
При проектировании выборочного наблюдения возникает вопрос о необходимой численности выборки. Эта численность может быть определена на базе допустимой ошибки при выборочном наблюдении, исходя из вероятности, на основе которой можно гарантировать величину устанавливаемой ошибки, и, наконец, на базе способа отбора.
Формулы необходимого объема выборки для различных способов формирования выборочной совокупности могут быть выведены из соответствующих соотношений, используемых при расчете предельных ошибок выборки. Приведем наиболее часто применяемые на практике выражения необходимого объема выборки:
· собственно-случайная и механическая выборки:
(повторный отбор)
![]() (бесповторный отбор)
(бесповторный отбор)
· типическая выборка:
(повторный отбор)
![]() (бесповторный отбор)
(бесповторный отбор)
· серийная выборка:
(повторный отбор)
(бесповторный отбор)
При этом в зависимости от целей исследования дисперсии и ошибки выборки могут быть рассчитаны для средней величины или доли признака.
Рассмотрим примеры определения необходимого объема выборки при различных способах формирования выборочной совокупности.
Пример 5. В 100 туристических агентствах города предполагается провести обследование среднемесячного количества реализованных путевок методом механического отбора. Какова должна быть численность выборки, чтобы с вероятностью 0,683 ошибка не превышала 3 путевок, если по данным пробного обследования дисперсия составляет 225.
Решение . Рассчитаем необходимый объем выборки:
Агентств.
Пример 6. С целью определения доли сотрудников коммерческих банков области в возрасте старше 40 лет предполагается организовать типическую выборку пропорциональную численности сотрудников мужского и женского пола с механическим отбором внутри групп. Общее число сотрудников банков составляет 12 тыс. чел., в том числе 7 тыс. мужчин и 5 тыс. женщин.
На основании предыдущих обследований известно, что средняя из внутригрупповых дисперсий составляет 1600. Определите необходимый объем выборки при вероятности 0,997 и ошибке 5%.
Решение. Рассчитаем общую численность типической выборки:
![]() чел.
чел.
Вычислим теперь объем отдельных типических групп:
![]() чел.
чел.
![]() чел.
чел.
Таким образом, необходимый объем выборочной совокупности сотрудников банков составляет 550 чел., в т.ч. 319 мужчин и 231 женщина.
Пример 7. В акционерном обществе 200 бригад рабочих. Планируется проведение выборочного обследования с целью определения удельного веса рабочих, имеющих профессиональные заболевания. Известно, что межсерийная дисперсия доли равна 225. С вероятностью 0,954 рассчитайте необходимое количество бригад для обследования рабочих, если ошибка выборки не должна превышать 5%.
Решение. Необходимое количество бригад рассчитаем на основе формулы объема серийной бесповторной выборки:
![]() бригад.
бригад.
3.Определение необходимого объема выборки
Очень важное значение имеет определение оптимальной численности выборки, которая с определенной вероятностью обеспечит заданную точность результатов наблюдения. При увеличении численности выборки ошибка выборки уменьшается. Но так как отобранные единицы для обследования часто разрушаются, то нормы отбора единиц в выборку должны быть оптимальными. Оптимальную численность выборки можно получить из формул ошибок выборки.
Таблица 8.4
Формулы определения оптимальной численности выборки
|
Способ отбора |
Для средней |
|
|
Собственно-случайный повторный |
|
|
|
Случайный и механический бесповторный |
|
|
|
Типологический бесповторный |
|
|
|
Серийный бесповторный с равновеликими сериями |
|
|








Формулы показывают, что с увеличением предполагаемой ошибки выборки значительно уменьшается необходимый объём выборки.
Для расчета объёма выборки нужно знать дисперсию. Она может быть заимствована из проводимых ранее обследований данной или аналогичной совокупности или можно провести специальное выборочное обследование небольшого объёма.
Пример 2 : На предприятии в порядке случайной бесповторной выборки были опрошены 100 рабочих из 1000 и получены следующие данные об их доходе за октябрь (табл. 8.5).
Таблица 8.5
Распределение рабочих по размеру среднего месячного дохода
Определить:
1) среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997;
2) долю рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, гарантируя результат с вероятностью 0,954;
3) необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб.
