравним её с коэффициентом корреляции.
Для чего это может понадобиться? К примеру, для того, чтобы понять какие признаки сильнее зависимы от целевой переменной при построении кредитного скоринга - определении вероятности дефолта клиента. Или, как в моем случае, понять какие показатели нобходимо использовать для программирования торгового робота.
Отдельно отмечу, что для анализа данных я использую язык c#. Возможно это все уже реализовано на R или Python, но использование c# для меня позволяет детально разобраться в теме, более того это мой любимый язык программирования.
Начнем с совсем простого примера, создадим в экселе четыре колонки, используя генератор случайных чисел:
X
=СЛУЧМЕЖДУ(-100;100)
Y
=X
*10+20
Z
=X
*X
T
=СЛУЧМЕЖДУ(-100;100)
Как видно, переменная Y линейно зависима от X ; переменная Z квадратично зависима от X ; переменные X и Т независимы. Такой выбор я сделал специально, потому что нашу меру зависимости мы будем сравнивать с коэффициентом корреляции . Как известно, между двумя случайными величинами он равен по модулю 1 если между ними самый «жесткий» вид зависимости - линейный. Между двумя независимыми случайными величинами корреляция нулевая, но из равенства коэффициента корреляции нулю не следует независимость . Далее мы это увидим на примере переменных X и Z .
Сохраняем файл как data.csv и начинаем первые прикиди. Для начала рассчитаем коэффициент корреляции между величинами. Код в статью я вставлять не стал, он есть на моем github . Получаем корреляцию по всевозможным парам:

Видно, что у линейно зависимых X и Y коэффициент корреляции равен 1. А вот у X и Z он равен 0.01, хотя зависимость мы задали явную Z =X *X . Ясно, что нам нужна мера, которая «чувствует» зависимость лучше. Но прежде, чем переходить к критерию Хи-квадрат, давайте рассмотрим что такое матрица сопряженности.
Чтобы построить матрицу сопряженности мы разобьём диапазон значений переменных на интервалы (или категорируем). Есть много способов такого разбиения, при этом какого-то универсального не существует. Некоторые из них разбивают на интервалы так, чтобы в них попадало одинаковое количество переменных, другие разбивают на равные по длине интервалы. Мне лично по духу комбинировать эти подходы. Я решил воспользоваться таким способом: из переменной я вычитаю оценку мат. ожидания, потом полученное делю на оценку стандартного отклонения. Иными словами я центрирую и нормирую случайную величину. Полученное значение умножается на коэффициент (в этом примере он равен 1), после чего все округляется до целого. На выходе получается переменная типа int, являющаяся идентификатором класса.
Итак, возьмем наши признаки X и Z , категорируем описанным выше способом, после чего посчитаем количество и вероятности появления каждого класса и вероятности появления пар признаков:

Это матрица по количеству. Здесь в строках - количества появлений классов переменной X , в столбцах - количества появлений классов переменной Z , в клетках - количества появлений пар классов одновременно. К примеру, класс 0 встретился 865 раз для переменной X , 823 раза для переменной Z и ни разу не было пары (0,0). Перейдем к вероятностям, поделив все значения на 3000 (общее число наблюдений):

Получили матрицу сопряженности, полученную после категорирования признаков. Теперь пора задуматься над критерием. По определению, случайные величины независимы, если независимы сигма-алгебры , порожденные этими случайными величинами. Независимость сигма-алгебр подразумевает попарную независимость событий из них. Два события называются независимыми, если вероятность их совместного появления равна произведению вероятностей этих событий: Pij = Pi*Pj . Именно этой формулой мы будем пользоваться для построения критерия.
Нулевая гипотеза : категорированные признаки X и Z независимы. Эквивалентная ей: распределение матрицы сопряженности задается исключительно вероятностями появления классов переменных (вероятности строк и столбцов). Или так: ячейки матрицы находятся произведением соответствующих вероятностей строк и столбцов. Эту формулировку нулевой гипотезы мы будем использовать для построения решающего правила: существенное расхождение между Pij и Pi*Pj будет являться основанием для отклонения нулевой гипотезы.
