Задачей множественной линейной регрессии является построение линейной модели связи между набором непрерывных предикторов и непрерывной зависимой переменной. Часто используется следующее регрессионное уравнение:
Здесь а i - регрессионные коэффициенты, b 0 - свободный член(если он используется), е - член, содержащий ошибку - по поводу него делаются различные предположения, которые, однако, чаще сводятся к нормальности распределения с нулевым вектором мат. ожидания и корреляционной матрицей .
Такой линейной моделью хорошо описываются многие задачи в различных предметных областях, например, экономике, промышленности, медицине. Это происходит потому, что некоторые задачи линейны по своей природе.
Приведем простой пример. Пусть требуется предсказать стоимость прокладки дороги по известным ее параметрам. При этом у нас есть данные о уже проложенных дорогах с указанием протяженности, глубины обсыпки, количества рабочего материала, числе рабочих и так далее.
Ясно, что стоимость дороги в итоге станет равной сумме стоимостей всех этих факторов в отдельности. Потребуется некоторое количество, например, щебня, с известной стоимостью за тонну, некоторое количество асфальта также с известной стоимостью.
Возможно, для прокладки придется вырубать лес, что также приведет к дополнительным затратам. Все это вместе даст стоимость создания дороги.
При этом в модель войдет свободный член, который, например, будет отвечать за организационные расходы (которые примерно одинаковы для всех строительно-монтажных работ данного уровня) или налоговые отчисления.
Ошибка будет включать в себя факторы, которые мы не учли при построении модели (например, погоду при строительстве - ее вообще учесть невозможно).
Пример: множественный регрессионный анализ
Для этого примера будут анализироваться несколько возможных корреляций уровня бедности и степень, которая предсказывает процент семей, находящихся за чертой бедности. Следовательно мы будем считать переменную характерезующую процент семей, находящихся за чертой бедности, - зависимой переменной, а остальные переменные непрерывными предикторами.
Коэффициенты регрессии
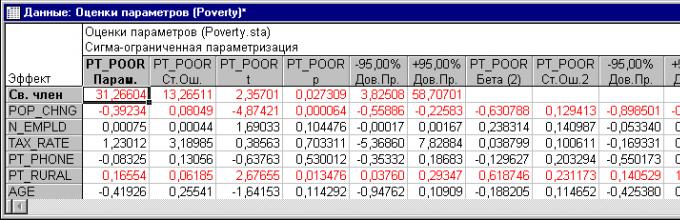
Чтобы узнать, какая из независимых переменных делает больший вклад в предсказание уровня бедности, изучим стандартизованные коэффициенты (или Бета) регрессии.

Рис. 1. Оценки параметров коэффициентов регрессии.
Коэффициенты Бета это коэффициенты, которые вы бы получили, если бы привели все переменные к среднему 0 и стандартному отклонению 1. Следовательно величина этих Бета коэффициентов позволяет сравнивать относительный вклад каждой независимой переменной в зависимую переменную. Как видно из Таблицы, показанной выше, переменные изменения населения с 1960 года (POP_ CHING), процент населения, проживающего в деревне (PT_RURAL) и число людей, занятых в сельском хозяйстве (N_Empld) являются самыми главными предикторами уровня бедности, т.к. только они статистически значимы (их 95% доверительный интервал не включает в себя 0). Коэффициент регрессии изменения населения с 1960 года (Pop_Chng) отрицательный, следовательно, чем меньше возрастает численность населения, тем больше семей, которые живут за чертой бедности в соответствующем округе. Коэффициент регрессии для населения (%), проживающего в деревне (Pt_Rural) положительный, т.е., чем больше процент сельских жителей, тем больше уровень бедности.
Значимость эффектов предиктора
Просмотрим Таблицу с критериями значимости.

Рис. 2. Одновременные результаты для каждой заданной переменной.
Как показывает эта Таблица, статистически значимы только эффекты 2 переменных: изменение населения с 1960 года (Pop_Chng) и процент населения, проживающего в деревне (Pt_Rural), p < .05.
Анализ остатков. После подгонки уравнения регрессии, почти всегда нужно проверять предсказанные значения и остатки. Например, большие выбросы могут сильно исказить результаты и привести к ошибочным выводам.
Построчный график выбросов
Обычно необходимо проверять исходные или стандартизованные остатки на большие выбросы.

Рис. 3. Номера наблюдений и остатки.
Шкала вертикальной оси этого графика отложена по величине сигма, т.е., стандартного отклонения остатков. Если одно или несколько наблюдений не попадают в интервал ± 3 умноженное на сигма, то, возможно, стоит исключить эти наблюдения (это можно легко сделать через условия выбора наблюдений) и еще раз запустить анализ, чтобы убедится, что результаты не изменяются этими выбросами.
Расстояния Махаланобиса
Большинство статистических учебников уделяют много времени выбросам и остаткам относительно зависимой переменной. Тем не менее роль выбросов в предикторах часто остается не выявленной. На стороне переменной предиктора имеется список переменных, которые участвуют с различными весами (коэффициенты регрессии) в предсказании зависимой переменной. Можно считать независимые переменные многомерным пространством, в котором можно отложить любое наблюдение. Например, если у вас есть две независимых переменных с равными коэффициентами регрессии, то можно было бы построить диаграмму рассеяния этих двух переменных и поместить каждое наблюдение на этот график. Потом можно было отметить на этом графике среднее значение и вычислить расстояния от каждого наблюдения до этого среднего (так называемый центр тяжести) в двумерном пространстве. В этом и заключается основная идея вычисления расстояния Махаланобиса . Теперь посмотрим на гистограмму переменной изменения населения с 1960 года.

Рис. 4. Гистограмма распределения расстояний Махаланобиса.
Из графика следует, что есть один выброс на расстояниях Махаланобиса.

Рис. 5. Наблюдаемые, предсказанные и значения остатков.
Обратите внимание на то, что округ Shelby (в первой строке) выделяется на фоне остальных округов. Если посмотреть на исходные данные, то вы обнаружите, что в действительности округ Shelby имеет самое большое число людей, занятых в сельском хозяйстве (переменная N_Empld). Возможно, было бы разумным выразить в процентах, а не в абсолютных числах, и в этом случае расстояние Махаланобиса округа Shelby, вероятно, не будет таким большим на фоне других округов. Очевидно, что округ Shelby является выбросом .
Удаленные остатки
Другой очень важной статистикой, которая позволяет оценить серьезность проблемы выбросов, являются удаленные остатки . Это стандартизованные остатки для соответствующих наблюдений, которые получаются при удалении этого наблюдения из анализа. Помните, что процедура множественной регрессии подгоняет поверхность регрессии таким образом, чтобы показать взаимосвязь между зависимой и переменной и предиктором. Если одно наблюдение является выбросом (как округ Shelby), то существует тенденция к "оттягиванию" поверхности регрессии к этому выбросу. В результате, если соответствующее наблюдение удалить, будет получена другая поверхность (и Бета коэффициенты). Следовательно, если удаленные остатки очень сильно отличаются от стандартизованных остатков, то у вас будет повод считать, что регрессионный анализа серьезно искажен соответствующим наблюдением. В этом примере удаленные остатки для округа Shelby показывают, что это выброс, который серьезно искажает анализ. На диаграмме рассеяния явно виден выброс.