Решение:
1) Определим среднемесячный размер дохода у работников данного предприятия, гарантируя результат с вероятностью 0,997.
|
n = 100 чел. N = 1000 чел. |
Решение
: для определения интервала среднемесячного дохода работников данного предприятия в генеральной совокупности необходимо знать величину предельной ошибки выборки Поскольку P= 0,997, то (по табл. 8.2)t = 3. Был произведен случайный бесповторный отбор, по табл. 8.3 выбираем формулу для расчета средней ошибки выборки для средней:
Размер среднемесячного дохода рабочих по данным выборочного обследования определим по формуле средней арифметической взвешенной: Дополнительные расчеты проведем в следующей таблице:
Зная t
и Тыс. руб. Тогда интервал среднего месячного дохода рабочих данного предприятия будет таким:
|
 и размер среднемесячного дохода рабочих по данным выборочного обследования
и размер среднемесячного дохода рабочих по данным выборочного обследования .
. t
и средней ошибки выборки
t
и средней ошибки выборки .
. , где
, где – дисперсия по выборке.
– дисперсия по выборке. .
.



 тыс. руб.
тыс. руб.
 тыс. руб.
тыс. руб. определим величину предельной ошибки выборки:
определим величину предельной ошибки выборки: ;
; .
.Ответ: среднемесячный размер дохода у работников данного предприятия с вероятностью 0,997 находится в пределах от 18,08 тыс. руб. до 18,92 тыс. руб.
2) Определим долю рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, гарантируя результат с вероятностью 0,954.
|
n = 100 чел. N = 1000 чел.
|
Решение
: для определения интервала доли рабочих, имеющих месячный доход 19 тыс. руб. и выше необходимо, знать величину предельной ошибки выборки доли Предельная ошибка выборки определяется по формуле Поскольку P= 0,954, то (по табл. 8.2)t = 2. Был произведен случайный бесповторный отбор, по табл. 8.3 выбираем формулу для расчета средней ошибки выборки для доли:
Выборочная доля определяется отношением числа единиц, обладающих изучаемым признаком m
к общему числу единиц выборочной совокупностиn
, или Тогда средняя ошибка доли равна Зная t и определим величину предельной ошибки выборки для доли: Тогда интервал доли рабочих с месячным доходом 19 тыс. руб. и выше в генеральной совокупности будет таким:
|

 и долю рабочих с таким среднемесячным доходом по данным выборкиW
.
и долю рабочих с таким среднемесячным доходом по данным выборкиW
. . Она зависит от величины коэффициента доверияt
и средней ошибки выборки .
. Она зависит от величины коэффициента доверияt
и средней ошибки выборки . , гдеW
– доля рабочих предприятия, имеющих среднемесячный доход 19 тыс. руб. и выше по выборке.
, гдеW
– доля рабочих предприятия, имеющих среднемесячный доход 19 тыс. руб. и выше по выборке. .
. .
.Ответ: доля рабочих предприятия, имеющих месячный доход 19 тыс. руб. и выше, с вероятностью 0,954 находится в пределах от 19,4% до 36,6%.
Определим необходимую численность выборки при определении среднего месячного дохода работников предприятия, чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб.
|
N = 1000 чел. |
Решение : необходимая численность выборки для определения среднего месячного дохода определяется по формуле (по табл. 8.4): По условию задачи известны: при вероятности Р = 0,954 t = 2 (см. табл. 8.2) ; 0,2 тыс. руб.;
|
 (по данным предыдущей выборки).
(по данным предыдущей выборки). чел.
чел.Ответ: чтобы с вероятностью 0,954 предельная ошибка выборки не превышала 200 руб., должны быть обследованы 189 чел.
4.5. Определение объема выборки
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.

Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где  .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
 ,
,
Практическая работа № 8. «Определение необходимого объёма выборки»
«Определение необходимого объёма выборки»
Наиболее широко распространенным видом несплошного наблюдения является выборочное наблюдение, при котором обследуются не все единицы изучаемой совокупности, а лишь определенным образом отобранная их часть.
Вся подлежащая изучению совокупность объектов (наблюдений) называется генеральной совокупностью. Выборочной совокупностью или выборкой называется часть генеральной совокупности, отобранная для изучения свойств обеспечивающая репрезентативность.
