Сервис позволит провести сглаживание временного ряда y t экспоненциальным методом, т.е. простроить модель Брауна (см. пример).
Инструкция . Укажите количество данных (количество строк), нажмите Далее. Полученное решение сохраняется в файле Word .
Особенность метода экспоненциального сглаживания заключается в том, что в процедуре нахождения сглаженного уровня используются значения только предшествующих уровней ряда, взятые с определенным весом, причем вес уменьшается по мере удаления его от момента времени, для которого определяется сглаженное значение уровня ряда. Если для исходного временного ряда y 1 , y 2 , y 3 ,…, y n соответствующие сглаженные значения уровней обозначить через S t , t = 1,2,...,n , то экспоненциальное сглаживание осуществляется по формуле:S t = (1-α)yt + αS t-1
В некоторых источниках приводится другая формула:
S t = αyt + (1-α)S t-1
Где α - параметр сглаживания (0 В практических задачах обработки экономических временных рядов рекомендуется (необоснованно) выбирать величину параметра сглаживания в интервале от 0.1 до 0.3 . Других точных рекомендаций для выбора оптимальной величины параметра α пока нет. В отдельных случаях предлагается определять величину α исходя их длины сглаживаемого ряда: α = 2/(n+1).
Что касается начального параметра S 0 , то в задачах его берут или равным значению первого уровня ряда у 1 , или равным средней арифметической нескольких первых членов ряда.
Если при подходе к правому концу временного ряда сглаженные этим методом значения при выбранном параметре α начинают значительно отличаться от соответствующих значений исходного ряда, необходимо перейти на другой параметр сглаживания. Достоинством этого метода является то, что при сглаживании не теряются ни начальные, ни конечные уровни сглаживаемого временного ряда.
Сглаживание экспоненциальным методом в Excel
Для вычисления каждого прогноза MS Excel использует отдельную, но алгебраически эквивалентную формулу. Оба компонента – данные предыдущего наблюдения и предыдущий прогноз – каждого прогноза умножаются на коэффициент, отображающий вклад данного компонента в текущий прогноз.Активизировать средство Экспоненциальное сглаживание можно, выбрав команду Сервис/Анализ данных после загрузки надстройки Пакет анализа ().
Пример
. Проверить ряд на наличие выбросов методом Ирвина, сгладить методом экспоненциального сглаживания (α = 0.1).
В качестве S 0 берем среднее арифметическое первых 3 значения ряда.
S 0 = (50 + 56 + 46)/3 = 50.67
| t | y | S t | Формула |
| 1 | 50 | 50.07 | (1 - 0.1)*50 + 0.1*50.67 |
| 2 | 56 | 55.41 | (1 - 0.1)*56 + 0.1*50.07 |
| 3 | 46 | 46.94 | (1 - 0.1)*46 + 0.1*55.41 |
| 4 | 48 | 47.89 | (1 - 0.1)*48 + 0.1*46.94 |
| 5 | 49 | 48.89 | (1 - 0.1)*49 + 0.1*47.89 |
| 6 | 46 | 46.29 | (1 - 0.1)*46 + 0.1*48.89 |
| 7 | 48 | 47.83 | (1 - 0.1)*48 + 0.1*46.29 |
| 8 | 47 | 47.08 | (1 - 0.1)*47 + 0.1*47.83 |
| 9 | 47 | 47.01 | (1 - 0.1)*47 + 0.1*47.08 |
| 10 | 49 | 48.8 | (1 - 0.1)*49 + 0.1*47.01 |
Экспоненциальное сглаживание – более сложный метод взвешенного среднего. Каждый новый прогноз основан на предыдущем прогнозе плюс процент разницы между этим прогнозом и фактическим значением ряда в этой точке.
F t = F t -1 + (A t -1 - F t -1) (2)
Где: F t – прогноз для периода t
F t -1 – прогноз для периода t-1
– сглаживающая константа
A t - 1 – фактический спрос или продажи для периода t-1
Константа сглаживания представляет собой процент от ошибки прогноза. Каждый новый прогноз равен предыдущему прогнозу плюс процент от предыдущей ошибки.