Пусть - вероятность появления класса 0 у переменной X
. Всего у нас n
классов у X
и m
классов у Z
. Получается, чтобы задать распределение матрицы нам нужно знать эти n
и m
вероятностей. Но на самом деле если мы знаем n-1
вероятность для X
, то последняя находится вычитанием из 1 суммы других. Таким образом для нахождения распределения матрицы сопряженности нам надо знать l=(n-1)+(m-1)
значений. Или мы имеем l
-мерное параметрическое пространство, вектор из которого задает нам наше искомое распределение. Статистика Хи-квадрат будет иметь следующий вид:
и, согласно теореме Фишера, иметь распределение Хи-квадрат с n*m-l-1=(n-1)(m-1)
степенями свободы.
Зададимся уровнем значимости 0.95 (или вероятность ошибки первого рода равна 0.05). Найдем квантиль распределения Хи квадрат для данного уровня значимости и степеней свободы из примера (n-1)(m-1)=4*3=12 : 21.02606982. Сама статистика Хи-квадрат для переменных X и Z равна 4088.006631. Видно, что гипотеза о независимости не принимается. Удобно рассматривать отношение статистики Хи-квадрат к пороговому значению - в данном случае оно равно Chi2Coeff=194.4256186 . Если это отношение меньше 1, то гипотеза о независимости принимается, если больше, то нет. Найдем это отношение для всех пар признаков:

Здесь Factor1
и Factor2
- имена признаков
src_cnt1
и src_cnt2
- количество уникальных значений исходных признаков
mod_cnt1
и mod_cnt2
- количество уникальных значений признаков после категорирования
chi2
- статистика Хи-квадрат
chi2max
- пороговое значение статистики Хи-квадрат для уровня значимости 0.95
chi2Coeff
- отношение статистики Хи-квадрат к пороговому значению
corr
- коэффициент корреляции
Видно, что независимы (chi2coeff<1) получились следующие пары признаков - (X,T ), (Y,T ) и (Z,T ), что логично, так как переменная T генерируется случайно. Переменные X и Z зависимы, но менее, чем линейно зависимые X и Y , что тоже логично.
Код утилиты, рассчитывающей данные показатели я выложил на github, там же файл data.csv. Утилита принимает на вход csv-файл и высчитывает зависимости между всеми парами колонок: PtProject.Dependency.exe data.csv
). Конкретная формулировка проверяемой гипотезы от случая к случаю будет варьировать.
В этом сообщении я опишу принцип работы критерия \(\chi^2\) на (гипотетическом) примере из иммунологии . Представим, что мы выполнили эксперимент по установлению эффективности подавления развития микробного заболевания при введении в организм соответствующих антител . Всего в эксперименте было задействовано 111 мышей, которых мы разделили на две группы, включающие 57 и 54 животных соответственно. Первой группе мышей сделали инъекции патогенных бактерий с последующим введением сыворотки крови, содержащей антитела против этих бактерий. Животные из второй группы служили контролем – им сделали только бактериальные инъекции. После некоторого времени инкубации оказалось, что 38 мышей погибли, а 73 выжили. Из погибших 13 принадлежали первой группе, а 25 – ко второй (контрольной). Проверяемую в этом эксперименте нулевую гипотезу можно сформулировать так: введение сыворотки с антителами не оказывает никакого влияния на выживаемость мышей. Иными словами, мы утверждаем, что наблюдаемые различия в выживаемости мышей (77.2% в первой группе против 53.7% во второй группе) совершенно случайны и не связаны с действием антител.
Полученные в эксперименте данные можно представить в виде таблицы:
Всего |
|||
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Таблицы, подобные приведенной, называют таблицами сопряженности . В рассматриваемом примере таблица имеет размерность 2х2: есть два класса объектов («Бактерии + сыворотка» и «Только бактерии»), которые исследуются по двум признакам ("Погибло" и "Выжило"). Это простейший случай таблицы сопряженности: безусловно, и количество исследуемых классов, и количество признаков может быть бóльшим.
