Экспоненциальное сглаживание - способ сглаживания временных рядов, вычислительная процедура которого включает обработку всех предыдущих наблюдений, при этом учитывается устаревание информации по мере удаления от прогнозного периода. Иначе говоря, чем "старше" наблюдение, тем меньше оно должно влиять на величину прогнозной оценки. Идея экспоненциального сглаживания состоит в том, что по мере "старения" соответствующим наблюдениям придаются убывающие веса.
Данный метод прогнозирования считается весьма эффективным и падежным. Основные достоинства метода состоят в возможности учета весов исходной информации, в простоте вычислительных операций, в гибкости описания различных динамик процессов. Метод экспоненциального сглаживания дает возможность получить оценку параметров тренда, характеризующих не средний уровень процесса, а тенденцию, сложившуюся к моменту последнего наблюдения. Наибольшее применение метод нашел для реализации среднесрочных прогнозов. Для метода экспоненциального сглаживания основным моментом является выбор параметра сглаживания (сглаживающей константы) и начальных условий.
Простое экспоненциальное сглаживание временных рядов, содержащих тренд, приводит к систематической ошибке, связанной с отставанием сглаженных значений от фактических уровней временного ряда. Для учета тренда в нестационарных рядах применяется специальное двухпараметрическое линейное экспоненциальное сглаживание. В отличие от простого экспоненциального сглаживания с одной сглаживающей константой (параметром) данная процедура сглаживает одновременно случайные возмущения и тренд с использованием двух различных констант (параметров). Двухпараметрический метод сглаживания (метод Хольта) включает два уравнения. Первое предназначено для сглаживания наблюденных значений, а второе -для сглаживания тренда:
где I - 2, 3, 4 - периоды сглаживания; 5, - сглаженная величина на период £; У, - фактическое значение уровня на период 1 5, 1 - сглаженное значение на период Ь-Ьг- сглаженное значение тренда на период 1 - сглаженное значение на период I- 1; А и В - сглаживающие константы (числа между 0 и 1).
Сглаживающие константы А и В характеризуют фактор взвешивания наблюдений. Обычно Л, В < 0,3. Так как (1 - А) < 1, (1 - В) < 1, то они убывают по экспоненциальному закону по мере удаления наблюдения от текущего периода I. Отсюда данная процедура получила название экспоненциально сглаживания.
Уравнение добавляется в общую процедуру для сглаживания тренда. Каждая новая оценка тренда получается как взвешенная сумма разности между последними двумя сглаженными значениями (текущая оценка тренда) и предыдущей сглаженной оценки. Данное уравнение позволяет существенно сократить влияние случайных возмущений на тренд с течением времени.
Прогнозирование с использованием экспоненциального сглаживания подобно процедуре "наивного" прогнозирования, когда прогнозная оценка на завтра полагается равной сегодняшнему значению. В данном случае в качестве прогноза на один период вперед рассматривается сглаженная величина на текущий период плюс текущее сглаженное значение тренда:
Данную процедуру можно использовать для прогнозирования на любое число периодов, на пример на т периодов:
Процедура прогнозирования начинается с того, что сглаженная величина 51 полагается равной первому наблюдению У, т.е. 5, = У,.
Возникает проблема определения начального значения тренда 6]. Существуют два способа оценки Ьх.
Способ 1. Положим Ьх = 0. Такой подход хорошо работает в случае длинного исходного временного ряда. Тогда сглаженный тренд за небольшое число периодов приблизится к фактическому значению тренда.
Способ 2. Можно получить более точную оценку 6, используя первые пять (или более) наблюдений временного ряда. На их основе гю методу наименьших квадратов решается уравнение У(= а + Ь х г. Величина Ь берется в качестве начального значения тренда.