Рис. 6. Исходные остатки и Удаленные остатки переменной, означающей процент семей, проживающих ниже прожиточного минимума.
Большинство из них имеет более или менее ясные интерпретации, тем не менее обратимся к нормальным вероятностным графикам.
Как уже было упомянуто, множественная регрессия предполагает, что существует линейная взаимосвязь между переменными в уравнении и нормальное распределение остатков. Если эти предположения нарушены, то вывод может оказаться неточным. Нормальный вероятностный график остатков укажет вам, имеются ли серьезные нарушения этих предположений или нет.

Рис. 7. Нормальный вероятностный график; Исходные остатки.
Этот график был построен следующим образом. Вначале стандартизованные остатки ранжируюся по порядку. По этим рангам можно вычислить z значения (т.е. стандартные значения нормального распределения) на основе предположения, что данные подчиняются нормальному распределению. Эти z значения откладываются по оси y на графике.
Если наблюдаемые остатки (откладываемые по оси x) нормально распределены, то все значения легли бы на прямую линию на графике. На нашем графике все точки лежат очень близко относительно кривой. Если остатки не являются нормально распределенными, то они отклоняются от этой линии. Выбросы также становятся заметными на этом графике.
Если имеется потеря согласия и кажется, что данные образуют явную кривую (например, в форме буквы S) относительно линии, то зависимую переменную можно преобразовать некоторым способом (например, логарифмическое преобразование для "уменьшения" хвоста распределения и т.д.). Обсуждение этого метода находится за пределами этого примера (Neter, Wasserman, и Kutner, 1985, pp. 134-141, представлено обсуждение преобразований, убирающих ненормальность и нелинейность данных). Однако исследователи очень часто просто проводят анализ напрямую без проверки соответствующих предположений, что ведет к ошибочным выводам.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Количество уволившихся | Зарплата |
||
30000 рублей |
|||
35000 рублей |
|||
40000 рублей |
|||
45000 рублей |
|||
50000 рублей |
|||
55000 рублей |
|||
60000 рублей |
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Множественная регрессия
Под таким термином понимается уравнение связи с несколькими независимыми переменными вида:
y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные).
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)

Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой

Отсюда получаем:

где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:

в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
Задача с использованием уравнения линейной регрессии
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
номер месяца | название месяца | цена товара N |
|
1750 рублей за тонну |
|||
1755 рублей за тонну |
|||
1767 рублей за тонну |
|||
1760 рублей за тонну |
|||
1770 рублей за тонну |
|||
1790 рублей за тонну |
|||
1810 рублей за тонну |
|||
1840 рублей за тонну |
|||
Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
Цена на товар N = 11,714* номер месяца + 1727,54.
или в алгебраических обозначениях
y = 11,714 x + 1727,54
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:

- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
I have a big bookshelf including many books divided in many varieties. On the top shelf are religious books like Fiqh books, Tauhid books, Tasawuf books, Nahwu books, etc. They are lined up neatly in many rows and some of them are lined up neatly according to the writers. On the second level are my studious books like Grammar books, Writing books, TOEFL books, etc. These are arranged based on the sizes. On the next shelf are many kinds of scientific and knowledgeable books; for example, Philosophies, Politics, Histories, etc. There are three levels for these. Eventually, in the bottom of my bookshelf are dictionaries, they are Arabic dictionaries and English dictionaries as well as Indonesian dictionaries. Indeed, there are six levels in my big bookshelf and they are lined up in many rows. The first level includes religious books, the second level includes my studious books, the third level having three levels includes many kinds of scientific and knowledgeable books and the last level includes dictionaries. In short, I love my bookshelf.
Specific-to-general order
The skills needed to write range from making the appropriate graphic marks, through utilizing the resources of the chosen language, to anticipating the reactions of the intended readers. The first skill area involves acquiring a writing system, which may be alphabetic (as in European languages) or nonalphabetic (as in many Asian languages). The second skill area requires selecting the appropriate grammar and vocabulary to form acceptable sentences and then arranging them in paragraphs. Third, writing involves thinking about the purpose of the text to be composed and about its possible effects on the intended readership. One important aspect of this last feature is the choice of a suitable style. Unlike speaking, writing is a complex sociocognitive process that has to be acquired through years of training or schooling. (Swales and Feak, 1994, p. 34)
General-to-specific order
"Working part-time as a cashier at the Piggly Wiggly has given me a great opportunity to observe human behavior. Sometimes I think of the shoppers as white rats in a lab experiment, and the aisles as a maze designed by a psychologist. Most of the rats--customers, I mean--follow a routine pattern, strolling up and down the aisles, checking through my chute, and then escaping through the exit hatch. But not everyone is so dependable. My research has revealed three distinct types of abnormal customer: the amnesiac, the super shopper, and the dawdler. . ."
There are many factors that contribute to student success in college. The first factor is having a goal in mind before establishing a course of study. The goal may be as general as wanting to better educate oneself for the future. A more specific goal would be to earn a teaching credential. A second factor related to student success is self-motivation and commitment. A student who wants to succeed and works towards this desire will find success easily as a college student. A third factor linked to student success is using college services. Most beginning college students fail to realize how important it can be to see a counselor or consult with a librarian or financial aid officer.
There are three reasons why Canada is one of the best countries in the world. First, Canada has an excellent health care service. All Canadians have access to medical services at a reasonable price. Second, Canada has a high standard of education. Students are taught be well-trained teachers and are encouraged to continue studying at university. Finally, Canada’s cities are clean and efficiently organized. Canadian cities have many parks and lots of space for people to live. As a result, Canada is a desirable place to live.
York was charged by six German soldiers who came at him with fixed bayonets. He drew a bead on the sixth man, fired, and then on the fifth. He worked his way down the line, and before he knew it, the first man was all by himself. York killed him with a single shot.
As he looked around campus, which had hardly changed, he unconsciously relieved those moments he had spent with Nancy. He recalled how the two of them would seat by the pond, chatting endlessly as they fed the fish and also how they would take walks together, lost in their own world. Yes, Nancy was one of the few friends that he had ever had. ….He was suddenly filled with nostalgia as he recalled that afternoon he had bid farewell to Nancy. He sniffed loudly as his eyes filled with tears.
Примеры решения задач по множественной регрессии
Пример 1. Уравнение регрессии, построенное по 17 наблюдениям, имеет вид:
Расставить пропущенные значения, а также построить доверительный интервал для b 2 с вероятностью 0,99.
Решение. Пропущенные значения определяем с помощью формул:


Таким образом, уравнение регрессии со статистическими характеристиками выглядит так:

Доверительный интервал для b 2 строим по соответствующей формуле. Здесь уровень значимости равен 0,01, а число степеней свободы равно n – p – 1 = 17 – 3 – 1 = 13, где n = 17 – объём выборки, p = 3 – число факторов в уравнении регрессии. Отсюда
или . Этот доверительный интервал накрывает истинное значение параметра с вероятностью, равной 0,99.
Пример 2. Уравнение регрессии в стандартизованных переменных выглядит так:
При этом вариации всех переменных равны следующим величинам:
Сравнить факторы по степени влияния на результирующий признак и определить значения частных коэффициентов эластичности.
Решение. Стандартизованные уравнения регрессии позволяют сравнивать факторы по силе их влияния на результат. При этом, чем больше по абсолютной величине коэффициент при стандартизованной переменной, тем сильнее данный фактор влияет на результирующий признак. В рассматриваемом уравнении самое сильное воздействие на результат оказывает фактор х 1 , имеющий коэффициент – 0,82, самое слабое – фактор х 3 с коэффициентом, равным – 0,43.
В линейной модели множественной регрессии обобщающий (средний) коэффициент частной эластичности определяется выражением, в которое входят средние значения переменных и коэффициент при соответствующем факторе уравнения регрессии натурального масштаба. В условиях задачи эти величины не заданы. Поэтому воспользуемся выражениями для вариации по переменным:

Коэффициенты b j связаны со стандартизованными коэффициентами β j соответствующим соотношением, которое подставим в формулу для среднего коэффициента эластичности:
 .
.
При этом знак коэффициента эластичности будет совпадать со знаком β j :
Пример 3. По 32 наблюдениям получены следующие данные:
Определить значения скорректированного коэффициента детерминации, частных коэффициентов эластичности и параметра а .
Решение. Значение скорректированного коэффициента детерминации определим по одному из формул для его вычисления:
Частные коэффициенты эластичности (средние по совокупности) вычисляем по соответствующим формулам:
Поскольку линейное уравнение множественной регрессии выполняется при подстановке в него средних значений всех переменных, определяем параметр а :
Пример 4. По некоторым переменным имеются следующие статистические данные:
Построить уравнение регрессии в стандартизованном и натуральном масштабах.
Решение. Поскольку изначально известны коэффициенты парной корреляции между переменными, начать следует с построения уравнения регрессии в стандартизованном масштабе. Для этого надо решить соответствующую систему нормальных уравнений, которая в случае двух факторов имеет вид:
![]()
или, после подстановки исходных данных:

Решаем эту систему любым способом, получаем: β 1 = 0,3076, β 2 = 0,62.
Запишем уравнение регрессии в стандартизованном масштабе:
Теперь перейдем к уравнению регрессии в натуральном масштабе, для чего используем формулы расчета коэффициентов регрессии через бета-коэффициенты и свойство справедливости уравнения регрессии для средних переменных:

Уравнение регрессии в натуральном масштабе имеет вид:
Пример 5.
При построении линейной множественной регрессии ![]() по 48 измерениям коэффициент детерминации составил 0,578. После исключения факторов х 3
, х 7
и х 8
коэффициент детерминации уменьшился до 0,495. Обоснованно ли было принятое решение об изменении состава влияющих переменных на уровнях значимости 0,1, 0,05 и 0,01?
по 48 измерениям коэффициент детерминации составил 0,578. После исключения факторов х 3
, х 7
и х 8
коэффициент детерминации уменьшился до 0,495. Обоснованно ли было принятое решение об изменении состава влияющих переменных на уровнях значимости 0,1, 0,05 и 0,01?
Решение. Пусть - коэффициент детерминации уравнения регрессии при первоначальном наборе факторов, - коэффициент детерминации после исключения трех факторов. Выдвигаем гипотезы:
![]() ;
; ![]()
Основная гипотеза предполагает, что уменьшение величины было несущественным, и решение об исключении группы факторов было правильным. Альтернативная гипотеза говорит о правильности принятого решения об исключении.
Для проверки нуль – гипотезы используем следующую статистику:
![]() ,
,
где n = 48, p = 10 – первоначальное количество факторов, k = 3 – количество исключаемых факторов. Тогда
Сравним полученное значение с критическим F (α ; 3; 39) на уровнях 0,1; 0,05 и 0,01:
F (0,1; 3; 37) = 2,238;
F (0,05; 3; 37) = 2,86;
F (0,01; 3; 37) = 4,36.
На уровне α = 0,1 F набл > F кр , нуль – гипотеза отвергается, исключение данной группы факторов не оправдано, на уровнях 0,05 0,01 нуль – гипотеза не может быть отвергнута, и исключение факторов можно считать оправданным.
Пример 6 . На основе квартальных данных с 2000 г. по 2004 г. получено уравнение . При этом ESS=110,3, RSS=21,4 (ESS – объясненная СКО, RSS – остаточная СКО). В уравнение были добавлены три фиктивные переменные, соответствующие трем первым кварталам года, и величина ESS увеличилась до 120,2. Присутствует ли сезонность в этом уравнении?
Решение . Это задача на проверку обоснованности включения группы факторов в уравнение множественной регрессии. В первоначальное уравнение с тремя факторами были добавлены три переменные, соответствующие первым трем кварталам года.
Определим коэффициенты детерминации уравнений. Общая СКО определяется как сумма факторной и остаточной СКО:
ТSS = ESS 1 + RSS 1 = 110,3 + 21,4 = 131,7
Проверяем гипотезы . Для проверки нуль – гипотезы используем статистику

Здесь n = 20 (20 кварталов за пять лет – с 2000 г. по 2004 г.), p = 6 (общее количество факторов в уравнении регрессии после включения новых факторов), k = 3 (количество включаемых факторов). Таким образом:
![]()
Определим критические значения статистики Фишера на различных уровнях значимости:

На уровнях значимости 0,1 и 0,05 F набл > F кр , нуль – гипотеза отвергается в пользу альтернативной, и учет сезонности в регрессии является обоснованным (добавление трех новых факторов оправдано), а на уровне 0,01 F набл < F кр , и нуль – гипотеза не может быть отклонена; добавление новых факторов не оправдано, сезонность в регрессии не является существенной.
Пример 7. При анализе данных на гетероскедастичность вся выборка была после упорядочения по одному из факторов разбита на три подвыборки. Затем по результатам трехфакторного регрессионного анализа было определено, что остаточная СКО в первой подвыборке составила 180, а в третьей – 63. Подтверждается ли наличие гетероскедастичности, если объем данных в каждой подвыборке равен 20?
Решение . Рассчитаем–статистику для проверки нуль–гипотезы о гомоскедастичности по тесту Голдфелда–Квандта:
![]() .
.
Найдем критические значения статистики по Фишеру:

Следовательно, на уровнях значимости 0,1 и 0,05 F набл > F кр , и гетероскедастичность имеет место, а на уровне 0,01 F набл < F кр , и гипотезу о гомоскедастичности отклонить нельзя.
Пример 8 . На основе квартальных данных получено уравнение множественной регрессии , для которого ESS = 120,32 и RSS = 41,4. Для этой же модели были раздельно проведены регрессии на основе следующих данных: 1 квартал 1991 г. – 1 квартал 1995 г. и 2 квартал 1995 г. – 4 квартал 1996 г. В этих регрессиях остаточные СКО соответственно составили 22,25 и 12,32. Проверить гипотезу о наличии структурных изменений в выборке.
Решение . Задача о наличии структурных изменений в выборке решается с помощью теста Чоу.
Гипотезы имеют вид: , где s 0 , s 1 и s 2 – остаточные СКО соответственно для единого уравнения по всей выборке и уравнений регрессии двух подвыборок общей выборки. Основная гипотеза отрицает наличие структурных изменений в выборке. Для проверки нуль – гипотезы рассчитывается статистика (n = 24; p = 3):
Поскольку F – статистика меньше единицы, нуль – гипотезу нельзя отклонить ни для какого уровня значимости. Например, для уровня значимости 0,05.
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных.
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды. Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы - руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель - разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию - статистический метод, позволяющий предсказывать значения зависимой переменной Y по значениям независимой переменной X . В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y по значениям нескольких зависимых переменных (Х 1 , Х 2 , …, X k ).
Скачать заметку в формате или , примеры в формате
Виды регрессионных моделей
где ρ 1 – коэффициент автокорреляции; если ρ 1 = 0 (нет автокорреляции), D ≈ 2; если ρ 1 ≈ 1 (положительная автокорреляции), D ≈ 0; если ρ 1 = -1 (отрицательная автокорреляции), D ≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D с критическими теоретическими значениями d L и d U для заданного числа наблюдений n , числа независимых переменных модели k (для простой линейной регрессии k = 1) и уровня значимости α. Если D < d L , гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция); если D > d U , гипотеза не отвергается (то есть автокорреляция отсутствует); если d L < D < d U , нет достаточных оснований для принятия решения. Когда расчётное значение D превышает 2, то с d L и d U сравнивается не сам коэффициент D , а выражение (4 – D ).
Для вычисления статистики Дурбина-Уотсона в Excel обратимся к нижней таблице на рис. 14 Вывод остатка . Числитель в выражении (10) вычисляется с помощью функции =СУММКВРАЗН(массив1;массив2), а знаменатель =СУММКВ(массив) (рис. 16).

Рис. 16. Формулы расчета статистики Дурбина-Уотсона
В нашем примере D = 0,883. Основной вопрос заключается в следующем - какое значение статистики Дурбина-Уотсона следует считать достаточно малым, чтобы сделать вывод о существовании положительной автокорреляции? Необходимо соотнести значение D с критическими значениями (d L и d U ), зависящими от числа наблюдений n и уровня значимости α (рис. 17).

Рис. 17. Критические значения статистики Дурбина-Уотсона (фрагмент таблицы)
Таким образом, в задаче об объеме продаж в магазине, доставляющем товары на дом, существуют одна независимая переменная (k = 1), 15 наблюдений (n = 15) и уровень значимости α = 0,05. Следовательно, d L = 1,08 и d U = 1,36. Поскольку D = 0,883 < d L = 1,08, между остатками существует положительная автокорреляция, метод наименьших квадратов применять нельзя.
Проверка гипотез о наклоне и коэффициенте корреляции
Выше регрессия применялась исключительно для прогнозирования. Для определения коэффициентов регрессии и предсказания значения переменной Y при заданной величине переменной X использовался метод наименьших квадратов. Кроме того, мы рассмотрели среднеквадратичную ошибку оценки и коэффициент смешанной корреляции. Если анализ остатков подтверждает, что условия применимости метода наименьших квадратов не нарушаются, и модель простой линейной регрессии является адекватной, на основе выборочных данных можно утверждать, что между переменными в генеральной совокупности существует линейная зависимость.
Применение t -критерия для наклона. Проверяя, равен ли наклон генеральной совокупности β 1 нулю, можно определить, существует ли статистически значимая зависимость между переменными X и Y . Если эта гипотеза отклоняется, можно утверждать, что между переменными X и Y существует линейная зависимость. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = 0 (нет линейной зависимости), Н1: β 1 ≠ 0 (есть линейная зависимость). По определению t -статистика равна разности между выборочным наклоном и гипотетическим значением наклона генеральной совокупности, деленной на среднеквадратичную ошибку оценки наклона:
(11) t = (b 1 – β 1 ) / S b 1
где b
1
– наклон прямой регрессии по выборочным данным, β1 – гипотетический наклон прямой генеральной совокупности, ![]() , а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
, а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
Проверим, существует ли статистически значимая зависимость между размером магазина и годовым объемом продаж при α = 0,05. t -критерий выводится наряду с другими параметрами при использовании Пакета анализа (опция Регрессия ). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к t-статистике – на рис. 18.
Рис. 18. Результаты применения t
Поскольку число магазинов n = 14 (см. рис.3), критическое значение t -статистики при уровне значимости α = 0,05 можно найти по формуле: t L =СТЬЮДЕНТ.ОБР(0,025;12) = –2,1788, где 0,025 – половина уровня значимости, а 12 = n – 2; t U =СТЬЮДЕНТ.ОБР(0,975;12) = +2,1788.
Поскольку t -статистика = 10,64 > t U = 2,1788 (рис. 19), нулевая гипотеза Н 0 отклоняется. С другой стороны, р -значение для Х = 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н 0 снова отклоняется. Тот факт, что р -значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение F -критерия для наклона. Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F -критерия. Напомним, что F -критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F -критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR , деленной на количество независимых переменных k ), к дисперсии ошибок (MSE = S Y X 2 ).
По определению F -статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F = MSR / MSE , где MSR = SSR / k , MSE = SSE /(n – k – 1), k – количество независимых переменных в регрессионной модели. Тестовая статистика F имеет F -распределение с k и n – k – 1 степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > F U , нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t -критерию F -критерий выводится в таблицу при использовании Пакета анализа (опция Регрессия ). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к F -статистике – на рис. 21.

Рис. 21. Результаты применения F -критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р -значение близко к нулю (ячейка Значимость F ). Если уровень значимости α равен 0,05, определить критическое значение F -распределения с одной и 12 степенями свободы можно по формуле F U =F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F = 113,23 > F U = 4,7472, причем р -значение близко к 0 < 0,05, нулевая гипотеза Н 0 отклоняется, т.е. размер магазина тесно связан с его годовым объемом продаж.