Отбор из генеральной совокупности проводится таким образом, чтобы на основе выборки можно было получить достаточно точное представление об основных параметрах совокупности в целом. При этом речь идет как о точечной оценке, в качестве которой принимается соответствующее значение средней, доли и т.д., полученное в результате выборки, так и об интервальной оценке, т.е. о тех пределах, в которых с определенной вероятностью может находиться значение искомого параметра в генеральной совокупности. Главное требование, которому должна отвечать выборочная совокупность, - это требование ее репрезентативности, т.е. представительности.
В статистике результаты сплошного наблюдения иногда оцениваются как выборочные характеристики. Такая трактовка полученных данных имеет место в тех случаях, когда число обследованных единиц невелико и нет твердой уверенности в том, что изучаемые характеристики не могут принимать иных значений, кроме выявленных в результате наблюдения. При проведении экспериментов число значений может быть бесконечно большим, поэтому, формулируя выводы на основе ограниченного их числа, необходимо рассматривать полученные данные как выборочные характеристики.
Распространяя результаты выборочного обследования на генеральную совокупность, следует иметь в виду, что между характеристиками генеральной и выборочной совокупности возможно расхождение, обусловленное тем, что обследуется не, вся совокупность, а лишь ее часть.
Ошибкой статистического наблюдения считается величина отклонения между расчетным и фактическим значениями признаков изучаемых объектов.
Выборочный метод обеспечивает значительную экономию материальных и финансовых ресурсов при проведении статистического наблюдения, что позволяет расширить программу обследования и повысить его оперативность. Второе преимущество – высокая достоверность получаемых данных, так как при относительно небольшом объеме выборки можно организовать эффективный контроль за качеством собираемой информации. Таким образом, снижается вероятность появления ошибок регистрации и необнаружения их на стадии проверки первичной информации. И наконец, в ряде случаев, когда сплошное наблюдение связано с уничтожением или порчей обследуемых единиц (например, при проверке качества поступающих в продажу продуктов питания), возможно только выборочное обследование.
Точность оценок, полученных на основе выборочного метода, зависит не от доли обследованных единиц, а от их числа.
Основные этапы выборочного наблюдения ;
1) определение цели, задач и составление программы наблюдения;
2) формирование выборки;
3) сбор данных на основе разработанной программы;
4) анализ полученных результатов и расчет основных характеристик выборочной совокупности;
5) расчет ошибки выборки и распространение ее результатов на генеральную совокупность.
Различают виды выборки :
1) случайная (собственно-случайная);
2) механическая (например, каждый 10, 20 и т.д.);
3) типическая (стратифицированная ), когда генеральная совокупность разбита на группы и в каждой группе обследуются по нескольку объектов));
4) серийная (гнездовая ), когда случайным образом отбираются целые серии.
Наиболее простой способ формирования выборочной совокупности – собственно случайный отбор. Теоретические основы выборочного метода, первоначально разработанные применительно к собственно случайному отбору, используют и для определения ошибок выборки при других способах наблюдения.
Собственно случайный отбор может быть повторным и бесповторным. При повторном отборе каждая единица, отобранная в случайном порядке из генеральной совокупности, после проведения наблюдения возвращается в эту совокупность и может быть вновь подвергнута обследованию. На практике такой способ отбора встречается редко. Гораздо более распространен собственно случайный бесповторный отбор, при котором обследованные единицы в генеральную совокупность не возвращаются и не могут быть обследованы повторно. При повторном отборе вероятность попадания в выборку для каждой единицы генеральной совокупности остается неизменной. При бесповторном отборе она меняется, но для всех единиц, оставшихся в генеральной совокупности после отбора из нее нескольких единиц, вероятность попадания в выборку одинакова.
Один из главных компонентов тщательно продуманного исследования – определение выборки и что такое репрезентативная выборка. Это как в примере с тортом. Ведь не обязательно съедать весь десерт, чтобы понять его вкус? Достаточно небольшой части.
Так вот, торт – это генеральная совокупность (то есть все респонденты, которые подходят для опроса). Она может быть выражена территориально, например, лишь жители Московской области. Гендерно – только женщины. Или иметь ограничения по возрасту – россияне старше 65 лет.