Простая и логически ясная модель временного ряда имеет следующий вид:
где b - константа, а ε - случайная ошибка. Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения значения b из данных состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред- предпоследним, и т.д. Простое экспоненциальное сглаживание именно так и построено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не только те, которые попали в определенное окно. Точная формула простого экспоненциального сглаживания имеет вид:
Когда эта формула применяется рекурсивно, каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра α . Если α равен 1, то предыдущие наблюдения полностью игнорируются. Если а равен 0, то игнорируются текущие наблюдения. Значения α между 0 и 1 дают промежуточные результаты. Эмпирические исследования показали, что простое экспоненциальное сглаживание весьма часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать α меньше 0,30. Однако выбор а больше 0,30 иногда дает более точный прогноз. Это значит, что лучше все же оценивать оптимальное значение α по реальным данным, чем использовать общие рекомендации.
На практике оптимальный параметр сглаживания часто ищется с использованием процедуры поиска на сетке. Возможный диапазон значений параметра разбивается сеткой с определенным шагом. Например, рассматривается сетка значений от α =0,1 до α = 0,9 с шагом 0,1. Затем выбирается такое значение α , для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
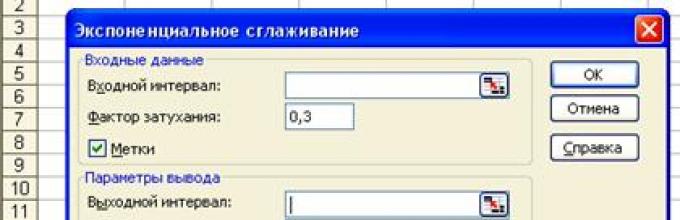
Microsoft Excel располагает функцией Экспоненциальное сглаживание (Exponential Smoothing), которая обычно используется для сглаживания уровней эмпирического временного ряда на основе метода простого экспоненциального сглаживания. Для вызова этой функции необходимо на панели меню выбрать команду Tools - Data Analysis. На экране раскроется окно Data Analysis, в котором следует выбрать значение Экспоненциальное сглаживание. В результате появится диалоговое окно Экспоненциальное сглаживание , представленное на рис. 11.5.

В диалоговом окне Exponential Smoothing задаются практически те же параметры, го и в рассмотренном выше диалоговом окне Moving Average.
1. Input Range (Входные данные) - в это поле вводится диапазон ячеек, содержащих значения исследуемого параметра.
2. Labels (Метки) - данный флажок опции устанавливается в том случае, если первая строка (столбец) во входном диапазоне содержит заголовок. Если заголовок отсутствует, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. Damping factor (Фактор затухания) - в это поле вводится значение выбранного коэффициента экспоненциального сглаживания α . По умолчанию принимается значение α = 0,3.
4. Output options (Параметры вывода) - в этой группе, помимо указания диапазона ячеек для выходных данных в поле Output Range (Выходной диапазон), можно также потребовать автоматически построить график, для чего необходимо установить флажок опции Chart Output (Вывод графика), и рассчитать стандартные погрешности, для чего нужно установить флажок опции Standart Errors (Стандартные погрешности).
Воспользуемся функцией Экспоненциальное сглаживание для повторного решения рассмотренной выше задачи, но уже с помощью метода простого экспоненциального сглаживания. Выбранные значения параметров сглаживания представлены на рис. 11.5. На рис. 11.6 показаны рассчитанные показатели, а на рис. 11.7 - построенные графики.


Сервис позволит провести сглаживание временного ряда y t экспоненциальным методом, т.е. простроить модель Брауна (см. пример).
Инструкция . Укажите количество данных (количество строк), нажмите Далее. Полученное решение сохраняется в файле Word .
Особенность метода экспоненциального сглаживания заключается в том, что в процедуре нахождения сглаженного уровня используются значения только предшествующих уровней ряда, взятые с определенным весом, причем вес уменьшается по мере удаления его от момента времени, для которого определяется сглаженное значение уровня ряда. Если для исходного временного ряда y 1 , y 2 , y 3 ,…, y n соответствующие сглаженные значения уровней обозначить через S t , t = 1,2,...,n , то экспоненциальное сглаживание осуществляется по формуле:S t = (1-α)yt + αS t-1
В некоторых источниках приводится другая формула:
S t = αyt + (1-α)S t-1
Где α - параметр сглаживания (0 В практических задачах обработки экономических временных рядов рекомендуется (необоснованно) выбирать величину параметра сглаживания в интервале от 0.1 до 0.3 . Других точных рекомендаций для выбора оптимальной величины параметра α пока нет. В отдельных случаях предлагается определять величину α исходя их длины сглаживаемого ряда: α = 2/(n+1).