Рис. 22. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, с одной и 12 степенями свободы
Доверительный интервал, содержащий наклон β 1 . Для проверки гипотезы о существовании линейной зависимости между переменными можно построить доверительный интервал, содержащий наклон β 1 и убедиться, что гипотетическое значение β 1 = 0 принадлежит этому интервалу. Центром доверительного интервала, содержащего наклон β 1 , является выборочный наклон b 1 , а его границами - величины b 1 ± t n –2 S b 1
Как показано на рис. 18, b 1 = +1,670, n = 14, S b 1 = 0,157. t 12 =СТЬЮДЕНТ.ОБР(0,975;12) = 2,1788. Следовательно, b 1 ± t n –2 S b 1 = +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342, или + 1,328 ≤ β 1 ≤ +2,012. Таким образом, наклон генеральной совокупности с вероятностью 0,95 лежит в интервале от +1,328 до +2,012 (т.е. от 1 328 000 до 2 012 000 долл.). Поскольку эти величины больше нуля, между годовым объемом продаж и площадью магазина существует статистически значимая линейная зависимость. Если бы доверительный интервал содержал нуль, между переменными не было бы зависимости. Кроме того, доверительный интервал означает, что каждое увеличение площади магазина на 1 000 кв. футов приводит к увеличению среднего объема продаж на величину от 1 328 000 до 2 012 000 долларов.
Использование t -критерия для коэффициента корреляции. был введен коэффициент корреляции r , представляющий собой меру зависимости между двумя числовыми переменными. С его помощью можно установить, существует ли между двумя переменными статистически значимая связь. Обозначим коэффициент корреляции между генеральными совокупностями обеих переменных символом ρ. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0 : ρ = 0 (нет корреляции), Н 1 : ρ ≠ 0 (есть корреляция). Проверка существования корреляции:

где r = + , если b 1 > 0, r = – , если b 1 < 0. Тестовая статистика t имеет t -распределение с n – 2 степенями свободы.
В задаче о сети магазинов Sunflowers r 2 = 0,904, а b 1 - +1,670 (см. рис. 4). Поскольку b 1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t -статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t = 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y и предсказания индивидуальных значений Y при заданных значениях переменной X .
Построение доверительного интервала. В примере 2 (см. выше раздел Метод наименьших квадратов ) регрессионное уравнение позволило предсказать значение переменной Y X . В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика при заданном значении переменной X :
где  , =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
- заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX =
, =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
- заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений X i . Если значение переменной Y предсказывается для величин X , близких к среднему значению , доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения. Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X , часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика Y X = Xi при конкретном значении переменной X i определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел - вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа (кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, - набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х 8 = 19, Y 8 = 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.

Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X и Y всегда начинайте с построения диаграммы разброса.
- Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме. Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t -критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.

Рис. 27. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Материал будет проиллюстрирован сквозным примером: прогнозирование объемов продаж компании OmniPower. Представьте себе, что вы - менеджер по маркетингу в крупной национальной сети бакалейных магазинов. В последние годы на рынке появились питательные батончики, содержащие большое количество жиров, углеводов и калорий. Они позволяют быстро восстановить запасы энергии, потраченной бегунами, альпинистами и другими спортсменами на изнурительных тренировках и соревнованиях. За последние годы объем продаж питательных батончиков резко вырос, и руководство компании OmniPower пришло к выводу, что этот сегмент рынка весьма перспективен. Прежде чем предлагать новый вид батончика на общенациональном рынке, компания хотела бы оценить влияние его стоимости и рекламных затрат на объем продаж. Для маркетингового исследования были отобраны 34 магазина. Вам необходимо создать регрессионную модель, позволяющую проанализировать данные, полученные в ходе исследования. Можно ли применить для этого модель простой линейной регрессии, рассмотренную в предыдущей заметке? Как ее следует изменить?
Модель множественной регрессии
Для маркетингового исследования в компании OmniPower была создана выборка, состоящая из 34 магазинов с приблизительно одинаковыми объемами продаж. Рассмотрим две независимые переменные - цена батончика OmniPower в центах (Х 1 ) и месячный бюджет рекламной кампании, проводимой в магазине, выраженный в долларах (Х 2 ). В этот бюджет входят расходы на оформление вывесок и витрин, а также на раздачу купонов и бесплатных образцов. Зависимая переменная Y представляет собой количество батончиков OmniPower, проданных за месяц (рис. 1).
Рис. 1. Месячный объем продажа батончиков OmniPower, их цена и расходы на рекламу
Скачать заметку в формате или , примеры в формате
Интерпретация регрессионных коэффициентов. Если в задаче исследуются несколько объясняющих переменных, модель простой линейной регрессии можно расширить, предполагая, что между откликом и каждой из независимых переменных существует линейная зависимость. Например, при наличии k объясняющих переменных модель множественной линейной регрессии принимает вид:
(1) Y i = β 0 + β 1 X 1i + β 2 X 2i + … + β k X ki + ε i
где β 0 - сдвиг, β 1 - наклон прямой Y , зависящей от переменной Х 1 , если переменные Х 2 , Х 3 , … , Х k являются константами, β 2 - наклон прямой Y , зависящей от переменной Х 2 , если переменные Х 1 , Х 3 , … , Х k являются константами, β k - наклон прямой Y , зависящей от переменной Х k , если переменные Х 1 , Х 2 , … , Х k-1 являются константами, ε i Y в i -м наблюдении.
В частности, модель множественной регрессии с двумя объясняющими переменными:
(2) Y i = β 0 + β 1 X 1 i + β 2 X 2 i + ε i
где β 0 - сдвиг, β 1 - наклон прямой Y , зависящей от переменной Х 1 , если переменная Х 2 является константой, β 2 - наклон прямой Y , зависящей от переменной Х 2 , если переменная Х 1 является константой, ε i - случайная ошибка переменной Y в i -м наблюдении.
Сравним эту модель множественной линейной регрессии и модель простой линейной регрессии: Y i = β 0 + β 1 X i + ε i . В модели простой линейной регрессии наклон β 1 Y при изменении значения переменной X на единицу и не учитывает влияние других факторов. В модели множественной регрессии с двумя независимыми переменными (2) наклон β 1 представляет собой изменение среднего значения переменной Y при изменении значения переменной X 1 на единицу с учетом влияния переменной Х 2 . Эта величина называется коэффициентом чистой регрессии (или частной регрессии).
Как и в модели простой линейной регрессии, выборочные регрессионные коэффициенты b 0 , b 1 , и b 2 представляют собой оценки параметров соответствующей генеральной совокупности β 0 , β 1 и β 2 .
Уравнение множественной регрессии с двумя независимыми переменными:
(3) = b 0 + b 1 X 1 i + b 2 X 2 i
Для вычисления коэффициентов регрессии используется метод наименьших квадратов. В Excel можно воспользоваться Пакетом анализа , опцией Регрессия . В отличие от построения линейной регрессии, просто задайте в качестве Входного интервала Х область, включающую все независимые переменные (рис. 2). В нашем примере это $C$1:$D$35.

Рис. 2. Окно Регрессия Пакета анализа Excel
Результаты работы Пакета анализа представлены на рис. 3. Как видим, b 0 = 5 837,52, b 1 = –53,217 и b 2 = 3,163. Следовательно, = 5 837,52 –53,217 X 1 i + 3,163 X 2 i , где Ŷ i - предсказанный объем продаж питательных батончиков OmniPower в i -м магазине (штук), Х 1 i - цена батончика (в центах) в i -м магазине, Х 2i - ежемесячные затраты на рекламу в i -м магазине (в долларах).