Чувствительность корректировки прогноза к ошибке определена константой сглаживания , чем ближе её значение к 0 , тем медленнее прогноз будет приспосабливаться к ошибкам прогноза (т.е. тем больше степень сглаживания). Наоборот, чем ближе значение к 1,0 , тем выше чувствительность и меньше сглаживание.
Выбор константы сглаживания – в основном вопрос свободного выбора или метода проб и ошибок. Цель состоит в том, чтобы выбрать такую константу сглаживания, чтобы, с одной стороны, прогноз остался достаточно чувствительным к реальным изменениям данных временного ряда, а с другой – хорошо сглаживал скачки, вызванные случайными факторами. Обычно используемые значения находятся в диапазоне от 0,05 до 0,50.
Экспоненциальное сглаживание – один из наиболее широко используемых методов прогнозирования, частично из – за минимальных требований по хранению данных и легкости вычисления, а частично из-за той лёгкости, с которой система коэффициентов значимости может быть изменена простым изменением значения .
Таблица 3. Экспоненциальное сглаживание
| Период | Фактический спрос | α= 0,1 | α = 0,4 | ||
| прогноз | ошибка | прогноз | ошибка | ||
| 10 000 | - | - | - | - | |
| 11 200 | 10 000 | 11 200-10 000=1 200 | 10 000 | 11 200-10 000=1 200 | |
| 11 500 | 10 000+0,1(11 200-10 000)=10 120 | 11 500-10 120=1 380 | 10 000+0,4(11 200-10 000)=10 480 | 11 500-10 480=1 020 | |
| 13 200 | 10 120+0,1(11 500-10 120)=10 258 | 13 200-10 258=2 942 | 10 480+0,4(11 500-10 480)=10 888 | 13 200-10 888=2 312 | |
| 14 500 | 10 258+0,1(13 200-10 258)=10 552 | 14 500-10 552=3 948 | 10 888+0,4(13 200-10 888)=11 813 | 14 500-11 813=2 687 | |
| - | 10 552+0,1(14 500-10 552)=10 947 | - | 11 813+0,4(14 500-11 813)=12 888 | - |

Методы для тенденции
Существует два важных метода, которые можно использовать для разработки прогнозов, когда присутствует тенденция. Один из них предполагает использование уравнения тенденции; другой – расширение экспоненциального сглаживания.
Уравнение тенденции:
Линейное уравнение тенденции имеет следующий вид:
Y t = a + δ∙ t (3)
Где: t – определённое число периодов времени от t= 0 ;
Y t – прогноз периода t ;
α – значение Y t при t=0
δ – наклон линии.
Коэффициенты прямой α и δ , могут быть вычислены из статистических данных за определённый период, с использованием следующих двух уравнений:
δ=
![]() , (4)
, (4)
α = , (5)
Где: n – число периодов,
y – значение временного ряда
Таблица 3. Уровень тенденции.
| Период (t) | Год | Уровень продаж (y) | t∙y | t 2 | |
| 10 000 | 10 000 | ||||
| 11 200 | 22 400 | ||||
| 11 500 | 34 500 | ||||
| 13 200 | 52 800 | ||||
| 14 500 | 72 500 | ||||
| Итого: | - | 60 400 | 192 200 |
Вычислим коэффициенты линии тенденции:
δ=
![]()
![]()
Таким образом, линия тенденции Y t = α + δ ∙ t
В нашем случае, Y t = 43 900+1 100 ∙t ,
Где t = 0 для периода 0.
Составим уравнение для периода 6 (2015 год) и 7 (2016 год):
– прогноз на 2015 год.
Y 7 = 43 900+1 100*7= 51 600
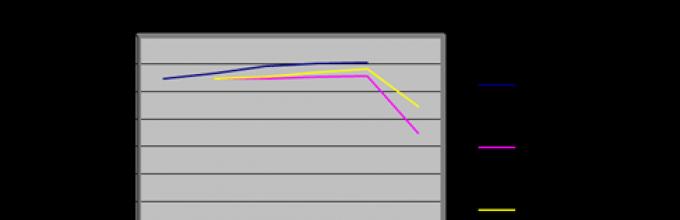
Построим график:

Экспоненциальное сглаживание тенденций
Разновидность простого экспоненциального сглаживания может использоваться, когда временной ряд выявляет тенденцию. Эта разновидность называется экспоненциальным сглаживание, учитывающим тенденцию или, иногда, двойным сглаживанием. Оно отличается от простого экспоненциального сглаживания, которое используется только тогда, когда данные изменяются вокруг некоторого среднего значения или имеют скачкообразные или постепенные изменения.