Что касается начального параметра S 0 , то в задачах его берут или равным значению первого уровня ряда у 1 , или равным средней арифметической нескольких первых членов ряда.
Если при подходе к правому концу временного ряда сглаженные этим методом значения при выбранном параметре α начинают значительно отличаться от соответствующих значений исходного ряда, необходимо перейти на другой параметр сглаживания. Достоинством этого метода является то, что при сглаживании не теряются ни начальные, ни конечные уровни сглаживаемого временного ряда.
Сглаживание экспоненциальным методом в Excel
Для вычисления каждого прогноза MS Excel использует отдельную, но алгебраически эквивалентную формулу. Оба компонента – данные предыдущего наблюдения и предыдущий прогноз – каждого прогноза умножаются на коэффициент, отображающий вклад данного компонента в текущий прогноз.Активизировать средство Экспоненциальное сглаживание можно, выбрав команду Сервис/Анализ данных после загрузки надстройки Пакет анализа ().
Пример
. Проверить ряд на наличие выбросов методом Ирвина, сгладить методом экспоненциального сглаживания (α = 0.1).
В качестве S 0 берем среднее арифметическое первых 3 значения ряда.
S 0 = (50 + 56 + 46)/3 = 50.67
| t | y | S t | Формула |
| 1 | 50 | 50.07 | (1 - 0.1)*50 + 0.1*50.67 |
| 2 | 56 | 55.41 | (1 - 0.1)*56 + 0.1*50.07 |
| 3 | 46 | 46.94 | (1 - 0.1)*46 + 0.1*55.41 |
| 4 | 48 | 47.89 | (1 - 0.1)*48 + 0.1*46.94 |
| 5 | 49 | 48.89 | (1 - 0.1)*49 + 0.1*47.89 |
| 6 | 46 | 46.29 | (1 - 0.1)*46 + 0.1*48.89 |
| 7 | 48 | 47.83 | (1 - 0.1)*48 + 0.1*46.29 |
| 8 | 47 | 47.08 | (1 - 0.1)*47 + 0.1*47.83 |
| 9 | 47 | 47.01 | (1 - 0.1)*47 + 0.1*47.08 |
| 10 | 49 | 48.8 | (1 - 0.1)*49 + 0.1*47.01 |
Скользящая средняя позволяет прекрасно сглаживать данные. Но ее главный недостаток заключатся в том, что каждое значение в исходных данных для нее имеет одинаковый вес. Например, для средней скользящей использующей период шести недель каждому значению для каждой недели уделяется 1/6 веса. В случае некоторых собранных статистических данных более актуальным значениям присваивается больший вес. Поэтому экспоненциальное сглаживание применятся для того, чтобы придать самым актуальным данным большего веса. Таким образом решается данная статистическая проблема.
Формула расчета метода экспоненциального сглаживания в Excel
Ниже на рисунке изображен отчет спроса на определенный продукт за 26 недель. Столбец «Спрос» содержит информацию о количестве проданного товара. В столбце «Прогноз» – формула:
В столбце «Скользящая средняя» определяется прогнозируемый спрос, рассчитанный с помощью обычного вычисления скользящей средней с периодом 6 недель:

В последнем столбце «Прогноз», с описанной выше формулой применяется метод экспоненциального сглаживания данных в которых значения последних недель имеет больший вес чем предыдущих.
Коэффициент «Альфа:» вводится в ячейке G1, он значит вес присвоения наиболее актуальным данным. В данном примере он имеет значение 30%. Остальные 70% веса распределяется на остальные данные. То есть второе значение с точки зрения актуальности (с право на лево) имеет вес равный 30% от оставшихся 70% веса – это 21%, третье значение имеет вес равен 30% от остальной части 70% веса – 14,7% и так далее.