Высчитать генеральную совокупность сложно: нужно иметь данные переписи населения или предварительных оценочных опросов. Поэтому обычно генеральную совокупность «прикидывают», а из полученного числа высчитывают выборочную совокупность или выборку .
Что такое репрезентативная выборка?
Выборка – это чётко определенное количество респондентов. Её структура должна максимально совпадать со структурой генеральной совокупности по основным характеристикам отбора.
 Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Объем выборки определяется с учётом требований точности и экономичности. Эти требования обратно пропорциональны друг другу: чем больше объем выборки, тем точнее результат. При этом чем выше точность, тем соответственно больше затрат необходимо на проведение исследования. И наоборот, чем меньше выборка, тем меньше на неё затрат, тем менее точно и более случайно воспроизводятся свойства генеральной совокупности.
Поэтому для вычисления объема выбора социологами была изобретена формула и создан специальный калькулятор :
Доверительная вероятность и доверительная погрешность
Что означают термины «доверительная вероятность » и «доверительная погрешность »? Доверительная вероятность – это показатель точности измерений. А доверительная погрешность – это возможная ошибка результатов исследования. К примеру, при генеральной совокупности более 500 00 человек (допустим, проживающие в Новокузнецке) выборка будет равняться 384 человека при доверительной вероятности 95% и погрешности 5% ИЛИ (при доверительном интервале 95±5%).
Что из этого следует? При проведении 100 исследований с такой выборкой (384 человека) в 95 процентов случаев получаемые ответы по законам статистики будут находиться в пределах ±5% от исходного. И мы получим репрезентативную выборку с минимальной вероятностью статистической ошибки.
После того, как подсчет объема выборки выполнен, можно посмотреть есть ли достаточное число респондентов в демо-версии Панели Анкетолога . А как провести панельный опрос можно подробнее узнать .
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
|
Объем выборки, если генеральная совокупность 5000 | ||||||||
|
Фактическая ошибка при данном объёме выборки, % |
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.
Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где
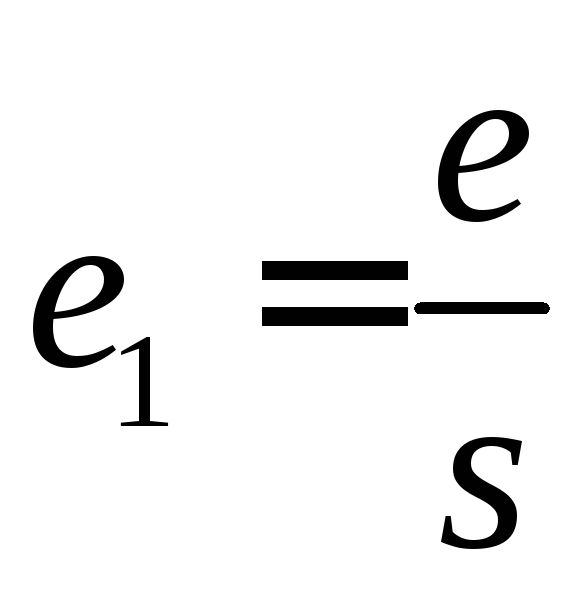 .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
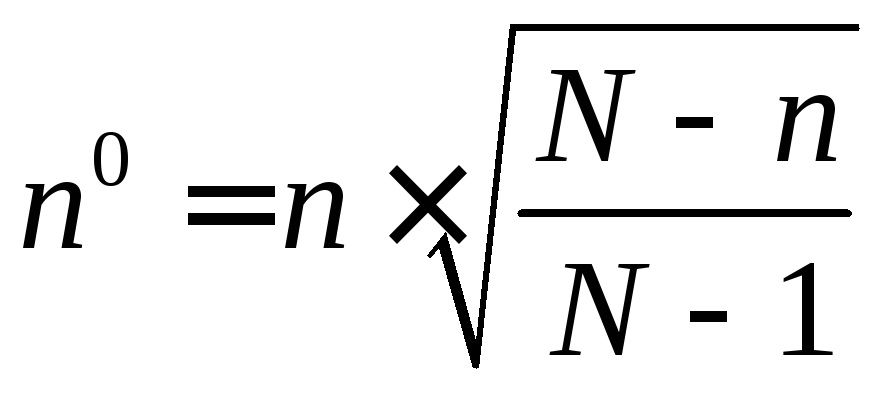 ,
,
где n - объем выборки для малой совокупности; n 0 – объем выборки, рассчитанный по приведенным выше формулам; N – объем генеральной совокупности.