Рис. 3. Множественная регрессия исследования объем продажа батончиков OmniPower
Выборочный наклон b 0 равен 5 837,52 и является оценкой среднего количества батончиков OmniPower, проданных за месяц при нулевой цене и отсутствии затрат на рекламу. Поскольку эти условия лишены смысла, в данной ситуации величина наклона b 0 не имеет разумной интерпретации.
Выборочный наклон b 1 равен –53,217. Это значит, что при заданном ежемесячном объеме затрат на рекламу увеличение цены батончика на один цент приведет к снижению ожидаемого объема продаж на 53,217 штук. Аналогично выборочный наклон b 2 , равный 3,613, означает, что при фиксированной цене увеличение ежемесячных рекламных затрат на один доллар сопровождается увеличением ожидаемого объема продаж батончиков на 3,613 шт. Эти оценки позволяют лучше понять влияние цены и рекламы на объем продаж. Например, при фиксированном объеме затрат на рекламу уменьшение цены батончика на 10 центов увеличит объем продаж на 532,173 шт., а при фиксированной цене батончика увеличение рекламных затрат на 100 долл. увеличит объем продаж на 361,31 шт.
Интерпретация наклонов в модели множественной регрессии. Коэффициенты в модели множественной регрессии называются коэффициентами чистой регрессии. Они оценивают среднее изменение отклика Y при изменении величины X на единицу, если все остальные объясняющие переменные «заморожены». Например, в задаче о батончиках OmniPower магазин с фиксированным объемом рекламных затрат за месяц продаст на 53,217 батончика меньше, если увеличит их стоимость на один цент. Возможна еще одна интерпретация этих коэффициентов. Представьте себе одинаковые магазины с одинаковым объемом затрат на рекламу. При уменьшении цены батончика на один цент объем продаж в этих магазинах увеличится на 53,217 батончика. Рассмотрим теперь два магазина, в которых батончики стоят одинаково, но затраты на рекламу отличаются. При увеличении этих затрат на один доллар объем продаж в этих магазинах увеличится на 3,613 штук. Как видим, разумная интерпретация наклонов возможна лишь при определенных ограничениях, наложенных на объясняющие переменные.
Предсказание значений зависимой переменной Y. Выяснив, что накопленные данные позволяют использовать модель множественной регрессии, мы можем прогнозировать ежемесячный объем продаж батончиков OmniPower и построить доверительные интервалы для среднего и предсказанного объемов продаж. Для того чтобы предсказать средний ежемесячный объем продаж батончиков OmniPower по цене 79 центов в магазине, расходующем на рекламу 400 долл. в месяц, следует применить уравнение множественной регрессии: Y = 5 837,53 – 53,2173*79 + 3,6131*400 = 3 079. Следовательно, ожидаемый объем продаж в магазинах, торгующих батончиками OmniPower по цене 79 центов и расходующих на рекламу 400 долл. в месяц, равен 3 079 шт.
Вычислив величину Y и оценив остатки, можно построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика. мы рассмотрели эту процедуру в рамках модели простой линейной регрессии. Однако построение аналогичных оценок для модели множественной регрессии сопряжено с большими вычислительными трудностями и здесь не приводится.
Коэффициент множественной смешанной корреляции. Напомним, что модель регрессии позволяет вычислить коэффициент смешанной корреляции r 2 . Поскольку в модели множественной регрессии существуют по крайней мере две объясняющие переменные, коэффициент множественной смешанной корреляции представляет собой долю вариации переменной Y , объясняемой заданным набором объясняющих переменных:
![]()
где SSR – сумма квадратов регрессии, SST – полная сумма квадратов.
Например, в задаче о продажах батончика OmniPower SSR = 39 472 731, SST = 52 093 677 и k = 2. Таким образом,
Это означает, что 75,8% вариации объемов продаж объясняется изменениями цен и колебаниями объемов затрат на рекламу.
Анализ остатков для модели множественной регрессии
Анализ остатков позволяет определить, можно ли применять модель множественной регрессии с двумя (или более) объясняющими переменными. Как правило, проводят следующие виды анализа остатков:
Первый график (рис. 4а) позволяет проанализировать распределение остатков в зависимости от предсказанных значений . Если величина остатков не зависит от предсказанных значений и принимает как положительные так и отрицательные значения (как в нашем пример), условие линейной зависимости переменной Y от обеих объясняющих переменных выполняется. К сожалению, в Пакете анализа этот график почему-то не создается. Можно в окне Регрессия (см. рис. 2) включить Остатки . Это позволит вывести таблицу с остатками, а уже по ней построить точечный график (рис. 4).

Рис. 4. Зависимость остатков от предсказанного значения
Второй и третий график демонстрируют зависимость остатков от объясняющих переменных. Эти графики могут выявить квадратичный эффект. В этой ситуации необходимо добавить в модель множественной регрессии квадрат объясняющей переменной. Эти графики выводятся Пакетом анализа (см. рис. 2), если включить опцию График остатков (рис. 5).

Рис. 5. Зависимость остатков от цены и затрат на рекламу
Проверка значимости модели множественной регрессии.
Убедившись с помощью анализа остатков, что модель линейной множественной регрессии является адекватной, можно определить, существует ли статистически значимая взаимосвязь между зависимой переменной и набором объясняющих переменных. Поскольку в модель входит несколько объясняющих переменных, нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = β 2 = … = β k = 0 (между откликом и объясняющими переменными нет линейной зависимости), Н 1: существует по крайней мере одно значение β j ≠ 0 (мжду откликом и хотя бы одной объясняющей переменной существует линейная зависимость).
Для проверки нулевой гипотезы применяется F -критерий – тестовая F -статистика равна среднему квадрату, обусловленному регрессией (MSR), деленному на дисперсию ошибок (MSE):
![]()
где F F -распределение с k и n – k – 1 степенями свободы, k – количество независимых переменных в регрессионной модели.
Решающее правило выглядит следующим образом: при уровне значимости α нулевая гипотеза Н 0 отклоняется, если F > F U(k,n – k – 1) , в противном случае гипотеза Н 0 не отклоняется (рис. 6).

Рис. 6. Сводная таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициентов множественной регрессии
Сводная таблица дисперсионного анализа, заполненная с использованием Пакета анализа Excel при решении задачи о продажах батончиков OmniPower, показана на рис. 3 (см. область А10:F14). Если уровень значимости равен 0,05, критическое значение F -распределения с двумя и 31 степенями свободы F U(2,31) = F.ОБР(1-0,05;2;31) = равно 3,305 (рис. 7).