График экспоненциального сглаживания
Ниже на рисунке изображен график спроса, среднее скользящие и прогноз методом экспоненциального сглаживания, который построен на основе исходных значений:

Обратите внимание, что прогноз с экспоненциальным сглаживанием более активно реагирует на изменения спроса чем скользящая средняя линия.
Данные для очередных предыдущих недель умножаются на коэффициент альфа, а результат добавляется к оставшейся части процентов веса умноженный на предыдущее прогнозируемое значение.
02.04.2011 – Стремление человека приподнять завесу грядущего и предвидеть ход событий имеет такую же длинную историю, как и его попытки, понять окружающий мир. Очевидно, что в основе интереса к прогнозу лежат достаточно сильные жизненные мотивы (теоретические и практические). Прогноз выступает в качестве важнейшего метода проверки научных теорий и гипотез. Способность предвидеть будущее является неотъемлемой стороной сознания, без которой была бы невозможна сама человеческая жизнь.
Понятие “прогнозирование” (от греч. prognosis – предвидение, предсказание) означает процесс разработки вероятностного суждения о состоянии какого-либо явления или процесса в будущем, это познание того, чего еще нет, но что может наступить в ближайшее или отдаленное время.
Прогноз по своему содержанию более сложен, чем предсказание. Он, с одной стороны, отражает наиболее вероятное состояние объекта, а с другой – определяет пути и средства достижения желаемого результата. На основе полученной прогнозным путем информации по достижению желаемой цели, принимаются определенные решения.
Необходимо отметить, что динамика экономических процессов в современных условиях отличается нестабильностью и неопределенностью, что затрудняет применение традиционных методов прогнозирования.
Модели экспоненциального сглаживания и прогнозирования относятся к классу адаптивных методов прогнозирования, основной характеристикой которых является способность непрерывно учитывать эволюцию динамических характеристик изучаемых процессов, подстраиваться под эту динамику, придавая, в частности, тем больший вес и тем более высокую информационную ценность имеющимся наблюдениям, чем ближе они расположены к текущему моменту времени. Смысл термина состоит в том, что адаптивное прогнозирование позволяет обновлять прогнозы с минимальной задержкой и с помощью относительно несложных математических процедур.
Метод экспоненциального сглаживания был независимо открыт Брауном (Brown R.G. Statistical forecasting for inventory control, 1959) и Хольтом (Holt C.C. Forecasting Seasonal and Trends by Exponentially Weighted Moving Averages, 1957). Экспоненциальное сглаживание, как и метод скользящих средних, для прогноза использует прошлые значения временного ряда.
Сущность метода экспоненциального сглаживания заключается в том, что временной ряд сглаживается с помощью взвешенной скользящей средней, в которой веса подчиняются экспоненциальному закону. Взвешенная скользящая средняя с экспоненциально распределенными весами характеризует значение процесса на конце интервала сглаживания, то есть является средней характеристикой последних уровней ряда. Именно это свойство и используется для прогнозирования.
Обычное экспоненциальное сглаживание применяется в случае отсутствия в данных тренда или сезонности. В этом случае прогноз является взвешенной средней всех доступных предыдущих значений ряда; веса при этом со временем геометрически убывают по мере продвижения в прошлое (назад). Поэтому (в отличие от метода скользящего среднего) здесь нет точки, на которой веса обрываются, то есть зануляются. Прагматически ясная модель простого экспоненциального сглаживания может быть записана следующим (по представленной ссылке можно скачать все формулы статьи):
Покажем экспоненциальный характер убывания весов значений временного ряда – от текущего к предыдущему, от предыдущего к пред–предыдущему и так далее:
Если формула применяется
рекурсивно, то каждое новое сглаженное значение (которое является также
прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного
ряда. Очевидно, что результат сглаживания зависит от параметра адаптации альфа
.
Его можно интерпретировать как коэффициент дисконтирования, характеризующий
меру девальвации данных за единицу времени. Причем влияние данных на прогноз
экспоненциально убывает с “возрастом” данных. Зависимость влияния данных на
прогноз при разных коэффициентах альфа
приведена на рисунке 1.