Очевидно, что использование выборки меньших размеров приведет к экономии времени и средств.
Приведенные формулы расчета объема выборки основаны на предположении, что все правила формирования выборки были соблюдены и единственной ошибкой выборки является ошибка, обусловленная ее объемом. Однако, следует помнить, что объем выборки определяет точность полученных результатов, но не их представительность.
Последняя определяется методом формирования выборки. Все формулы для расчета объема выборки предполагают, что репрезентативность гарантируется использованием корректных вероятностных процедур формирования выборки.
Объем, выборки определяется аналитическими, задачами исследования, а ее репрезентативность - целевой установкой программы. Именно программа задает образ необходимой генеральной совокупности для проведения выборки. Будет ли это все население или особые его структурные образования, все элементы изучаемого объекта или только выделяемые по заданным программой критериям, генеральную совокупность составляют все единицы, определенного в программе объекта.
При детерминированном подхода к структуре выборки в общем случае не представляется возможным расчетным путем точно определить ее объем в соответствии с заданным критерием достоверности полученной информации. В этом случае объем выборки может быть определен эмпирически. Ориентиром здесь может служить опыт проведения маркетинговых исследований за рубежом. Так, при обследовании покупателей высокая точность выборки обеспечивается, даже если ее объем не превышает 1% всей совокупности при проведении опросов покупателей средних и крупных розничных фирм, количество опрашиваемых (объем выборки), как правило, колеблется от 500 до 1000 человек.
Значение процедуры выбора метода сбора первичной информации, и орудия исследования состоит в том, что результаты этого выбора определяют как достоверность и точность подлежащей сбору информации, так и продолжительность, и дороговизну ее сбора.
В каждой профессии есть свой набор любимых вопросов. Для исследователей рынка этот список возглавляет, безусловно, вопрос о размере выборки. Обычно его формулируют так:
- Мы хотели бы заказать исследование по посетителям московских торговых центров. Какая нам нужна выборка?
- Наша целевая аудитория – примерно 300 000 человек. Сколько людей нам нужно опросить, чтобы было репрезентативно? А если целевая аудитория будет 3 млн?
- Нам нужно оценить потенциал продаж квартир в Санкт-Петербурге жителям северных городов России. Какую сделать выборку?
Главное заблуждение о размере выборки
Многие уверены, что чем больше размер целевой группы, тем больше должен быть размер выборки. Поэтому, якобы, чтобы узнать мнение жителей маленького города, достаточно опросить человек 200-300, ну а для выяснения мнения по России в целом и 5000 будет мало.
Между тем, этот стереотип не имеет ничего общего с реальностью. Размер выборки не зависит от численности целевой группы (на языке статистики она называется «генеральной совокупностью») и определяется двумя совершенно другими факторами. Единственное исключение из этого правила – случаи, когда генеральная совокупность очень маленькая, например, 1-2 тысячи человек, но такие ситуации в реальной практике маркетинговых исследований встречаются редко.
Два фактора, от которых зависит размер выборки
Размер выборки массового опроса зависит от двух факторов:
- Точности данных, которые нужно получить на выходе – это та самая «статистическая погрешность». Для выборки в 100 респондентов она будет в пределах плюс-минус 10%, а для выборки в 1000 респондентов – в пределах плюс-минус 3,1%. Более подробно об этом – ниже.
- Количества и размера подгрупп, на которые нужно разбивать выборку при анализе. Например, если проводится электоральное исследование, то в основном нас будет интересовать ядро активных избирателей. Как правило, доля «ядра» редко превышает 20-25% от всего населения. Поэтому размер выборки нужно рассчитывать так, чтобы одна четверть от ее общего объема позволяла проводить полноценный статистический анализ.