Если ряд выявляет тенденцию и при этом используется простое экспоненциальное сглаживание, то все прогнозы будут запаздывать по отношению к тенденции. Например, если данные увеличиваются, то каждый прогноз будет занижен. Наоборот, уменьшение данных даёт завышенный прогноз. Графическое отображение данных может показать, когда двойное сглаживание будет предпочтительнее, чем простое.
Скорректированный тенденцией прогноз (TAF) состоит из двух элементов: сглаженной ошибки и фактора тенденции.
TAF t +1 = S t + T t , (6)
Где: S t – сглаженный прогноз;
T t – оценка текущей тенденции
И S t = TAF t + α 1 (A t - TAF t) , (7)
T t = T t-1 + α 2 (TAF t –TAF t-1 – T t-1) (8)
Где α 1 , α 2 – сглаживающие константы.
Чтобы использовать этот метод, нужно выбрать значения α 1 , α 2 (обычным путём подбора) и сделать начальный прогноз и оценку тенденций.
Таблица 4. Экспоненциальное сглаживание тенденции.

9 5. Метод экспоненциального сглаживания. Выбор постоянной сглаживания
При использовании метода наименьших квадратов для определения прогнозной тенденции (тренда) заранее предполагают, что все ретроспективные данные (наблюдения) обладают одинаковой информативностью. Очевидно, логичнее было бы учесть процесс дисконтирования исходной информации, то есть неравноценность этих данных для разработки прогноза. Это достигается в методе экспоненциального сглаживания путем придания последним наблюдения динамического ряда (то есть значениям, непосредственно предшествующим периоду упреждения прогноза) более значимых «весов» по сравнению с начальными наблюдениями. К достоинствам метода экспоненциального сглаживания следует также отнести простоту вычислительных операций и гибкость описания различных динамик процесса. Наибольшее применения метод нашел для реализации среднесрочных прогнозов .
5.1. Сущность метода экспоненциального сглаживания
Сущность метода состоит в том, что динамический ряд сглаживается с помощью взвешенной «скользящей средней», в которой веса подчиняются экспоненциальному закону. Другими словами, чем дальше от конца временного ряда отстоит точка, для которой вычисляется взвешенная скользящая средняя, тем меньше «участия она принимает» в разработке прогноза.
Пусть исходный динамический ряд состоит из уровней (составляющих ряда) y t , t = 1 , 2 ,...,n . Для каждыхm последовательных уровней этого ряда
(m динамическому ряду с шагом, равным единице. Если m
– нечетное число, а предпочтительно брать нечетное число уровней, поскольку в этом случае расчетное значение уровня окажется в центре интервала сглаживания и им легко заменить фактическое значение, то для определения скользящей средней можно записать следующую формулу: t+
ξ
t+
ξ
∑ y
i
∑ y
i
i=
t−
ξ
i=
t−
ξ
2ξ
+
1 где y
t
– значение скользящей средней для моментаt
(t
=
1
,
2
,...,n
);y
i
– фактическое значение уровня в моментi
; i
– порядковый номер уровня в интервале сглаживания. Величина ξ
определяется из продолжительности интервала сглаживания. Поскольку m
=2
ξ
+1
при нечетном m
, то ξ =
m
2
−
1
.