Рисунок 1. Зависимость влияния данных на прогноз при разных коэффициентах адаптации
Следует заметить, что значение сглаживающего параметра не может равняться 0 или 1, так как в этом случае сама идея экспоненциального сглаживания отвергается. Так, если альфа равняется 1, то прогнозное значение F t+1 совпадает с текущим значением ряда Хt , при этом экспоненциальная модель стремится к самой простой “наивной” модели, то есть в этом случае прогнозирование является абсолютно тривиальным процессом. Если альфа равняется 0, то начальное прогнозное значение F 0 (initial value ) одновременно будет являться прогнозом для всех последующих моментов ряда, то есть прогноз в этом случае будет выглядеть в виде обычной горизонтальной линии.
Тем не менее, рассмотрим варианты сглаживающего параметра, близкие к 1 или 0. Так, если альфа близко к 1, то предыдущие наблюдения временного ряда практически полностью игнорируются. В случае если альфа близко к 0, то игнорируются уже текущие наблюдения. Значения альфа между 0 и 1 дают промежуточные результаты. По мнению ряда авторов, оптимальное значение альфа находится в пределах от 0,05 до 0,30. Однако иногда альфа , большее 0,30, дает лучший прогноз.
В целом лучше оценивать оптимальное альфа по исходным данным (при помощи поиска по сетке), а не использовать искусственные рекомендации. Тем не менее, в случае если значение альфа , превышающее 0,3, минимизирует ряд специальных критериев, то это указывает на то, что другая техника прогнозирования (с применением тренда или сезонности) способна обеспечить еще более точные результаты. Для нахождения оптимального значения альфа (то есть минимизации специальных критериев) используется квазиньютоновский алгоритм максимизации правдоподобия (вероятности), который эффективнее обычного перебора на сетке.
Перепишем уравнение (1) в виде альтернативного варианта, позволяющего оценить, как модель экспоненциального сглаживания “обучается” на своих прошлых ошибках:
Из уравнения (3) ярко видно, что прогноз на период t+1 подлежит изменению в сторону увеличения, в случае превышения фактического значения временного ряда в период t над прогнозным значением, и, наоборот, прогноз на период t+1 должен быть уменьшен, если Х t меньше, чем F t .
Отметим, что при использовании методов экспоненциального сглаживания важным вопросом всегда является определение начальных условий (начального прогнозного значения F 0 ). Процесс выбора начального значения сглаженного ряда называется инициализацией (initializing ), или, иначе, “разогревом” (“warming up ”) модели. Дело в том, что начальное значение сглаженного процесса может существенным образом повлиять на прогноз для последующих наблюдений. С другой стороны, влияние выбора уменьшается с длиной ряда и становится некритичным при очень большом числе наблюдений. Браун впервые предложил использовать в качестве стартового значения среднее динамического ряда. Другие авторы предлагают использовать в качестве начального прогноза первое фактическое значение временного ряда.
В середине прошлого века Хольт предложил расширить модель простого экспоненциального сглаживания за счет включения в нее фактора роста (growth factor ), или иначе тренда (trend factor ). В результате модель Хольта может быть записана следующим образом:
Данный метод позволяет учесть присутствие в данных линейного тренда. Позднее были предложены другие виды трендов: экспоненциальный, демпфированный и др.
Винтерс предложил усовершенствовать модель Хольта с точки зрения возможности описания влияния сезонных факторов (Winters P.R. Forecasting Sales by Exponentially Weighted Moving Averages, 1960).
В частности, он далее расширил модель Хольта за счет включения в нее дополнительного уравнения, описывающего поведение сезонной компоненты (составляющей). Система уравнений модели Винтерса выглядит следующим образом:
Дробь в первом уравнении служит для исключения сезонности из исходного ряда. После исключения сезонности (по методу сезонной декомпозиции Census I ) алгоритм работает с “чистыми” данными, в которых нет сезонных колебаний. Появляются они уже в самом финальном прогнозе (15), когда “чистый” прогноз, посчитанный почти по методу Хольта, умножается на сезонную компоненту (индекс сезонности ).