Две разновидности ошибки выборки
Любое выборочное наблюдение (то есть когда мы опрашиваем не всех подряд, а делаем случайный отбор из генеральной совокупности) сопряжено с погрешностью данных. Эту погрешность обычно называют «ошибкой выборки». Она может быть двух видов:
- Систематическая – связана с ошибками проектирования выборки. Оценить ее размер, направление и степень смещения очень сложно, чаще всего – невозможно. Например, если вопросы респондентам будут задавать представители маргинальных социальных слоев, это повлияет на готовность участвовать в исследовании со стороны представителей более обеспеченных групп населения. В итоге это приведет к крайне трудно оцениваемой систематической ошибке и искажению данных.
- Случайная – связана с действием законов статистики. Ее размер легко рассчитывается по формулам математической статистики и теории вероятности. Они позволяют делать обоснованные выводы о доверительном интервале признака. Например, если статистическая погрешность составляет плюс-минус 10%, а полученное значение показателя оказалось равно 25%, то доверительный интервал равен от 15% до 35%.

Задача исследователя – собрать данные так, чтобы минимизировать систематическую ошибку выборки. Тогда можно будет свести статпогрешность лишь к случайной ошибке, которую можно рассчитать по формулам.
Как рассчитать размер случайной ошибки выборки
Случайная ошибка выборки зависит не только от объема выборки, но и от дисперсии, то есть степени однородности данных. Чем однороднее данные (т.е. чем меньше разброс полученных значений, или дисперсия), тем меньше ошибка выборки.
Существует формула расчета случайной ошибки выборки, однако для удобства рекомендуем пользоваться онлайн-калькуляторами, например, вот этим . Он позволяет легко провести два вида расчета:
- рассчитать величину статистической погрешности на основе размера выборки и предполагаемой дисперсии;
- определить размер выборки, требуемый для получения оценки нужной степени точности.

В качестве параметра доверительной надежности (одно из полей в калькуляторе) обычно используется значение в 95%. Это означает, что в 95% случаев распределение признака в генеральной совокупности попадет в рассчитанный доверительный интервал (т.е. само значение признака в выборке плюс-минус размер статистической погрешности). Реже используется значение надежности в 97% или 99% – оно, соответственно, означает, что подобное попадание произойдет в 97% или 99% случаев. В данном случае надежность выборки повышается, но увеличивается размер выборки.
Самое сложное при определении размера выборки – поиск компромисса между требуемой точностью и стоимостью сбора данных. Этот процесс усложняется тем, что увеличение размера выборки в четыре раза приводит к увеличению точности лишь в два раза (соответствует квадратному корню от величины прироста выборки).
Кейс: определение размера выборки для оценки потенциала рынка продаж столичной недвижимости покупателям из регионов
В ноябре-декабре 2016 года мы провели исследование спроса на квартиры в новостройках Москвы и Санкт-Петербурга со стороны жителей разных городов России. Исследование включало в себя три метода сбора данных: массовый репрезентативный опрос населения в возрасте от 20 до 60 лет (проводился с использованием технологии CATI), а также серию экспертных интервью с риэлторами и глубинных интервью с потенциальными покупателями квартир.
Исследование охватывало 33 города, отличающихся повышенным спросом на петербургскую и московскую недвижимость. Плановая выборка исследования, рассчитанная по формулам, составила 21 500 респондентов. Этот объем значительно больше «стандартного» объема выборки, используемого в маркетинговых исследованиях. С чем же связан такой большой размер выборки?
Все дело в том, что клиенту были нужны оценки отдельно по каждому городу, а не просто «в целом по стране». Фактически мы работаем не с 1 выборкой, а с 33 отдельными выборками по каждому городу. Доля людей, заинтересованных в покупке квартиры в Санкт-Петербурге или Москве, была экспертно определена в рамках 5% от числа жителей опрашиваемых городов.
В зависимости от важности города для заказчика, руководитель проекта со стороны Агентства определил допустимую статистическую погрешность, в которую должны укладываться итоговые результаты. Для этого мы использовали специальный макрос в MS Excel, но эти расчеты можно также выполнить с помощью калькулятора выборки. В результате размер выборки варьировал от 500 до 1000 респондентов по каждому из городов исследования, что в сумме и дало заявленные 21 500 человек.
- Определите структуру целевой группы. Планируете ли вы анализировать отдельные подгруппы или достаточно будет анализа по выборке в целом?