Рис. 7. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости α = 0,05, с 2 и 31 степенями свободы
Как показано на рис. 3, F-статистика равна 48,477 > F U(2,31) = 3,305, а p -значение близко к 0,000 < 0,05. Следовательно, нулевая гипотеза Н 0 отклоняется, и объем продаж линейно связан хотя бы с одной из объясняющих переменных (ценой и/или затратами на рекламу).
Статистические выводы о генеральной совокупности коэффициентов регрессии
Чтобы выявить статистически значимую зависимость между переменными X и Y в модели простой линейной регрессии, была выполнена проверка гипотезы о наклоне. Кроме того, для оценки наклона генеральной совокупности был построен доверительный интервал (см. ).
Проверка гипотез. Для проверки гипотезы, утверждающей, что наклон генеральной совокупности β 1 , в модели простой линейной регрессии равен нулю, используется формула t = (b 1 – β 1)/S b 1 . Ее можно распространить на модель множественной регрессии:

где t – тестовая статистика, имеющая t -распределение с n – k – 1 степенями свободы, b j - наклон переменной х j по отношению к переменной Y , если все остальные объясняющие переменные являются константами, S bj – среднеквадратичная ошибка регрессионного коэффициента b j , k - количество объясняющих переменных в уравнении регрессии, β j - гипотетический наклон генеральной совокупности откликов j -й относительно переменной, когда все остальные переменные фиксированы.
На рис. 3 (нижняя таблица) показаны результаты применения t -критерия (полученные с помощью Пакета анализа ) для каждой из независимых переменных, включенных в регрессионную модель. Таким образом, если необходимо определить, оказывает ли переменная Х 2 (затраты на рекламу) существенное влияние на объем продаж при фиксированной цене батончика OmniPower, формулируются нулевая и альтернативная гипотезы: Н 0: β2 = 0, Н 1: β2 ≠ 0. В соответствии с формулой (6) получаем:
![]()
Если уровень значимости равен 0,05, критическими значениями t -распределения с 31 степенями свободы являются t L = СТЬЮДЕНТ.ОБР(0,025;31) = –2,0395 и t U = СТЬЮДЕНТ.ОБР(0,975;31) = 2,0395 (рис. 8). р -значение =1-СТЬЮДЕНТ.РАСП(5,27;31;ИСТИНА) и близко к 0,0000. На основании одного из неравенств t = 5,27 > 2,0395 или р = 0,0000 < 0,05 нулевая гипотеза Н 0 отклоняется. Следовательно, при фиксированной цене батончика между переменной Х 2 (затраты на рекламу) и объемом продаж существует статистически значимая зависимость. Таким образом, существует чрезвычайно малая вероятность отвергнуть нулевую гипотезу, если между затратами на рекламу и объемами продаж нет линейной зависимости.

Рис. 8. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости α = 0,05, с 31 степенью свободы
Проверка значимости конкретных коэффициентов регрессии фактически представляет собой проверку гипотезы о значимости конкретной переменной, включенной в регрессионную модель наряду с другими. Следовательно, t -критерий для проверки гипотезы о значимости регрессионного коэффициента эквивалентен проверке гипотезы о влиянии каждой из объясняющих переменных.
Доверительные интервалы. Вместо проверки гипотезы о наклоне генеральной совокупности можно оценить значение этого наклона. В модели множественной регрессии для построения доверительного интервала используется формула:
(7) b j ± t n – k –1 S bj
Воспользуемся этой формулой для того, чтобы построить 95%-ный доверительный интервал, содержащий наклон генеральной совокупности β 1 (влияние цены X 1 на объем продаж Y при фиксированном объеме затрат на рекламу Х 2 ). По формуле (7) получаем: b 1 ± t n – k –1 S b 1 . Поскольку b 1 = –53,2173 (см. рис. 3), S b 1 = 6,8522, критическое значение t -статистики при 95%-ном доверительном уровне и 31 степени свободы t n – k –1 =СТЬЮДЕНТ.ОБР(0,975;31) = 2,0395, получаем:
–53,2173 ± 2,0395*6,8522
–53,2173 ± 13,9752
–67,1925 ≤ β 1 ≤ –39,2421
Таким образом, учитывая эффект затрат на рекламу, можно утверждать, что при увеличении цены батончика на один цент объем продаж уменьшается на величину, которая колеблется от 39,2 до 67,2 шт. Существует 95%-ная вероятность, что этот интервал правильно оценивает зависимость между двумя переменными. Поскольку данный доверительный интервал не содержит нуля, можно утверждать, что регрессионный коэффициент β 1 имеет статистически значимое влияние на объем продаж.
Оценка значимости поясняющих переменных в модели множественной регрессии
В модель множественной регрессии следует включать только те объясняющие переменные, которые позволяют точно предсказать значение зависимой переменной. Если какая-либо из объясняющих переменных не соответствует этому требованию, ее нужно удалить из модели. В качестве альтернативного метода, позволяющего оценить вклад объясняющей переменной, как правило, применяется частный F -критерий. Он заключается в оценке изменения суммы квадратов регрессии после включения в модель очередной переменной. Новая переменная включается в модель лишь тогда, когда это приводит к значительному увеличению точности предсказания.
Для того чтобы применить частный F-критерий для решения задачи о продажах батончика OmniPower, необходимо оценить вклад переменной Х 2 (затраты на рекламу) после включения в модель переменной X 1 (цена батончика). Если в модель входят несколько поясняющих переменных, вклад объясняющей переменной х j можно определить, исключив ее из модели и оценив сумму квадратов регрессии (SSR), вычисленную по оставшимся переменным. Если в модель входят две переменные, вклад каждой из них определяется по формулам:
Оценка вклада переменной Х 1 Х 2 :
(8а) SSR(X 1 |Х 2) = SSR(X 1 и Х 2) – SSR(X 2)
Оценка вклада переменной Х 2 при условии, что в модель включена переменная Х 1 :
(8б) SSR(X 2 |Х 1) = SSR(X 1 и Х 2) – SSR(X 1)
Величины SSR(X 2) и SSR(X 1 ) соответственно представляют собой суммы квадратов регрессии, вычисленных только по одной из объясняемых переменных (рис. 9).

Рис. 9. Коэффициенты модели простой линейной регрессии, учитывающей: (а) объем продаж и цену батончика – SSR(X 1) ; (б) объем продаж и затраты на рекламу – SSR(X 2) (получены с помощью Пакета анализа Excel)
Нулевая и альтернативная гипотезы о вкладе переменной Х 1 формулируются следующим образом: Н 0 - включение переменной Х 1 не приводит к значительному увеличению точности модели, в которой учитывается переменная Х 2 ; Н 1 - включение переменной Х 1 приводит к значительному увеличению точности модели, в которой учтена переменная Х 2 . Статистика, положенная в основу частного F -критерия для двух переменных, вычисляется по формуле:

где MSE – дисперсия ошибки (остатка) для двух факторов одновременно. По определению F -статистика имеет F -распределение с одной и n –k–1 степенями свободы.
Итак, SSR(X 2) = 14 915 814 (рис. 9), SSR(X 1 и Х 2) = 39 472 731 (рис. 3, ячейка С12). Следовательно, по формуле (8а) получаем: SSR(X 1 |Х 2) = SSR(X 1 и Х 2) – SSR(X 2) = 39 472 731 – 14 915 814 = 24 556 917. Итак, для SSR(X 1 |Х 2) = 24 556 917 и MSE (X 1 и Х 2) = 407 127 (рис. 3, ячейка D13), используя формулу (9), получаем: F = 24 556 917 / 407 127 = 60,32. Если уровень значимости равен 0,05, то критическое значение F -распределения с одной и 31 степенями свободы =F.ОБР(0,95;1;31) = 4,16 (рис. 10).