Расчет скользящей средней при большом числе уровней можно упростить, определяя последовательные значения скользящей средней рекурсивно: y
t=
y
t−
1
+
yt
+
ξ
− y
t
−
(ξ
+
1
)
2ξ
+
1 Но исходя из того, что последним наблюдениям необходимо придать больший «вес», скользящее среднее нуждается в ином толковании. Оно заключается в том, что полученная с помощью усреднения величина заменяет не центральный член интервала усреднения, а его последний член. Соответственно этому последнее выражение можно переписать в виде M i
=
Mi
+
1
y
i−
y
i−
m Здесь скользящая средняя, относимая к концу интервала, обозначена новым символом M
i
. По существу,M
i
равноy
t
, сдвинутому наξ
шагов вправо, то естьM
i
=
y
t
+
ξ
, гдеi
=
t
+
ξ
. Учитывая, что M
i
−
1
является оценкой величиныy
i
−
m
, выражение (5.1) можно переписать в виде y
i+
1
M i
−
1
,
M
i
, определяемой выражением (5.1). где M
i
является оценкой Если вычисления (5.2) повторять по мере поступления новой информации и переписать в ином виде, то получим сглаженную функцию наблюдений: Q
i=
α
y
i+
(1
−
α
)
Q
i−
1
,
или в эквивалентной форме Q
t=
α
y
t+
(1
−
α
)
Q
t−
1
Вычисления, проводимые по выражению (5.3) с каждым новым наблюдением, называются экспоненциальным сглаживанием. В последнем выражении для отличия экспоненциального сглаживания от скользящего среднего введено обозначение Q
вместоM
. Величинаα
, являющаяся аналогом m
1
, называется постоянной сглаживания. Значенияα
лежат в интервале [
0
,
1
]
. Еслиα
представить в виде ряда α +
α(1
−
α)
+
α(1
−
α)
2
+
α(1
−
α)
3
+
...
+
α(1
−
α)
n
,
то нетрудно заметить, что «веса» убывают по экспоненциальному закону во времени. Например, для α
=
0
,
2
получим 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … Сумма ряда стремится к единице, а члены суммы убывают со временем. Величина Q
t
в выражении (5.3) представляет собой экспоненциальную среднюю первого порядка, то есть среднюю, полученную непосредственно при сглаживании данных наблюдения (первичное сглаживание). Иногда при разработке статистических моделей полезно прибегнуть к расчету экспоненциальных средних более высоких порядков, то есть средних, получаемых путем многократного экспоненциального сглаживания. Общая запись в рекуррентной форме экспоненциальной средней порядка k
имеет вид Q
t
(k)=
α
Q
t
(k−
1
)+
(1
−
α
)
Q
t
(−
k1
).
Величина k
изменяется в пределах1, 2, …, p
,p+1
, гдеp
– порядок прогнозного полинома (линейного, квадратичного и так далее). На основе этой формулы для экспоненциальной средней первого, второго и третьего порядков получены выражения Q
t
(1
)=
α
y
t
+
(1
−
α
)
Q
t
(−
1
1
);
Q
t
(2
)=
α
Q
t
(1
)+
(1
−
α
)
Q
t
(−
2
1
);
Q
t
(3
)=
α
Q
t
(2
)+
(1
−
α
)
Q
t
(−
3
1
).
5.2. Определение параметров прогнозной модели методом экспоненциального сглаживания Очевидно, что для разработки прогнозных значений на основе динамического ряда методом экспоненциального сглаживания необходимо вычислить коэффициенты уравнения тренда через экспоненциальные средние. Оценки коэффициентов определяются по фундаментальной теореме БраунаМейера, связывающей коэффициенты прогнозирующего полинома с экспоненциальными средними соответствующих порядков: (−
1
) aˆ p
α
(1
−
α
)∞
−α
)
j
(p
−
1
+
j
)
!
∑ j
p=
0
p! (k−
1
)
!j
=
0
где aˆ
p
– оценки коэффициентов полинома степенир
. Коэффициенты находятся решением системы (p
+
1
) уравнений сp
+
1
неизвестными. Так, для линейной модели aˆ
0
=
2
Q
t
(1
)
−
Q
t
(2
)
;
aˆ
1
=
1
−
α
α
(Q
t
(1
)−
Q
t
(2
))
;
для квадратичной модели aˆ
0
=
3
(Q
t
(1
)−
Q
t
(2
))
+
Q
t
(3
);
aˆ
1
=1
−
α
α
[
(6
−5
α
)
Q
t
(1
)
−2
(5
−4
α
)
Q
t
(2
)
+(4
−3
α
)
Q
t
(3
)
]
;
aˆ
2
=
(1
−
α
α
)
2
[
Q
t
(1
)−
2
Q
t
(2
)+
Q
t
(3
)]
.