- Определите желаемую точность данных. Например, если нужно оценить динамику рыночной доли за год, подставьте в специальный калькулятор примерное значение доли и «поиграйте» с разными объемами выборки.
- Найдите баланс между стоимостью сбора данных (прямо пропорциональна объему выборки) и требуемой точностью.
На практике решение вопроса об объеме выборки является компромиссным между предположением о точности результатов обследования и возможностями их практической реализации (т.е. исходя из затрат на проведение опроса).
На практике используется несколько подходов к определению объема выборки. Обратим внимание на самые простые из них. Первый из них называется произвольным подходом и основан он на применении «правила большого пальца».
Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход простой и доступный в исполнении, не позволяет получать точные результаты. Его достоинством является относительная дешевизна затрат. В соответствии со вторым подходом объем выборки может быть установлен исходя из заранее оговоренных условий. Заказчик маркетингового исследования, например, знает, что при изучении общественного мнения выборка обычно составляет 1000 - 1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры.
Третий подход означает, что в некоторых случаях главным аргументом при определении объема выборки может быть стоимость проведения опроса. Хотя при этом ценность и достоверность получаемой информации не принимается в расчет.
В случае четвертого подхода объем выборки определяется на основе статистического анализа. Данный подход предполагает определение минимального объема выборки с учетом требований к надежности и достоверности получаемых результатов.
Пятый подход считается наиболее теоретически обоснованным и правильным подходом в определении объема выборки. Он основан на расчете доверительного интервала.
Доверительный интервал - это диапазон, крайние точки которого характеризуют процент определенных ответов на какой-то вопрос. Данное понятие тесто связано с понятием «среднее квадратичное отклонение получаемого признака в генеральной совокупности». Чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав, например 9,5 % ответов.
Из свойств нормальной кривой распределения вытекает, что конечные точки доверительного интервала, равного к примеру 9,5 % определяются как произведение: 1,96 (нормированное отклонение) и среднего квадратичного отклонения.
Числа 1,96 и 2,58 (для 99 % доверительного интервала) обозначаются как z.
Существуют таблицы «Значение интеграла вероятности», которые дают возможность определить величины z для различных доверительных интервалов. Доверительный интервал равный 95% или 99% является стандартным при проведении маркетинговых исследований.
Например, проведено исследование числа визитов автовладельцев в сервисные мастерские за год. Доверительный интервал для среднего числа визитов был рассчитан равным 5 - 7 визитам при 99 % уровне доверительности. Это означает, что если появится возможность, провести независимо 100 раз выборочные исследования, то для 99 выборочных исследований среднее значение числа визитов попадут в диапазон от 5 до 7 визитов, Если сказать иначе, то 99 % автовладельцев попадут в доверительный интервал.
Допустим, было проведено исследование до 50 независимых выборок. Средние оценки для этих выборок образовали нормальную кривую распределения, которое называется выборочным распределением.
Средняя оценка для совокупности в целом равна средней оценке кривой распределения. Понятие «выборочное распределение» рассматривается также в качестве одного из базовых понятий теоретической концепции, лежащее в основе определения V выборки.
Естественно ни одна компания не в состоянии сформировать 10, 20, 50 независимых выборок. Обычно используется только одна выборка.
Математическая статистика позволяет получить некую информацию о выборочном распределении, владея точными данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, которая ожидается для типичной выборки, является средне квадратическая ошибка . К примеру, исследуется мнение потребителей о новом товаре и заказчик данного исследования указал, что его устроит точность полученных результатов, равная плюс минус 5%.
Предположим, что 30 % членов выборки высказались за новый продукт. Это означает, что диапазон возможных оценок для всей совокупности составляет 25 - 35 %. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Определим объем выборки на основе расчета доверительного интервала. Исходной информацией, необходимой для реализации данного подхода, является:
· величина вариации, которой, как считается, обладает совокупность;
· желаемая точность;
· уровень достоверности, которому должны удовлетворять результаты проводимого обследования.
Когда на заданный вопрос существует только два варианта ответов, выраженных в процентах (используется процентная мера), объем выборки определяется по следующей формуле:
где n - объем выборки;
z - нормированное отклонение, определяемое исходя из выбранного уровня доверительности (табл. 7);
р - найденная вариация для выборки;
е - допустимая ошибка.