Рис. 10. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости, равном 0,05, с одной и 31 степенями свободы
Поскольку вычисленное значение F -статистики больше критического (60,32 > 4,17), гипотеза Н 0 отклоняется, следовательно, учет переменной Х 1 (цены) значительно улучшает модель регрессии, в которую уже включена переменная Х 2 (затраты на рекламу).
Аналогично можно оценить влияние переменной Х 2 (затраты на рекламу) на модель, в которую уже включена переменная Х 1 (цена). Проведите вычисления самостоятельно. Решающее условие приводит к тому, что 27,8 > 4,17, и следовательно, включение переменной Х 2 также приводит к значительному увеличению точности модели, в которой учитывается переменная Х 1 . Итак, включение каждой из переменных повышает точность модели. Следовательно, в модель множественной регрессии необходимо включить обе переменные: и цену, и затраты на рекламу.
Любопытно, что значение t -статистики, вычисленное по формуле (6), и значение частной F -статистики, заданной формулой (9), однозначно взаимосвязаны:
![]()
где а - количество степеней свободы.
Регрессионные модели с фиктивной переменной и эффекты взаимодействия
Обсуждая модели множественной регрессии, мы предполагали, что каждая независимая переменная является числовой. Однако во многих ситуациях в модель необходимо включать категорийные переменные. Например, в задаче о продажах батончиков OmniPower для предсказания среднемесячного объема продаж использовались цена и затраты на рекламу. Кроме этих числовых переменных, можно попытаться учесть в модели расположение товара внутри магазина (например, на витрине или нет). Для того чтобы учесть в регрессионной модели категорийные переменные, следует включить в нее фиктивные переменные. Например, если некая категорийная объясняющая переменная имеет две категории, для их представления достаточно одной фиктивной переменной X d : X d = 0, если наблюдение принадлежит первой категории, X d = 1, если наблюдение принадлежит второй категории.
Для иллюстрации фиктивных переменных рассмотрим модель для предсказания средней оценочной стоимости недвижимости на основе выборки, состоящей из 15 домов. В качестве объясняющих переменных выберем жилую площадь дома (тыс. кв. футов) и наличие камина (рис. 11). Фиктивная переменная Х 2 (наличие камина) определена следующим образом: Х 2 = 0, если камина в доме нет, Х 2 = 1, если в доме есть камин.

Рис. 11. Оценочная стоимость, предсказанная по жилой площади и наличию камина
Предположим, что наклон оценочной стоимости, зависящей от жилой площади, одинаков у домов, имеющих камин и не имеющих его. Тогда модель множественной регрессии выглядит следующим образом:
Y i = β 0 + β 1 X 1i + β 2 X 2i + ε i
где Y i - оценочная стоимость i -гo дома, измеренная в тысячах долларов, β 0 - сдвиг отклика, X 1 i ,- жилая площадь i -гo дома, измеренная в тыс. кв. футов, β 1 - наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной, X 1 i ,- фиктивная переменная, означающая наличие или отсутствие камина, β 1 - наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной β 2 - эффект увеличения оценочной стоимости дома в зависимости от наличия камина при постоянной величине жилой площади, ε i – случайная ошибка оценочной стоимости i -гo дома. Результаты вычисления регрессионой модели представлены на рис. 12.

Рис. 12. Результаты вычисления регрессионой модели для оценочной стоимости домов; получены с помощью Пакета анализа в Excel; для расчета использована таблица, аналогичная рис. 11, с единственным изменением: «Да» заменены единицами, а «Нет» – нулями

В этой модели коэффициенты регрессии интерпретируются следующим образом:
- Если фиктивная переменная имеет постоянное значение, увеличение жилой площади на 1000 кв. футов приводит к увеличению предсказанной средней оценочной стоимости на 16,2 тыс. долл.
- Если жилая площадь постоянна, наличие камина увеличивает среднюю оценочную стоимость дома на 3,9 тыс. долл.
Обратите внимание (рис. 12), t -статистика, соответствующая жилой площади, равна 6,29, а р -значение почти равно нулю. В то же время t -статистика, соответствующая фиктивной переменной, равна 3,1, а p -значение – 0,009. Таким образом, каждая из этих двух переменных вносит существенный вклад в модель, если уровень значимости равен 0,01. Кроме того, коэффициент множественной смешанной корреляции означает, что 81,1% вариации оценочной стоимости объясняется изменчивостью жилой площади дома и наличием камина.
Эффект взаимодействия. Во всех регрессионных моделях, рассмотренных выше, считалось, что влияние отклика на объясняющую переменную является статистически независимым от влияния отклика на другие объясняющие переменные. Если это условие не выполняется, возникает взаимодействие между зависимыми переменными. Например, вполне вероятно, что реклама оказывает большое влияние на объем продаж товаров, имеющих низкую цену. Однако, если цена товара слишком высока, увеличение расходов на рекламу не может существенно повысить объем продаж. В этом случае наблюдается взаимодействие между ценой товара и затратами на его рекламу. Иначе говоря, нельзя делать общих утверждений о зависимости объема продаж от затрат на рекламу. Влияние рекламных расходов на объем продаж зависит от цены. Это влияние учитывается в модели множественной регрессии с помощью эффекта взаимодействия. Для иллюстрации этого понятия вернемся к задаче о стоимости домов.
В разработанной нами регрессионной модели предполагалось, что влияние размера дома на его стоимость не зависит от того, есть ли в доме камин. Иначе говоря, считалось, что наклон оценочной стоимости, зависящей от жилой площади дома, одинаков у домов, имеющих камин и не имеющих его. Если эти наклоны отличаются друг от друга, между размером дома и наличием камина существует взаимодействие.
Проверка гипотезы о равенстве наклонов сводится к оценке вклада, который вносит в модель регрессии произведение объясняющей переменной X 1 и фиктивной переменной Х 2 . Если этот вклад является статистически значимым, исходную модель регрессии применять нельзя. Результаты регрессионного анализа, включающего переменные Х 1 , Х 2 и Х 3 = Х 1 *Х 2 приведены на рис. 13.

Рис. 13. Результаты, полученные с помощью Пакета анализа Excel для регрессионной модели, учитывающей жилую площадь, наличие камина и их взаимодействие
Для того чтобы проверить нулевую гипотезу Н 0: β 3 = 0 и альтернативную гипотезу Н 1: β 3 ≠ 0, используя результаты, приведенные на рис. 13, обратим внимание на то, что t -статистика, соответствующая эффекту взаимодействия переменных, равна 1,48. Поскольку р -значение равно 0,166 > 0,05, нулевая гипотеза не отклоняется. Следовательно, взаимодействие переменных не имеет существенного влияния на модель регрессии, учитывающую жилую площадь и наличие камина.
Резюме. В заметке показано, как менеджер по маркетингу может применять множественный линейный анализ для предсказания объема продаж, зависящего от цены и затрат на рекламу. Рассмотрены различные модели множественной регрессии, включая квадратичные модели, модели с фиктивными переменными и модели с эффектами взаимодействия (рис. 14).

Рис. 14. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 873–936