Прогноз реализуется по выбранному многочлену соответственно для линейной модели ˆyt
+
τ
=
aˆ0
+
aˆ1
τ
;
для квадратичной модели ˆyt
+
τ
=
aˆ0
+
aˆ1
τ
+
aˆ
2
2
τ
2
,
где τ
– шаг прогнозирования. Необходимо отметить, что экспоненциальные средние Q
t
(k
)
можно вычислить только при известном (выбранном) параметре, зная начальные условияQ
0
(k
)
. Оценки начальных условий, в частности, для линейной модели Q
(1
)=
a
1 −
α
Q(2
)
=
a−
2
(1
−
α
)
a для квадратичной модели Q
(1
)=
a
1 −
α
+
(1
−
α
)(2
−
α
)
a
2(1−
α
)
(1−
α
)(3−
2α
)
Q
0(2
)
=
a
0−
2α
2
Q
(3
)=
a
3(1−
α
)
(1
−
α
)(4
−
3
α
)
a
где коэффициенты a
0
иa
1
вычисляются методом наименьших квадратов. Величина параметра сглаживания α
приближенно вычисляется по формуле α ≈
m
2
+
1
,
где m
– число наблюдений (значений) в интервале сглаживания. Последовательность вычисления прогнозных значений представлена на Расчет коэффициентов ряда методом наименьших квадратов Определение интервала сглаживания Вычисление постоянной сглаживания Вычисление начальных условий Вычисление экспоненциальных средних Вычисление оценок a
0
, a
1
и т.д. Расчет прогнозных значений ряда Рис. 5.1. Последовательность вычисления прогнозных значений В качестве примера рассмотрим процедуру получения прогнозного значения безотказной работы изделия, выражаемой наработкой на отказ. Исходные данные сведены в табл. 5.1. Выбираем линейную модель прогнозирования в виде y
t
=
a
0
+
a
1
τ
Решение осуществим со следующими значениями начальных величин: a
0
,
0
=
64,
2;
a
1
,
0
=
31,
5;
α
=
0,
305.
Таблица 5.1.
Исходные данные Номер наблюдения, t
Длина шага, прогнозирования, τ
Наработка на отказ, y
(час) При этих значениях вычисленные «сглаженные» коэффициенты для величины y
2
будут равны =
α
Q
(1
)−
Q
(2
)=
97
,
9
;
[
Q
(1
)−
Q
(2
) 31,
9 , 1−
α
при начальных условиях 1 −
α
A
0
,
0
− a
1,
0 = −7
,
6
1 −
α
= −79
,
4
и экспоненциальных средних Q
(1
)=
α
y
+
(1
−
α
)
Q
(1
) 25,
2;
Q
(2
) =
α
Q
(1
) + (1
−α
)
Q
(2
)
= −47
,
5
.
«Сглаженная» величина y
2
при этом вычисляется по формуле
Q
i
(1
) Q
i
(2
) a
0
,i a
1
,i ˆyt
Таким образом (табл. 5.2), линейная прогнозная модель имеет вид ˆy
t
+
τ
=
224,
5+
32τ
.
Вычислим прогнозные значения для периодов упреждения в 2 года (τ
=
1
), 4 года (τ
=
2
) и так далее наработки на отказ изделия (табл. 5.3). Таблица 5.3.
Прогнозные значенияˆy
t
Уравнение t +
2
t +
4
t +
6
t +
8
t +
20
регрессии (τ
=
1
) (τ
=
2
) (τ
=
3
) (τ
=
5
) τ =
ˆy
t
=
224,
5+
32τ
Следует отметить, что суммарный «вес» последних m
значений временного ряда можно вычислить по формуле c
=
1
−
(m
(−
1
)
m
)
.