Таблица 7
Значение нормированного отклонения оценки z от среднего значения
в зависимости от доверительной вероятности (а) полученного результата
Например, предприятием, выпускающим покрышки, проводится опрос автолюбителей, использующих радиальные покрышки.
Поэтому на вопрос: «Используете ли Вы радиальные покрышки?» возможны только 2 ответа: «Да» или «Нет». Если предположить, что совокупность автолюбителей обладает низким показателем вариации, то это означает, что почти каждый опрошенный использует радиальные покрышки. В данном случае может быть сформирована выборка достаточно малых размеров. В формуле (1) произведение pg выражает вариацию, свойственную совокупности. Например, пусть 90 % единиц совокупности используют радиальные покрышки. Это означает, что pg = 900. Если принять, что показатель вариации выше (р = 70 %), то pg = 2100. Наибольшая вариация достигается в случае, когда одна половина совокупности (50 %) использует радиальные покрышки, а другие не используют. В этом случае произведение достигает значения равного 2500.
При проведении опроса важно указывать точность полученных оценок. Например, было установлено, что 44 % респондентов используют радиальные покрышки. Результаты измерения необходимо представить в виде: процент автолюбителей, использующих радиальные покрышки, составляет 44 плюс - минус е %. Величина допустимой ошибки заранее совместно определяется заказчиком исследования и исполнителем.
Уровень достоверности при проведении маркетинговых исследований обычно оценивается с учетом двух его значений: 95% или 99%. Первому значению соответствует значение z = 1,96; второму - z = 2,58. Если выбирается уровень доверительности равный 99 %, то это говорит о следующем: мы уверены на 99 % (иными словами доверительная вероятность равна 0,99) в том, что процент членов совокупности, попавший в диапазон плюс - минус е %, равен проценту членов выборки, попавших в тот же диапазон ошибки. Принимая вариацию равной 50 %, точность равной 10 % при 95 %-м уровне доверительности рассчитаем размер выборки:
n = 1,962 (50 х 50) / 102 = 96.
При уровне доверительности равном 99 %, и е = ±3 %, n = 1067.
При определении показателя вариации для конкретной совокупности целесообразно проводить предварительно качественный анализ исследуемой совокупности и установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно определение объема выборки на основе использования средних значений, а не процентных величин. Предположим, что выбран уровень достоверности равный 95 % (z = 1.96,), среднеквадратическое отклонение (S) рассчитано и равно 100, и желаемая точность (погрешность) составляет ±10. Тогда объем выборки составит
Реально на практике, если выборка формируется заново и схожие опросы не проводились, S неизвестно.
В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
Мы в основном говорили о совокупности очень больших размеров, характерных для рынков потребительских товаров. Но в отдельных случаях совокупности не являются столь большим, и например на рынках отдельных видов продукции производственного назначения.
Обычно, если выборка составляет менее 5 % совокупности, то совокупность считается большой, и расчеты проводятся по вышеприведенным правилам.
Если же V выборки превышает 5 % совокупности, то последняя считается малой, и в вышеприведенные формулы вводится поправочный коэффициент. Объем выборки в данном случае определяется следующим образом:
где n1 - объем выборки для малой совокупности,
n - объем выборки (или для процентных мер или для средних), рассчитанный по приведенным выше формулам,
N - объем генеральной совокупности.
Например, изучается мнение членов совокупности, состоящей из 1000 компаний, относительно строительства химического комбината в границах города Томска. Вследствие отсутствия информации о вариации принимается наихудший случай: 50:50. Исследователь вынес решение использовать уровень доверительности равный 95 %. Заказчик исследования указал, что его устроит точность результатов плюс минус 5 %. В этом случае используется следующая формула для процентной меры:
Данный подход к формированию V выборки с определенными оговорками может быть использован и при расчете численности панели и экспертной группы.
Приведенные формулы расчета выборки основаны на предположении, что все правила формирования выборки были соблюдены, и единственной ошибкой является ошибка, обусловленная ее объемом.
Ф. Котлер Маркетинг-менеджмент /Пер. с англ. - 9-е Международное изд-е. - СПб: Питер Ком., 1998. - С.174
Ф. Котлер и другие. Основы маркетинга. -М;СПб., 1999. С - 370.