Для проверки сформулированной выше нулевой гипотезы нам необходимо знать, какова была бы ситуация, если бы антитела действительно не оказывали никакого действия на выживаемость мышей. Другими словами, нужно рассчитать ожидаемые частоты для соответствующих ячеек таблицы сопряженности. Как это сделать? В эксперименте всего погибло 38 мышей, что составляет 34.2% от общего числа задействованных животных. Если введение антител не влияет на выживаемость мышей, в обеих экспериментальных группах должен наблюдаться одинаковый процент смертности, а именно 34.2%. Рассчитав, сколько составляет 34.2% от 57 и 54, получим 19.5 и 18.5. Это и есть ожидаемые величины смертности в наших экспериментальных группах. Аналогичным образом рассчитываются и ожидаемые величины выживаемости: поскольку всего выжили 73 мыши, или 65.8% от общего их числа, то ожидаемые частоты выживаемости составят 37.5 и 35.5. Составим новую таблицу сопряженности, теперь уже с ожидаемыми частотами:
Погибшие |
Выжившие |
Всего |
|
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Как видим, ожидаемые частоты довольно сильно отличаются от наблюдаемых, т.е. введение антител, похоже, все-таки оказывает влияние на выживаемость мышей, зараженных патогенным микроорганизмом. Это впечатление мы можем выразить количественно при помощи критерия согласия Пирсона \(\chi^2\):
\[\chi^2 = \sum_{}\frac{(f_o - f_e)^2}{f_e},\]
где \(f_o\) и \(f_e\) - наблюдаемые и ожидаемые частоты соответственно. Суммирование производится по всем ячейкам таблицы. Так, для рассматриваемого примера имеем
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
Достаточно ли велико полученное значение \(\chi^2\), чтобы отклонить нулевую гипотезу? Для ответа на этот вопрос необходимо найти соответствующее критическое значение критерия. Число степеней свободы для \(\chi^2\) рассчитывается как \(df = (R - 1)(C - 1)\), где \(R\) и \(C\) - количество строк и столбцов в таблице сопряженности. В нашем случае \(df = (2 -1)(2 - 1) = 1\). Зная число степеней свободы, мы теперь легко можем узнать критическое значение \(\chi^2\) при помощи стандартной R-функции qchisq() :
Таким образом, при одной степени свободы только в 5% случаев величина критерия \(\chi^2\) превышает 3.841. Полученное нами значение 6.79 значительно превышает это критического значение, что дает нам право отвергнуть нулевую гипотезу об отсутствии связи между введением антител и выживаемостью зараженных мышей. Отвергая эту гипотезу, мы рискуем ошибиться с вероятностью менее 5%.
Следует отметить, что приведенная выше формула для критерия \(\chi^2\) дает несколько завышенные значения при работе с таблицами сопряженности размером 2х2. Причина заключается в том, что распределение самого критерия \(\chi^2\) является непрерывным, тогда как частоты бинарных признаков ("погибло" / "выжило") по определению дискретны. В связи с этим при расчете критерия принято вводить т.н. поправку на непрерывность , или поправку Йетса :
\[\chi^2_Y = \sum_{}\frac{(|f_o - f_e| - 0.5)^2}{f_e}.\]
"s Chi-squared test with Yates" continuity correction data : mice X-squared = 5.7923 , df = 1 , p-value = 0.0161
Как видим, R автоматически применяет поправку Йетса на непрерывность (Pearson"s Chi-squared test with Yates" continuity correction ). Рассчитанное программой значение \(\chi^2\) составило 5.79213. Мы можем отклонить нулевую гипотезу об отсутствии эффекта антител, рискуя ошибиться с вероятностью чуть более 1% (p-value = 0.0161 ).
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
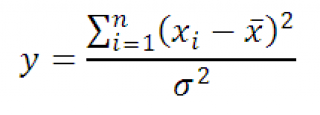
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
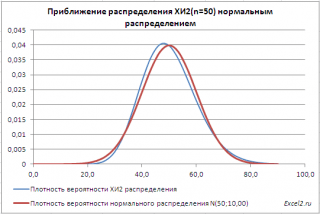
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).