m+
1
Так, для двух последних наблюдений ряда (m
=
2
) величинаc
=
1
−
(2
2
−
+
1
1
)
2
=
0
,
667
. 5.3. Выбор начальных условий и определение постоянной сглаживания Как следует из выражения Q
t=
α
y
t+
(1
−
α
)
Q
t−
1
,
при проведении экспоненциального сглаживания необходимо знать начальное (предыдущее) значение сглаживаемой функции. В некоторых случаях за начальное значение можно взять первое наблюдение, чаще начальные условия определяются согласно выражениям (5.4) и (5.5). При этом величины a
0
,
0
,a
1
,
0
и a
2
,
0
определяются методом наименьших квадратов. Если мы не очень доверяем выбранному начальному значению, то, взяв большое значение постоянной сглаживания α
черезk
наблюдений, мы доведем «вес» начального значения до величины (1
−
α
)
k
<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Таким образом, выбор постоянной сглаживания (или числа наблюдений в движущейся средней) предполагает принятие компромиссного решения. Обычно, как показывает практика, величина постоянной сглаживания лежит в пределах от 0,01 до 0,3. Известно несколько переходов, позволяющих найти приближенную оценку α
. Первый вытекает из условия равенства скользящей и экспоненциальной средней α =
m
2
+
1
,
где m
– число наблюдений в интервале сглаживания. Остальные подходы связываются с точностью прогноза. Так, возможно определение α
исходя из соотношения Мейера: α ≈
S
y
,
где S
y
– среднеквадратическая ошибка модели; S
1
– среднеквадратическая ошибка исходного ряда. Однако использование последнего соотношения затруднено тем, что достоверно определить S
y
иS
1
из исходной информации весьма сложно. Часто параметр сглаживания, а заодно и коэффициенты a
0
,
0
иa
0
,
1
подбирают оптимальными в зависимости от критерия S 2
=
α
∑
∞
(1
−
α
)
j
[
yij
−
ˆyij
]
2
→
min j=
0
путем решения алгебраической системы уравнений, которую получают, приравнивая к нулю производные ∂
S2
∂
S2
∂
S2
∂
a
0,
0 ∂
a
1,
0 ∂
a
2,
0 Так, для линейной модели прогнозирования исходный критерий равен S 2
=
α
∑
∞
(1
−
α
)
j
[
yij
−
a0
,
0
−
a1
,
0
τ
]
2
→
min.
j=
0
Решение этой системы с помощью ЭВМ не представляет никаких сложностей. Для обоснованного выбора α
также можно использовать процедуру обобщенного сглаживания, которая позволяет получить следующие соотношения, связывающие дисперсию прогноза и параметр сглаживания для линейной модели: S
п
2
≈[
1
+
α
β
]
2
[
1
+4
β
+5
β
2
+2
α
(1
+3
β
)
τ
+2
α
2
τ
3
]
S
y
2
для квадратичной модели S
п
2≈
[
2
α
+
3
α
3+
3
α
2τ
]
S
y
2,
где β
=
1
−
α
;S
y
– СКО аппроксимации исходного динамического ряда. Скользящая средняя позволяет прекрасно сглаживать данные. Но ее главный недостаток заключатся в том, что каждое значение в исходных данных для нее имеет одинаковый вес. Например, для средней скользящей использующей период шести недель каждому значению для каждой недели уделяется 1/6 веса. В случае некоторых собранных статистических данных более актуальным значениям присваивается больший вес. Поэтому экспоненциальное сглаживание применятся для того, чтобы придать самым актуальным данным большего веса. Таким образом решается данная статистическая проблема. Ниже на рисунке изображен отчет спроса на определенный продукт за 26 недель. Столбец «Спрос» содержит информацию о количестве проданного товара. В столбце «Прогноз» – формула: В столбце «Скользящая средняя» определяется прогнозируемый спрос, рассчитанный с помощью обычного вычисления скользящей средней с периодом 6 недель: В последнем столбце «Прогноз», с описанной выше формулой применяется метод экспоненциального сглаживания данных в которых значения последних недель имеет больший вес чем предыдущих. Коэффициент «Альфа:» вводится в ячейке G1, он значит вес присвоения наиболее актуальным данным. В данном примере он имеет значение 30%. Остальные 70% веса распределяется на остальные данные. То есть второе значение с точки зрения актуальности (с право на лево) имеет вес равный 30% от оставшихся 70% веса – это 21%, третье значение имеет вес равен 30% от остальной части 70% веса – 14,7% и так далее. Ниже на рисунке изображен график спроса, среднее скользящие и прогноз методом экспоненциального сглаживания, который построен на основе исходных значений: Обратите внимание, что прогноз с экспоненциальным сглаживанием более активно реагирует на изменения спроса чем скользящая средняя линия. Данные для очередных предыдущих недель умножаются на коэффициент альфа, а результат добавляется к оставшейся части процентов веса умноженный на предыдущее прогнозируемое значение. Экспоненциальное сглаживание -
способ сглаживания временных рядов, вычислительная процедура которого включает обработку всех предыдущих наблюдений, при этом учитывается устаревание информации по мере удаления от прогнозного периода. Иначе говоря, чем "старше" наблюдение, тем меньше оно должно влиять на величину прогнозной оценки. Идея экспоненциального сглаживания состоит в том, что по мере "старения" соответствующим наблюдениям придаются убывающие веса. Данный метод прогнозирования считается весьма эффективным и падежным. Основные достоинства метода состоят в возможности учета весов исходной информации, в простоте вычислительных операций, в гибкости описания различных динамик процессов. Метод экспоненциального сглаживания дает возможность получить оценку параметров тренда, характеризующих не средний уровень процесса, а тенденцию, сложившуюся к моменту последнего наблюдения. Наибольшее применение метод нашел для реализации среднесрочных прогнозов. Для метода экспоненциального сглаживания основным моментом является выбор параметра сглаживания (сглаживающей константы) и начальных условий. Простое экспоненциальное сглаживание временных рядов, содержащих тренд, приводит к систематической ошибке, связанной с отставанием сглаженных значений от фактических уровней временного ряда. Для учета тренда в нестационарных рядах применяется специальное двухпараметрическое линейное экспоненциальное сглаживание. В отличие от простого экспоненциального сглаживания с одной сглаживающей константой (параметром) данная процедура сглаживает одновременно случайные возмущения и тренд с использованием двух различных констант (параметров). Двухпараметрический метод сглаживания (метод Хольта) включает два уравнения. Первое предназначено для сглаживания наблюденных значений, а второе -для сглаживания тренда: где I - 2,
3, 4 - периоды сглаживания; 5, - сглаженная величина на период £; У, - фактическое значение уровня на период 1
5, 1 - сглаженное значение на период Ь-Ьг-
сглаженное значение тренда на период 1
- сглаженное значение на период I-
1; А
и В - сглаживающие константы (числа между 0 и 1). Сглаживающие константы А и В
характеризуют фактор взвешивания наблюдений. Обычно Л, В <
0,3. Так как (1 - А) <
1, (1 - В) <
1, то они убывают по экспоненциальному закону по мере удаления наблюдения от текущего периода I.
Отсюда данная процедура получила название экспоненциально сглаживания. Уравнение добавляется в общую процедуру для сглаживания тренда. Каждая новая оценка тренда получается как взвешенная сумма разности между последними двумя сглаженными значениями (текущая оценка тренда) и предыдущей сглаженной оценки. Данное уравнение позволяет существенно сократить влияние случайных возмущений на тренд с течением времени. Прогнозирование с использованием экспоненциального сглаживания подобно процедуре "наивного" прогнозирования, когда прогнозная оценка на завтра полагается равной сегодняшнему значению. В данном случае в качестве прогноза на один период вперед рассматривается сглаженная величина на текущий период плюс текущее сглаженное значение тренда: Данную процедуру можно использовать для прогнозирования на любое число периодов, на пример на т
периодов: Процедура прогнозирования начинается с того, что сглаженная величина 51 полагается равной первому наблюдению У, т.е. 5, = У,. Возникает проблема определения начального значения тренда 6]. Существуют два способа оценки Ьх.
Способ 1.
Положим Ьх
= 0. Такой подход хорошо работает в случае длинного исходного временного ряда. Тогда сглаженный тренд за небольшое число периодов приблизится к фактическому значению тренда. Способ 2.
Можно получить более точную оценку 6, используя первые пять (или более) наблюдений временного ряда. На их основе гю методу наименьших квадратов решается уравнение У(= а + Ь
х г. Величина Ь
берется в качестве начального значения тренда.


Формула расчета метода экспоненциального сглаживания в Excel

График экспоненциального сглаживания








